
はじめに
タイミーで SRE 業務を担当している徳富(@yannKazu1)です。
日々、数千万件のデータと向き合う中で、Aurora MySQL の運用をより良くするための改善を積み重ねています。
本記事では、その中で経験してきた “机上ではわからないリアルな気づきや学び” を、できるだけ具体的にまとめました。
これから Aurora を本気で運用したい方や、同じような課題に悩んでいる方のヒントになれば嬉しいです。
(この記事はTimee Product Advent Calendar 2025の3日目の記事です。)
1. オンラインDDLでも「ゼロロック」ではない ─ ALTER TABLE 実行時の落とし穴
「MySQL のオンラインDDLなら、日中でもサッと ALTER できるよね?」
──そんなふうに思ってしまうこと、ありますよね。
たしかにオンラインDDLはとても便利で、データをバックグラウンドで再構築してくれるおかげで、テーブル全体を長時間ロックするような事態は起こりにくくなりました。
そのため一見すると “止めずに ALTER できている” ように見えます。
でも実際には、オンラインDDLでも メタデータロック の影響は避けられません。
メタデータロックはテーブル定義の整合性を守るためのロックで、テーブル定義を「読む」「変える」あらゆる操作で取得されます。
たとえば…
SELECT / INSERT / UPDATE / DELETE
→ 共有メタデータロックを取って実行される
ALTER TABLE などの DDL
→ 定義を書き換えるため、より強いメタデータロック(アップグレード可能 / 排他)を要求する
この組み合わせが、ちょっとした“詰まり”の原因になります。
- すでに DML が共有メタデータロックを持っていると →
ALTER TABLEが待たされる - 逆に
ALTER TABLEが排他メタデータロックを握ると → 後続の SELECT / UPDATE が共有メタデータロックを取れずに待つ
「オンラインDDLだから大丈夫」と思っていても、実は “メタデータロック待ち” が発生してクエリが渋滞することは普通に起こるのです。
Aurora レプリカでは「待ち」ではなくエラー になることがある
さらに Aurora MySQL を使っている場合、リードレプリカ上の SELECT クエリが、DDL 実行タイミングでエラーになるという挙動にも注意が必要です。
Vanilla MySQL(RDS MySQL を含む)だと、マスターで ALTER TABLE を実行したとき、
- レプリカ側では SQL スレッドが
metadata lockを取りに行き すでにそのテーブルを使っているクエリがあると
→ それらが終わるまで
Slave_SQL_Running_State: Waiting for table metadata lockの状態で待ち続ける
という形で「レプリカ側にメタデータロック待ちが溜まる」挙動になります。mita2 database life
一方で Aurora レプリカは挙動がかなり違います。
- Aurora の場合、プライマリとレプリカは同じクラスターボリュームを見ており、DDL もほぼ即時にレプリカへ反映される
- その代わり、
- ALTER を打った瞬間
- ALTER 完了直後
に、そのテーブルを読んでいたレプリカ上の SELECT がまとめてエラーになります
(
Lost connection to MySQL server during queryで落ちる挙動が確認されています)。mita2 database life
つまり Aurora では、
- 「レプリカで metadata lock 待ちがズラッと並ぶ」ことは起きにくい
- その代わり、たまたまそのタイミングで流れていた SELECT が「単発で」エラーになる
というトレードオフになっています。mita2 database life
運用で気をつけたいポイント
- オンラインDDLでもメタデータロック が関わる以上、“ゼロロック” にはならない
通常の DML でも共有メタデータロックが付くので、
→ ALTER TABLE と取り合いになって詰まる可能性がある
ロングトランザクションが残っていると、
→
ALTER TABLEがずっと Waiting for table metadata lock のまま動かないAurora の場合は、
- Writer 側では Vanilla MySQL と同様にメタデータロック待ちが発生しうる一方で
- Reader 側ではメタデータロック待ちは溜まらないが、「ALTER の開始/終了タイミングで SELECT がエラーになる」 という特有の挙動がある
- 特にアクセスの多いテーブルほど、
- 夜間に実行する
- 事前にロングトランザクションを掃除する
- レプリカを使った重い SELECT のスケジュールを調整する
といった “ひと手間” が効いてきます。
オンラインDDLは便利な一方で、
「メタデータロックの存在だけは忘れない」
「Aurora レプリカでは SELECT 側の単発エラーとして表に出てくることがある」
という二つを頭の片隅に置いておくと、だいぶ安心して運用できるはずです。
参考にさせていただいた記事
オンラインDDLとメタデータロック の関係や、Aurora レプリカの挙動を整理するうえで、こちらの記事を参考にさせていただきました:
オンラインDDLと メタデータロックの整理にあたって:
Aurora レプリカでの metadata lock と DDL の挙動検証:
2. Migration 時に発生したメタデータロックによるデッドロック
ある日、マイグレーションの最中にデッドロック が発生しました。
