ãŠç–²ã‚Œæ§˜ã§ã™ã€‚
SAM3ã®å®Ÿè¡Œç’°å¢ƒã‚’WSL+Dockerã§ä½œæˆã—ã€å®Ÿéš›ã«å®Ÿè¡Œã—ã¦è©¦ã—ã¦ã¿ãŸè¨˜éŒ²ã§ã™ã€‚
- SAM3ã«ã¤ã„ã¦
ai.meta.com
2025å¹´11月ã«ãƒªãƒªãƒ¼ã‚¹ã•ã‚ŒãŸSAM(Segment Anything Model)シリーズã®æœ€æ–°ãƒ¢ãƒ‡ãƒ«ã§ã™ã€‚ SAM3ã§ã¯ã€ãƒ—ãƒãƒ³ãƒ—トã§ç”»åƒå†…ã®æ¤œå‡ºã—ãŸã„物体を指示ã™ã‚‹ã“ã¨ã§ç›®çš„ã®ç‰©ä½“ã®ã‚»ã‚°ãƒ¡ãƒ³ãƒ†ãƒ¼ã‚·ãƒ§ãƒ³ã¨BBoxã®å‡ºåŠ›ãŒã§ãã¾ã™ã€‚
(他ã«ã‚‚3Dオブジェクトã«å¯¾å¿œã—ãŸSAM3Dã‚‚ã‚ã‚Šã¾ã™ãŒä»Šå›žã¯æ‰±ã„ã¾ã›ã‚“。)
環境構築
- 実行環境
OS: Windows 11 Pro
CPU: Intel Core i7-13700
メモリ: 32GB
GPU: NVIDIA GeForce RTX 4060 Ti (VRAM: 16GB)
環境ã¯ä¸Šè¿°ã®é€šã‚ŠWSL+Dockerを使用ã—ã¾ã—ãŸã€‚ã¾ãŸã€Python環境ã¯uvを使用ã—ã¦ã„ã¾ã™ã€‚
ベースã®ç’°å¢ƒã®ä½œæˆã«ã¤ã„ã¦ã¯éŽåŽ»è¨˜äº‹ã‚’ã”å‚考ãã ã•ã„。
Windows環境ã®å ´åˆã€ä¸€éƒ¨ã®ãƒ©ã‚¤ãƒ–ラリãŒLinuxã§ã—ã‹ä½¿ãˆãšè‡ªå‰ã§ãƒ“ルドã™ã‚‹å¿…è¦ãŒã‚ã‚‹ã®ã§WSLを使ã†æ–¹ãŒè‰¯ã„ã¨æ€ã„ã¾ã™ã€‚
今回使用ã—ãŸç’°å¢ƒè¨å®šã‚’å«ã‚ãŸãƒªãƒã‚¸ãƒˆãƒªã‚’GitHubã«æ®‹ã—ã¦ã„ã¾ã™ã€‚ SAM3ã®å…¬å¼ãƒªãƒã‚¸ãƒˆãƒªã‚’forkã—ã¦ç’°å¢ƒè¨å®šãƒ•ã‚¡ã‚¤ãƒ«ã‚’è¿½åŠ ã—ãŸã®ã¿ã§ã™ãŒâ€¦ã€‚
実行
å…¬å¼ãŒã‚ã’ã¦ã„るデモ用ã®ã‚³ãƒ¼ãƒ‰ã‚’å‚考ã«ä½œæˆã—ãŸä¸‹è¨˜ã®ã‚½ãƒ¼ã‚¹ã‚³ãƒ¼ãƒ‰ã‚’実行ã—ã¾ã—ãŸã€‚
注æ„点ã¨ã—ã¦ã€ãƒ¢ãƒ‡ãƒ«ã®é‡ã¿ã®ãƒ€ã‚¦ãƒ³ãƒãƒ¼ãƒ‰ã«ã¯HuggingFaceã®ãƒ¢ãƒ‡ãƒ«ãƒšãƒ¼ã‚¸ã§åˆ©ç”¨ç”³è«‹ãŒå¿…è¦ã«ãªã‚Šã¾ã™ã€‚
