2026/5/13: 細かい書き間違えやわかりにくい表現を多数修正した
数ヶ月前に, 2年前のノーベル経済学賞受賞者である Acemoglu らによる「生成AIの使用による人間の知識の崩壊」について論じたワーキングペーパー “AI, Human Cognition and Knowledge Collapse” が公開されていたけど話題になってないので ここで取り上げるのは Acemoglu, Kong, and Ozdaglar (2026) “AI, Human Cognition and Knowledge Collapse” という論文である. 著者の一人であるダロン゠アセモグル (Daron Acemoglu) は, 2024年にノーベル経済学賞を受賞している.2 3 「(生成)AIを使用することは人間の学習行為を『補完』するのか, あるいは『代替』してしまうのか」つまり, 人々の知識や技術の習得を手伝ってくれるのか, あるいは, 自分で学んで判断することをしなくなってしまうのかは, はしばしば話題になり, どちらの主張にも一定のエビデンスがあるため, 人によって意見が分かれるところである. そのため, 著者らはこの論文で, 個人がそれぞれ獲得した知識が社会の一般知識となっていく過程を数理的なモデルで表した. モデルから導き出される結果は, AIは短期的には人間の意思決定を助けるが, 長期的には人間の学習努力の減少によって, 最終的に人類の知的進歩が破綻する, ということだった. この結末へは, 現在の状態にかかわらずかなり強く収束する. 一方で, 人間側が生み出した知識をうまく集約することで, この状態に収束する可能性を減らせるという. よって, AIと共存した場合の人類全体の知識成長が失敗するか成功するかの, 理論上の条件を示したことになる. そのため, この投稿に対して「知ってた」とか「それは使い方次第だろ」とか「やっぱり生成AIは危険だ」とかコメントしてシェアしている人がいたらこの序文の前半すら呼んでない可能性が高いため, 温かい目で見守りつつ, あなたはぜひ最後まで読んでほしい. (さらに言えば, そのようなコメントよりは, 皮肉なことにAIに要約させた文章を読むほうがおそらく有意義だろう. 私の投稿ではなく原文を要約させてもいい.) 非専門家向けにこの論文の立ち位置について補足する. 正確にはこの論文は「ワーキングペーパー」なので, いわゆる査読付き論文ではない. 加えてこの論文は, 「生成AIの普及によって人間の一般知識が劣化していく」という結果を導く経済モデルを考案したという内容であり, この経済モデルが現実の経済を説明しているかどうかまでは踏み込んでいない. 近年の多くの経済学の論文では, 経済の理論モデルを導出し, 現実のデータに当てはめて矛盾しないかどうかを提示するところまでひとまとめになっている内容が多い. もちろん理論モデルを示しただけの研究は机上の空論にすぎないので無価値である, と言うつもりはないが, 近年の学術研究の実態としては, データによる実証まで行っている研究により価値が置かれている. つまりこの論文はいわば, 「仮説」の提示までは行っているが, この仮説が現実に起こっていることを説明できているかどうかの検証にまでは至っていないことに注意する必要がある. この投稿の以降では, 冒頭にタイトルを挙げた論文で導入されているモデルと, そこから引き出された結果を解説する. 証明は省略している. 生成AIあるいはAIエージェントが人間の意思決定, つまり判断にどういう影響を与えるかは, 様々な意見がある. 専門家や研究者にとっては, 情報を集めるために非常に有用なので, 人間の知識を大幅に広げてくれると考えている. 一方で, 現在生成AIは広く普及しており, 専門家や学術研究以外でも使われている. 一方で, 例えば児童が学校で「学び方を学習する」場面や, 職場の新人がその職場で働くための技術を学ぶ場面にAIが介入することに懸念を唱える者もいる. そこで著者らは, 個人の持つ情報が非対称であることを取り入れたモデルで考察を行った. 個人の持つ知識と社会全体の知識は一致せず, 個人レベルの日々の学習は本人にのみ有用な発見と, 社会全体にとっての新発見と, そして社会全体にとっては知識の再発見であるものが入り混じっている. この中で, 社会全体にとっての新しい発見は社会全体で共有され, 将来の経済活動に利用される. 基本モデルでは, エージェントAIは自分自身では新たな知識を生み出さず, 社会全体の知識を個人に提供するだけの純粋な「知識の推薦システム」として機能する. この基本モデルでは, 多くの場合で人々は自分自身で学習することをやめ, エージェントAIの提供する知識だけを頼りにするようになり, 社会全体で新たな知識獲得が途絶える状態に収束してしまうとする. 著者らはこれを「知識の崩壊状態」と呼んでいる. しかしこれは, エージェントAIのあり方を少々戯画化しすぎているように思えるかもしれない. 著者らはさらに, エージェントAIが社会全体の知識形成に貢献するようなメカニズムをモデルに取り入れた場合でも, やはり「知識の崩壊状態」に陥りやすいという結果を示している. 一方で, エージェントAIの出力を適切に規制したり, エージェントAIと人間がうまく協業するようなメカニズムを考えた場合は, 理論上は「知識の崩壊状態」に陥ることを防げることも示している. モデルの設定や, その解き方が複雑なため, この論文のナラティヴを先に紹介しておこう. 