通常であれば Aurora の cluster パラメーターでinnodb_print_all_deadlocks を1に設定しているので Aurora がデッドロック検知し、CloudWatch → Firehose → Datadog Logs** の経路でロックモニター情報と共に通知が飛んできます。
ところがその日は、Datadog に何も上がってこない状況でした。
「あれ、Firehose 止まってる? それともロックモニターが出てない?」
CloudWatch の生ログをたどってもロックモニター自体が出力されておらず、そもそも Aurora 側でロックモニターが発火していない状態でした。
ログが出ていない理由
原因はシンプルで、当時発生していたのが InnoDB のロックではなくメタデータロックによるデッドロック だったためです。
ロックモニターが検知しているのは InnoDB ストレージエンジン層の情報であり、
サーバーコア側で管理される メタデータロック はモニターの対象外です。
つまり、今回の競合は InnoDB のロックではなくサーバー側で管理される メタデータロックによるものだったため、InnoDB のロックモニターの対象外で観測されなかったということです。
何が起きていたのか
実行していたのは不要になった customers_ordersテーブルの削除(DROP TABLE customers_orders)。
一方アプリケーション側では、orders と customers を参照する読み取り(JOIN もしくは連続した SELECT) が走っていました。
customers_orders は orders と customers に外部キーを持つため、DROP TABLE customers_orders は参照整合性の確認で orders と customers の排他メタデータロックを取りに行きます。
同時にアプリ側は orders と customers の共有メタデータロックを取りに行くため、取得順序の差で相互待機(メタデータロックによるデッドロック)が成立しました。
再現用のサンプルコード
CREATE TABLE customers ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50) ) ENGINE = InnoDB; INSERT INTO customers (name) VALUES ('Alice'); CREATE TABLE orders ( id INT AUTO_INCREMENT PRIMARY KEY ) ENGINE = InnoDB; INSERT INTO orders VALUES (1); -- 中間テーブル(orders × customers) CREATE TABLE customers_orders ( order_id INT NOT NULL, customer_id INT NOT NULL, PRIMARY KEY (order_id, customer_id), -- 中間テーブルらしく複合主キー FOREIGN KEY (order_id) REFERENCES orders(id), FOREIGN KEY (customer_id) REFERENCES customers(id) ) ENGINE = InnoDB; -- 例: 関連を1件だけ作る INSERT INTO customers_orders (order_id, customer_id) VALUES (1, 1);
次に、2つのプロセスを用意して実行します。
セッション1(アプリケーション側)
START TRANSACTION; SELECT * FROM orders;→
ordersに 共有メタデータロック(読み取りロック) を取得。セッション2(マイグレーション)
DROP TABLE customers_orders;→
customers_ordersに 排他メタデータロック を取得し、外部キー参照を解決するためにcustomersに排他メタデータロックを取得(成功)、ordersに排他メタデータロックを取得しようとして待機。セッション1
SELECT * FROM customers;→
customersに共有メタデータロックを取得しようとするが、プロセス2がすでに排他メタデータロックを保持しているため待機。
この時点で、
- セッション1:
ordersの共有メタデータロックを保持し、customersの共有メタデータロック取得待ち - セッション2:
customersの排他メタデータロックを保持し、ordersの排他メタデータロック取得待ち
という相互待機状態(デッドロック) に陥ります。
SHOW ENGINE INNODB STATUS を実行しても、今回のデッドロックに関する記録は一切表示されません。
これは InnoDB ロックではなくMySQL サーバーコアで管理される メタデータロックによるデッドロックだからです。
再発防止策
DROP TABLE前に外部キー制約を削除しておくALTER TABLE customers_orders DROP FOREIGN KEY fk_customers_orders_order_id; ALTER TABLE customers_orders DROP FOREIGN KEY fk_customers_orders_customer_id; DROP TABLE customers_orders;外部キーを先に削除することで、
DROP TABLE実行時にロック対象となるテーブル(orders、customers)を最小限に抑え、排他メタデータロックの競合リスクを下げることができます。
マイグレーション実行時の同時アクセスを抑制する
特に本番環境では、参照先テーブル(この場合は
ordersとcustomers)に対する DML が走っていないことを確認してから実行することが重要です。
3. リードレプリカのクエリが Writer 側に影響することがある