import os from PIL import Image import matplotlib.pyplot as plt from sam3.model_builder import build_sam3_image_model from sam3.model.sam3_image_processor import Sam3Processor from sam3.visualization_utils import plot_results from huggingface_hub import login from dotenv import load_dotenv load_dotenv() login(token=os.getenv("HF_TOKEN")) # モデルã®æº–å‚™ model = build_sam3_image_model() processor = Sam3Processor(model) # ç”»åƒã®èªã¿è¾¼ã¿ image = Image.open("data/1624777685449_985774_photo1.jpeg") inference_state = processor.set_image(image) # テã‚ストプãƒãƒ³ãƒ—トをè¨å®šã—ã¦æŽ¨è«–を実行 output = processor.set_text_prompt(state=inference_state, prompt="tomato") plot_results(image, output) plt.show() plt.close()
上記を実行ã™ã‚‹ã¨ã“ã‚“ãªæ„Ÿã˜ã§å‡ºåŠ›ã•ã‚Œã¾ã™ã€‚
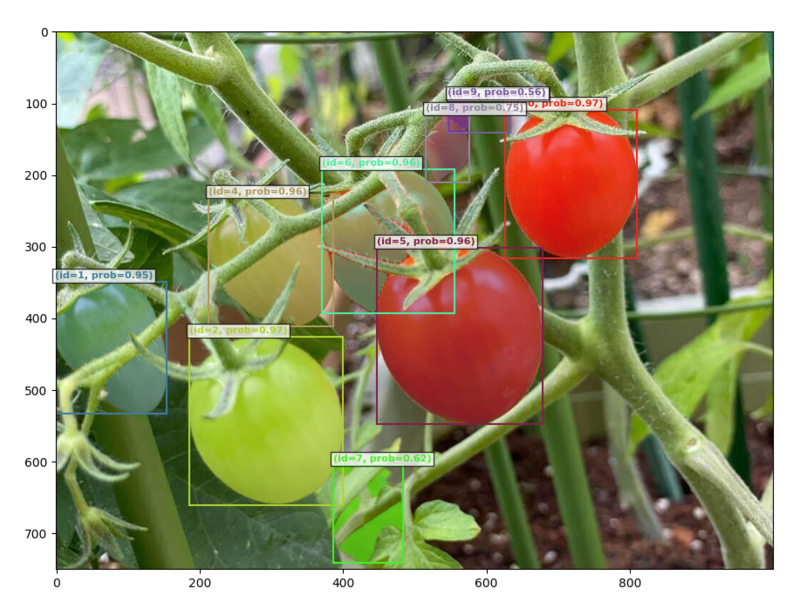
プãƒãƒ³ãƒ—トã®æŒ‡ç¤ºã§ã‚る程度検出ã—ãŸã„物体を絞るã“ã¨ã‚‚å¯èƒ½ã§ã™ã€‚例ãˆã°prompt="red tomato"ã¨å¤‰æ›´ã™ã‚‹ã¨å‡ºåŠ›ãŒå¤‰ã‚ã‚Šã¾ã™ã€‚

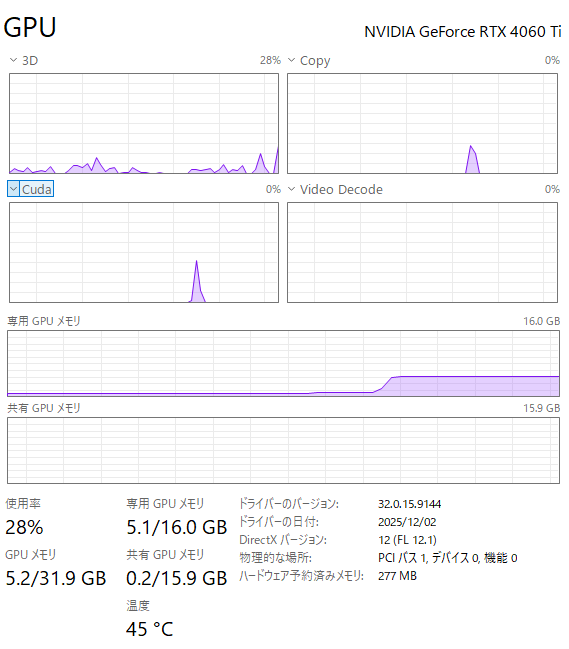
ç§ã®ç’°å¢ƒã§ã®è©±ã«ã¯ãªã‚Šã¾ã™ãŒã€VRAMを大体5GBãらã„使用ã—ã¦ã„ã‚‹ã®ã§æ¯”較的軽ãã†ã§ã™ã€‚
ã¾ãŸã€ç”»åƒ1æžšã‚ãŸã‚Šã®æŽ¨è«–時間ã¯0.20sã»ã©ã ã£ãŸã®ã§ã“ã¡ã‚‰ã‚‚ãªã‹ãªã‹é€Ÿã„ã§ã™ã€‚