論文読んだ:Deep Predictive Coding Networks(Deep PredNet)
Deep Predictive Coding Network(Deep PredNet)とは
ニューラルネットの一種
開発元:CoxLab(http://www.coxlab.org/)
論文:Deep Predictive Coding Networks for Fideo Prediction and Unsupervised Learning
できること:
時系列予測。
論文中では動画を受け取り、次に来るフレームの画像を予測、生成している。
何がすごいか(ochiai主観):
○画像から直接次のフレームを予測している
○次のフレームの画像を生成できる
○大脳新皮質の構造に似ている(階層構造)
○高い階層に抽象的な特徴が自動生成される
○教師なし学習
Deep PredNetの構造
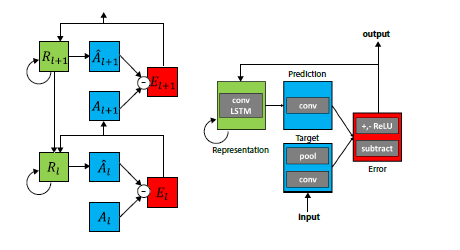
Deep PredNetの構造。右の図は一層分だけ拡大したもの。
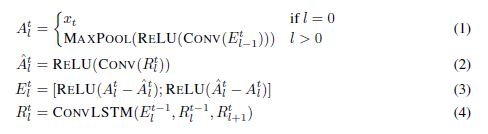
更新式

状態更新のアルゴリズム。トップダウンの信号をすべて更新した後、ボトムアップの信号を更新する。
個々の構成要素はConvlutional NetやLSTMなど近年のDeepLeaningブームでおなじみになったものばかり。それらをうまく組み合わせて、予測と観測を調和させている。
Convoolutional LSTMだけ初耳だったので、調べてみた。
Convolutional LSTMとは
重み(W)と状態変数(小文字)との内積をConvolutionに変更したLSTM。また、状態変数はベクトルからテンソルに変わる。
LSTMの更新式
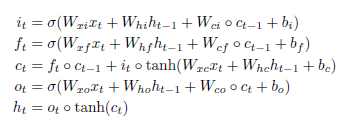
Convolutional LSTMの更新式
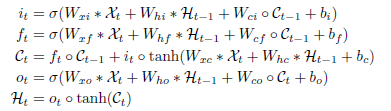
ただし、*は畳み込み、oは要素ごとの積
参考文献:Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting
実験
論文中では、以下の画像に対してフレーム予測を行っている。
実験1:回転する顔の3Dモデルの映像

奇数列が正解画像、偶数列が1フレーム前までの画像から予測、生成した画像。
画像生成の他に、リッジ回帰によって各層の発火頻度から回転方向などの値を推定できるか確認している。上位(深い)層の情報を使ったほうがより精度よく回転方向を推定出来た。このことから、上位層は回転方向などの抽象的な情報を表現していることが分かる。
画像の作成方法
FaceGenというソフトを使用して作成。このソフトは人の顔の3Dスキャンデータの主成分を抽出し、パラメータから顔の3Dデータを作れるようにしたもの。以下のリンクから無料版をダウンロードできる(無料版は額にLogoが入る)
FaceGen(http://facegen.com/modeller_demo.htm)
使用した画像
○白黒画像
○64x64pixcel
○ランダムな初期方向
○ランダムな方向に一定速度で回転
学習パラメータ
○loss:画像が入力されるレイヤーの誤差ニューロン(式(3)のE)の発火頻度を2~10フレームにわたって合計
○レイヤー数:5
○Convolutionのフィルターサイズはすべて3x3
○フィルター数は下層から順に(1、32、64、128、256)
○最適化アルゴリズム:adam
○ライブラリ:theano、Keras
実験2:車載カメラの映像

奇数列が正解画像、偶数列が1フレーム前までの画像から予測、生成した画像。一番下(赤線の下)はフレーム順をシャッフルしてDeep PredNetに見せたもの。

予測した次のフレームを入力として受け取り、複数フレームの予測を行った結果。
画像のソース
以下のデータセットを使用。このデータセットからデータをダウンロードし、解凍するとフレームごとに画像として分割された動画が手に入る。動画はすべて車載カメラからの映像。
KITTI dataset(http://www.cvlibs.net/datasets/kitti/raw_data.php)
使用した画像
128x160pixcelに切り取り(元は1392x512pixcel)
学習パラメータ
○レイヤー数:4
○Convolutionのフィルターサイズはすべて3x3
○フィルター数は下層から順に(3、48、96、192)
○他は恐らく実験1と同じ
感想
予測誤差の扱い方がこのモデルのコアとなるアイディアだと思う。通常のDeepLearninでは発火頻度そのものを上位のレイヤーに渡すが、このモデルでは予測誤差を上位層に渡している。下位層で予測しきれなかった部分を上位層が担当することで抽象的な情報(広い範囲と長い時間を見ないと分からない情報)を抽出しているのだと思う。
また、誤差の表現方法についても、プラス部分とマイナス部分に分割し、入力されたテンソルの2倍のサイズのテンソルを使って表現している。マイナスの部分は符号を反転させプラスにしている。
これは試行錯誤の結果なのか、発火頻度として解釈したときマイナスはありえないためかよくわからない。わざわざこうしているということは、精度に影響があるのではないかと思われる。