Aurora MySQL を運用している際に、リードレプリカで実行した SELECT クエリにもかかわらず、Writer 側の RollbackSegmentHistoryListLength が増加していることに気づきました。AWS のサポートに問い合わせたところ、次のような仕組みであることが判明しました。
クラスターボリューム単位で共有される Undo(履歴)
Aurora MySQL では、クラスターボリューム構造においてストレージおよび Undo ログ(履歴)が共有されています。
そのため、RollbackSegmentHistoryListLength に関しても、インスタンス単位ではなく、クラスター/ボリューム単位で管理される仕様です。
リーダーで長時間実行されているトランザクション(たとえ SELECT であっても 分離レベルがREAD COMMITTEDの場合MVCC による過去バージョン追跡が発生)を実行すると、Undo 履歴が溜まり、共有ボリュームを通じて Writer 側にも影響が及ぶ状況が起こり得ます。
つまり、“リーダーだから安心して重めのクエリを流せる”とは限らない、ということになります。
RollbackSegmentHistoryListLength の意味と影響
このメトリクスは、Aurora/MySQL における コミット済みトランザクションの Undo ログ(履歴リスト)の長さを表します。
InnoDB の履歴リストは、コミット済みトランザクションの Undo ログを格納するグローバルリストであり、不要になった履歴(古い行バージョン)を削除するために使用されます。
このリストが長くなるということは、古い行バージョンが多数残っている状態を意味します。
履歴リストの長さが大きくなりすぎると、古い行バージョンを多く保持する必要があるため、クエリの実行が遅くなる可能性があります。また、トランザクション完了後に発生するバックログの伝搬が重くなり、AuroraReplicaLag が一時的に増加する場合があります。このラグ増大の影響が大きいと、リードレプリカ側で再起動が発生する可能性もあります(参考)。
Aurora 公式ドキュメントでも、履歴リストの長さが過剰に増加するとパフォーマンス低下の原因になると説明されています。
(Amazon Aurora User Guide – InnoDB 履歴リストの長さ)
典型的に値が増加する状況としては:
実行時間の長いトランザクション(読み取りまたは書き込み)
→ 長時間オープン状態のトランザクションが存在すると、古い Undo ログがパージできずに履歴リストが蓄積します。
書き込み負荷が高い場合
→ 更新や削除が頻繁に行われると Undo ログが大量に生成され、パージ処理が追いつかず履歴リストの長さが増加します。
実際に起きていたこと(時系列)
- リードレプリカを参照している Redash で実行された集計クエリが数時間実行されていた
- 長時間実行中のトランザクションにより、古い Undo ログをすぐにパージできず、
RollbackSegmentHistoryListLengthが上昇 RollbackSegmentHistoryListLengthの上昇によって、クエリパフォーマンスの低下が発生- トランザクションが完了した際のバックログの伝搬の影響で
AuroraReplicaLagの一時的な増加が発生し、レプリカインスタンスの再起動が発生
対応と再発防止
Redash などリードレプリカ上で実行する長時間の集計クエリは、セッション単位で READ COMMITTED 以下の分離レベルを選ぶことで、過去バージョンを長期間保持してしまう問題を防ぎ、Undo の肥大化を抑えることができます。
分離レベルを下げると、読み取り整合性の保証が弱まるというデメリットがあります。たとえば:
- 同じクエリを2回実行すると結果が変わる可能性がある(Non-repeatable read)
- 範囲検索のたびに新しい行が見えてしまうことがある(Phantom read)
- コミット前の書き込みを読んでしまう可能性がある(Dirty read:ただし
READ UNCOMMITTEDの場合のみ)
ただ、集計系のワークロードではリアルタイムな厳密整合性を求めないケースがほとんどのため、これらの揺らぎは実運用上問題にならないことが多いです。
むしろ「レプリカでの長時間クエリが原因で Writer 側のパフォーマンスに影響が出る」ほうが深刻で、その影響を避けられるメリットのほうが大きい場面が多いです。
4. InnoDB Buffer Pool チューニング
Aurora MySQL のメモリ構成の中で最も大きな割合を占めるのが InnoDB Buffer Pool です。
これは InnoDB ストレージエンジンが、テーブルのデータページやインデックスページをキャッシュするための中核的なメモリ領域です。
クエリ実行時、MySQL はまずバッファプール上に必要なページが存在するかを確認し、見つからない場合のみディスクから読み込みます。
したがって、どの程度のデータをバッファプールに載せられているかが、ディスク I/O の発生頻度やクエリ性能を大きく左右します。
十分なバッファプールを確保しておくことで、ディスクアクセスを最小限に抑え、結果として応答時間やスループットを改善できます。
Aurora では、バッファプールサイズはデフォルトではインスタンスの物理メモリに応じて自動計算されます。
基本的には innodb_buffer_pool_size = DBInstanceClassMemory × 3/4 の式を基準に動的に設定され、インスタンスをスケールアップするとバッファプールも比例して拡張されます。
必要に応じて、パラメーターグループで明示的に調整することも可能です。
このメモリ、本当に使い切れているのか?
運用中の Aurora Writer を確認すると、Buffer pool hit ratio は 99%以上を維持し、Read IOPS や Read Latency も低水準で安定していました。
つまり、ほとんどのクエリがメモリ内で完結しており、ディスク I/O はほとんど発生していない状態です。
一方で、innodb_buffer_pool の使用率は 100% に達していませんでした。
これは単に「メモリを使い切れていない」ということではなく、実際にアクセスされるデータ量(ワーキングセット)がバッファプール容量を下回っていることを意味します。
言い換えれば、ワーキングセットを十分に収容できるだけのバッファプールが確保されているため、まだメモリに余裕がある状態です。
さらに FreeableMemory にも十分な余裕がある場合は、
「実際のアクセスパターンを支えるために必要なデータは十分にメモリに載っている」= メモリ観点ではインスタンスサイズを下げられる可能性がある
と判断できます。
ただし、メモリだけで判断しない
注意すべきは、メモリ指標だけを根拠にスケールダウンを判断するのは危険という点です。
Aurora の性能はメモリだけでなく、CPU・I/O 帯域・接続数・トランザクション並列度といった複数のリソースバランスで成り立っています。
たとえば、メモリには余裕があっても次のようなケースでは注意が必要です。
- CPU 使用率(
CPUUtilization)やロードアベレージ(LoadAverage)が高い - ピーク時間帯に
DBConnectionsが急増している- Aurora では、
max_connectionsが インスタンスメモリ量から自動計算されるため、インスタンスサイズを下げると デフォルトの許容接続数も減少します max_connections自体は調整できますが、AWS ドキュメントにもあるとおり、バッファプールやクエリキャッシュなど他のメモリ関連設定と密接に関係するため、デフォルトから変更するには十分な知識と検証が必要ですデフォルトの接続制限は、バッファプールやクエリのキャッシュといった多くのメモリを消費する他の処理のデフォルト値を使用するシステムに合わせて調整されています。クラスターのこれらの他の設定を変更する場合は、DB インスタンスで使用可能なメモリの増減に応じて接続制限を調整することを検討してください。
- 接続数がピークで伸びる環境では、デフォルト値のままスケールダウンすると予期せぬ接続枯渇が発生するリスクがあります
- Aurora では、
このように、インスタンスサイズの変更は接続数だけでなく、自動計算されるさまざまなパラメーターにも影響します。
そのため、「バッファプールを使い切っていない=すぐに下げて良い」ではありません。
メモリ余剰だけでなく、CPU・I/O・接続数など 他のリソース指標も含めて総合的に評価し、ピーク時の負荷に十分耐えられることを確認してから スケールダウンを検討するのが安全です。
5. 同時リクエストによるデッドロックの実例と考察
アプリケーションで同じ処理がほぼ同時に呼ばれると、データベース内部でロックの取り合いが起き、デッドロックにつながることがあります。ここでは2パターンを紹介します。
タイミーのようにユーザー数が多く、トラフィックが集中する環境では、通常のシステムではほとんど起きないような「同時リクエスト」や「並行更新」が発生することがあります。そのため、こうした競合は理論上の話ではなく、実際の運用でも注意が必要です。
パターン①:ギャップロックによる競合
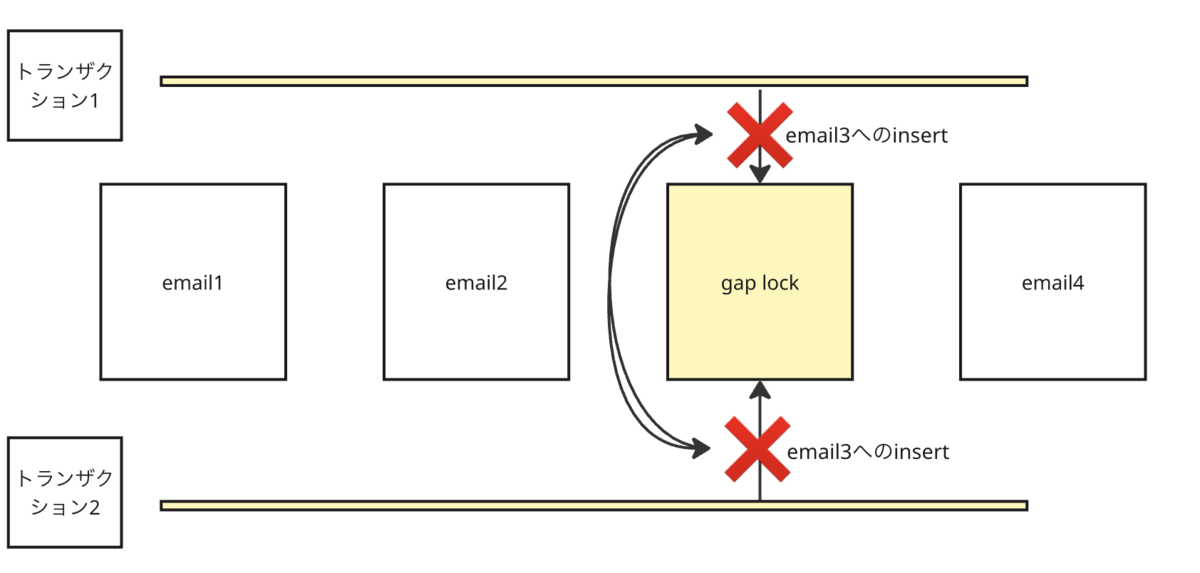
存在しないデータを同時に挿入しようとしたときに発生する典型的なパターンです。
たとえば、「このメールアドレスのレコードが存在しなければ新規作成する」という処理を、複数のリクエストがほぼ同時に実行するケースを考えます。
発生の流れ
ここでは、users テーブルに email = '[email protected]' の行がまだ存在しないケースを例に説明します。
トランザクションA が次のクエリを実行します:
SELECT * FROM users WHERE email = '[email protected]' FOR UPDATE;該当レコードが存在しないため、InnoDB は「
email = '[email protected]'が入る位置のすき間」にギャップロックを取得します。
(このロックは、同じ範囲への
INSERTを防ぐ“見えない壁”のようなものです)ほぼ同時に、トランザクションB も同じクエリを実行します:
SELECT * FROM users WHERE email = '[email protected]' FOR UPDATE;B も同じ範囲にギャップロックを取得します。ここでポイントなのは、ギャップロック同士はお互いに干渉しない(競合しない)ということです。そのため、A と B の
SELECT ... FOR UPDATEはどちらも正常に完了します。
どちらのトランザクションも「対象が存在しない」と判断し、次のように
INSERTを実行します:INSERT INTO users (email, name) VALUES ('[email protected]', 'Alice');しかし、
- トランザクションA のギャップロックがトランザクションBの
INSERTをブロック トランザクションBのギャップロックがトランザクションAの
INSERTをブロックという状態になります。
- トランザクションA のギャップロックがトランザクションBの
互いにロックが解除されるのを待ち続け、デッドロックが発生します。
よくある実装イメージ(rails版)
# 該当レコードが存在しないため、実際の行ロックは発生せず # 「この位置に新しい行を挿入させないためのギャップロック」だけが取得される record = Model.lock.find_by(key: key) record ||= Model.create!(key: key)
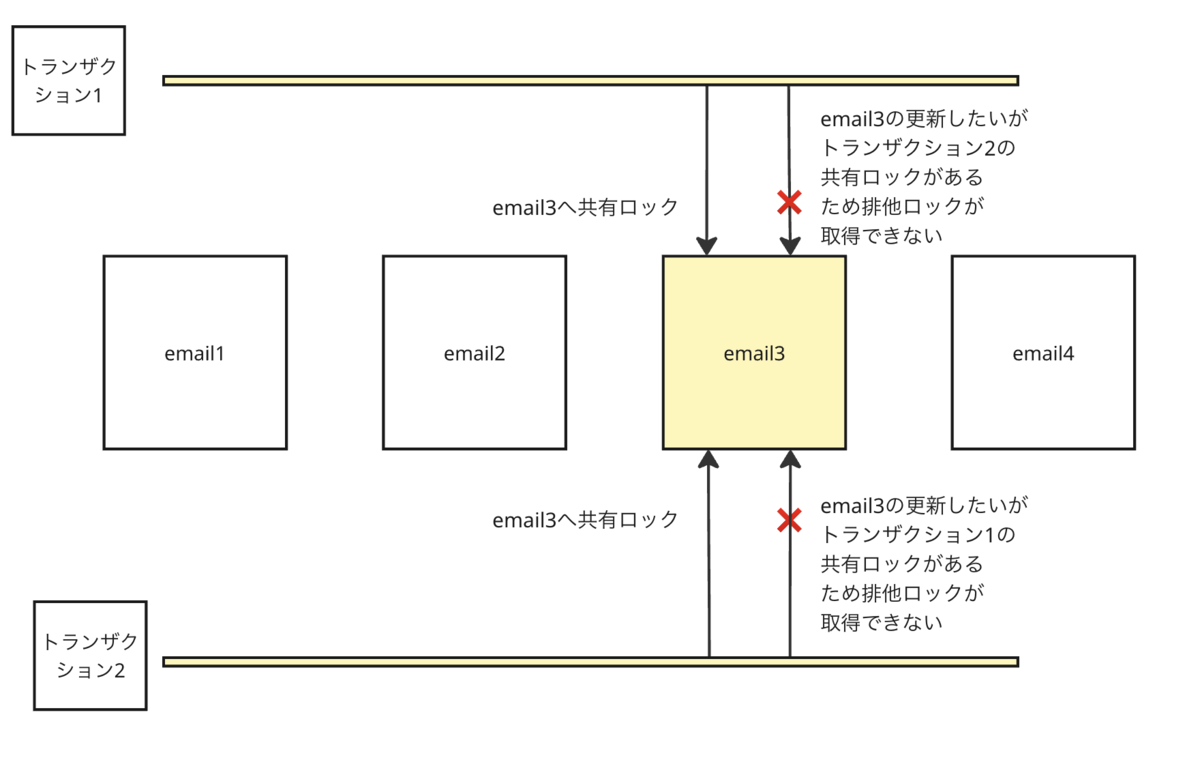
パターン②:ロック昇格による競合
共有ロック(Sロック)から排他ロック(Xロック)へ昇格するときに発生するデッドロックです。
アクセス頻度の高いテーブルで、複数のトランザクションが同じ行を同時に UPDATE しようとしたときに起こりやすい現象です。
発生の流れ
ここでは、email = '[email protected]' の行がすでに存在しているケースを前提に説明します。
トランザクションAが、まず次のクエリを実行します:
SELECT * FROM users WHERE email = '[email protected]' LOCK IN SHARE MODE;→ 該当行に対して共有ロック(Sロック)を取得します。このロックは「読み取り専用」で、他のトランザクションは書き込めませんが、同じ行を読むことは可能です。
ほぼ同時に、トランザクションBも同じクエリを実行します:
SELECT * FROM users WHERE email = '[email protected]' LOCK IN SHARE MODE;→ B も同じ行に対して共有ロック(Sロック)を取得します。
Sロック同士は競合しないため、両方のクエリが問題なく実行されます
その後、A と B の両方が更新クエリを実行します:
UPDATE users SET name = 'Alice' WHERE email = '[email protected]';- A は行を更新するために、Sロックを Xロックに昇格しようとします。
- しかし B が同じ行に Sロックを保持しているため待機状態になります。
- 同時に B も Xロックに昇格しようとしますが、A の Sロックに阻まれて待機。
結果として、お互いのロックが昇格を待ち続ける構図になり、
MySQL がデッドロックを検出して一方のトランザクションを強制終了します。
対策
デッドロックは一見すると予測が難しい現象ですが、ここまで紹介したように 「どのタイミングでどんなロックが取得されているか」 を理解しておくと、多くの場合で事前に回避できます。
たとえば、
存在確認とロック取得の順序を見直す (不要なギャップロックを避ける、レコードの有無によってクエリを分岐する など)
同じ行に対して同時に S→X ロック昇格が起きないようにクエリ設計を調整する
アプリケーション側で同時実行を制御する(排他制御・リトライ・分散ロックなど)
処理の粒度を見直してロック競合が発生しにくい設計にする
といったアプローチがあります。
実際のところ、「これさえやればOK」という万能策はありません。ただ、 「InnoDB がどのタイミングでどのロックを取るか」 を理解しているだけで、 問題を正しく再現でき、適切な対策を選択しやすくなります。
高トラフィック環境ではこうした競合は日常的に起こりうるため、 ロックの性質を知っておくことがトラブルシューティングの大きな助けになります。
6. UPDATE 時にも排他ロック(X)が広範囲に発生する落とし穴
「排他ロック(X ロック)は SELECT ... FOR UPDATE を使ったときだけ発生する」と思われがちですが、実は UPDATE や DELETE でも自動的に X ロックが取得されます。
しかも、ロックされるのは 「更新対象の行だけ」ではありません。
ここで重要なのは、MySQL 公式ドキュメントにあるとおり、
UPDATE / DELETE は「検索で検出された(読み込まれた)すべてのレコード」に 排他的ネクストキーロックを設定する。ただし、一意インデックスによって “1 行だけ” を特定できる場合は、 ギャップを含むネクストキーロックではなく、 対象行そのもののインデックスレコードロックのみで済む。
という点です。
この仕様を踏まえると、MySQL(InnoDB)では、
- 更新 or 削除対象の行に対して排他レコードロック
- その対象を見つけるためにスキャンしたインデックス範囲にも 排他ネクストキーロック(排他レコードロック + ギャップロック)
が自動的に発生します。
つまり、適切なインデックスが存在し、更新時のスキャン範囲をどれだけ絞り込めるかによって、InnoDB が取得するロック範囲は大きく変わります。
具体例:インデックスなし WHERE の UPDATE が大事故を生む
UPDATE orders SET status = 'shipped' WHERE user_id = 123;
orders.user_id にインデックスが無い場合:
- user_id = 123 を見つけるために テーブル全体をスキャン
- スキャン中に「更新候補行」に対して 排他レコードロックを取得
- さらにスキャン範囲に対して排他ネクストキーロックが発生
MySQL 公式が説明する「検索で検出されたすべてのレコードに排他的ネクストキーロックが設定される」状態です。
その結果:
本来 1 ユーザーの数件だけ更新したかったのに、実際にはテーブル全体がロックに巻き込まれる → 他トランザクションの INSERT・UPDATE・DELETE がほぼ止まる
という典型的な事故が起きます。
実務での回避方法
- 適切なインデックスを用意する
- UPDATE / DELETE の WHERE 条件に完全一致するインデックスを作るだけでロック範囲が劇的に狭まる
7. 子テーブル作成・更新・削除時に親テーブルへ伝播する共有ロック(S)
外部キー制約(FOREIGN KEY)が定義されているテーブルでは、子テーブルで行を挿入・更新・削除するときに、参照整合性(FK チェック)を行う必要があります。
このとき、InnoDB は 参照先(=親テーブル)の必要な行を読み込むために共有ロック(S ロック)を取得します。
FOREIGN KEY 制約がテーブル上で定義されている場合は、制約条件をチェックする必要がある挿入、更新、または削除が行われると、制約をチェックするために、参照されるレコード上に共有レコードレベルロックが設定されます。 InnoDB は、制約が失敗する場合に備えて、これらのロックの設定も行います。
ただし S ロックが付くのは「実際に参照整合性チェックが必要になった 親側の行 だけ」です。
- 更新された外部キー列に関係する親テーブルの行
- または、
DELETE/INSERT時に参照される親の行
に対してのみ S ロックが取得されます。
トランザクション+ループ更新で起こりやすい落とし穴
トランザクション内で子テーブルを大量にループ更新するケースでは、
一度取得された親テーブルの S ロックが COMMIT / ROLLBACK まで保持され続けます。
複数行を DELETE / INSERT すると、親テーブル上の複数行に対して S ロックが貼られ、
これらの行に対して X ロック(UPDATE や DELETE)を要求する別トランザクションが 長時間ブロックされることがあります。
具体例:子テーブルの更新(DELETE / INSERT)が親テーブルの UPDATE / DELETE をブロックする
次のようなテーブル構成を考えます。
CREATE TABLE users ( id BIGINT PRIMARY KEY, name VARCHAR(255) NOT NULL ) ENGINE=InnoDB; CREATE TABLE groups ( id BIGINT PRIMARY KEY, name VARCHAR(255) NOT NULL ) ENGINE=InnoDB; CREATE TABLE group_users ( id BIGINT PRIMARY KEY, user_id BIGINT NOT NULL, group_id BIGINT NOT NULL, CONSTRAINT fk_group_users_user FOREIGN KEY (user_id) REFERENCES users(id), CONSTRAINT fk_group_users_group FOREIGN KEY (group_id) REFERENCES groups(id) ) ENGINE=InnoDB;
実際に起きるロックのポイント
この構成では:
user_idはusers.idを参照group_idはgroups.idを参照
ですが、子テーブルの DELETE / INSERT で FK チェックが発生するのは “参照される外部キー列だけ” です。
以下の「グループ移動」処理を考えます:
DELETE FROM group_users WHERE user_id = 123 AND group_id = 1; INSERT INTO group_users (user_id, group_id) VALUES (123, 2);
ここでは、
DELETEによりusers.id = 123,groups.id = 1INSERTによりusers.id = 123,groups.id = 2
が FK チェック対象になるため、
users.id = 123の行に共有ロック(S)groups.id = 1とgroups.id = 2の行にも S ロック
という挙動になります。
問題となるシナリオ:グループ移動バッチとユーザー更新(または退会)API
トランザクション①(グループ移動バッチ)
BEGIN; DELETE FROM group_users WHERE user_id = 123 AND group_id = 1; INSERT INTO group_users (user_id, group_id) VALUES (123, 2); -- COMMITしないまま他の処理が続く(ループで大量のDELETE/INSERT)
この時点で InnoDB は
users.id = 123groups.id = 1groups.id = 2
などの親テーブルの行に S ロックを取得しています。
トランザクション②(別 API からのユーザー更新や退会処理)
BEGIN; UPDATE users SET name = '新しい名前' WHERE id = 123; -- または退会処理 -- DELETE FROM users WHERE id = 123;
UPDATE や DELETE は X ロックを取りたいため、
トランザクション①の S ロックが解除されるまでブロックされます。
この結果、
- バッチ処理は子テーブルだけを操作しているつもり
- しかし参照先(親)テーブルに S ロックを保持し続けている
- 親テーブルの UPDATE / DELETE が待ち状態となり、最悪
Lock wait timeout exceeded
という問題が発生します。
回避・緩和策
バルク更新を細かい単位に分け、途中でこまめに COMMIT する
→ 大量の行を一気に処理すると、その間ずっと親テーブルの行に S ロックを貼り続けてしまいます。
小さなバッチに分割して順番に処理し、適宜 COMMIT することで、
親テーブルのロック保持時間を短くし、ブロックが広がるのを防げます。
おわりに
Aurora MySQL の運用は、単に「パラメーターを調整する」「インスタンスサイズを上げる」といった単発の改善ではなく、
実際にどんな現象が起き、何が原因で、どのレイヤーで発火しているのかを理解しながら積み重ねていく作業です。
タイミーでは、膨大なアクセス量・多様なユースケース・日々進化し続けるサービス構造の中で、運用知識そのものがプロダクトの継続性に直結します。
今回紹介した内容は、その中で得られた知見のごく一部ですが、同じように Aurora を本気で運用している方々にとって、
「あ、これ見落としていたかも」
「うちでもこのパターンあるな」
と思ってもらえるきっかけになれば嬉しいです。
今後も継続的に Aurora / MySQL の検証や改善を進め、実運用で得た知見を積極的に発信していきます。もし似たような事象で悩んでいたり、Aurora をどう設計・運用すべきか議論したい方がいれば、気軽に声をかけてください。
引き続き、より良い運用と学びを積み重ねていきましょう。