著者らは, 社会全体が新しい知識を獲得する過程を個人レベルの探索と, 社会レベルの蓄積の2段階で表現している. 個人レベルでは, 知識の獲得そのものが目的ではなく, 個人がそれぞれの仕事を遂行するために継続的に学習しているような状況を想定しており, 知識の獲得はその副次効果である. 例えば, 児童が学校で勉強することは, その後の人生のためであって勉強のためではない. 職に就いてからも, 新しい技術を取り入れるためだったり, 交渉を効率よく進めるために業界内での力関係を学んだりと, 勉強が必要なことは多いだろう. しかし, 個人が得た知識は社会全体で見れば既に知られていることであったり, 個人的には役に立っても社会全体では役に立たない知識だったりするかもしれないし, 一方でもしかすると社会全体にとって有意義な上に, 誰も知らない新発見だったりもする. この新発見というのは, 製鉄技術とか, 電気とか, 人類史でも特に重要な発明を想像すればよい. 個人がそれぞれ得た知識が集約され, 新しい知識があれば社会の「共通知識」に新たに反映される. すると, 以降は全ての個人が新たに得た共通知識をもとにして知識を蓄積していく, という知識の蓄積メカニズムを数理モデルで表している. これは生成AIが登場する前から共通するメカニズムである. 次に生成AI, 特にエージェントAIの普及に着目する. 現在のエージェントAIの使われ方は, 社会全体の知識蓄積に直接使われているわけではない. 個人がそれぞれ自分自身の知識探索のためにチャットGPTなどのエージェントAIを使用しているのを想像すればよい. 自分以外の人間がチャットGPTを使用してどんな情報を得たかはわからない. よって, 上記の2段階の知識探索モデルにエージェントAIの影響を追加するなら, 個人レベルの探索に, エージェントAIの探索能力が上乗せされるような状況を考える. しかし, エージェントAIと従来的な学習の違いは, コストの有無にある. エージェントAIは質問にすぐ答えてくれるため, それまでと違って情報を得るために時間をかける必要がほとんどないとみなせる. そこで著者らの基本モデルでは, 個人がエージェントAIを使った知識を獲得には費用がかからないと仮定している. しかしながら, ここでのエージェントAIは, 社会全体で既に共有された知識から適切な知識を選んで人間に伝えるだけであり, エージェントAIが新たな知識を生み出しているのではない. そのため, エージェントAIに完全に頼り切ってしまうと, 自力で学習して新しい発見をすることがなくなるため, 社会全体でそれ以上の新技術の発見や発明が途絶え, 文明が停滞すると考えられる. これが「知識の崩壊状態」である. このような設定のモデルを考えたとき, 人々の行動はどういう結果に収束するかを考えるのが, この論文である. 基本モデルはかなり単純であり, エージェントAIにより人々が自分で学習することをやめてしまうという結果は「なるべくしてなった」といえる帰結である. しかし, 論文の後半では, 基本モデルでは単純化しすぎたエージェントAIのはたらきを, 近年の活用に見られるようなより発展的な使い方をしている場合や, 何らかの規制を与えた場合など, より現実に当てはめて考えやすいようにモデルを拡張した場合についても論じている. アセモグルらの論文で導入される数理モデルを紹介するまえに, 非専門家のために, 経済学的なモデルの作り方を簡単に補足説明する. このセクションは, 高校社会科で紹介されるような「需要曲線は右下がりで, 供給曲線は左上がりの曲線である」という程度の話しか知らない人に向けてのものである. 経済学のモデルでは, 需要曲線は右下がりで供給曲線は左下がり, というのは多くの場合で真である. しかし経済学の理論では, その曲線がどうやって導出されたかに関心があることが多い. ほとんどのモデルで, 需要曲線は効用の最大化問題の解として導出される. 効用 (utility) とは, 幸福の量と言い換えればわかりやすいだろう. どんな要因が幸福の量に影響するかを表現した数式が効用関数であり, 効用の最大化問題とは, 効用関数の最大値と, 最大値をとるときの入力値を求めることである. つまり, 人間の行動パターンを 「二次関数の最大値を求めよ」のような数学的な問題に置き換えている. 何が幸福であるかは, 経済理論の中では, 人がこういうことをすると幸福を得られる, と仮定した場合には, この効用最大化問題を解くことで, 人々の行動にこのような形で反映される, というふうな分析に使われる. 今回のモデルでは需要曲線が明示的に現れることはないが, この効用最大化問題はモデルで重要な役割を果たしている. もう1つの供給曲線は, 企業の利潤最大化問題を解いて得られる. しかし今回のモデルでは, 供給曲線も明示的に現れない. 供給曲線が現れないのは IS-LM分析と同じで, 関心のある経済現象を考えるうえで, 供給がどうなっているかはさほど重要ではないからだ. 効用の最大化問題と利潤の最大化問題を解いて, そのうえで需要曲線と供給曲線の交点を求めるのが典型的な経済モデルによる分析だが, 今回のモデルではこそれもしていない. その代わりに 効用最大化問題を解くことに紙面を割いている. 効用関数そのものは単純だが, 確率的な要素を扱っているため, その手続きが複雑になっている. 離散時間の動学モデルを考える. 各期の状態変数を 一方で各個人がそれぞれ独自に持つ知識を状態変数 既に書いたように, このモデルでは1期間が1世代に相当する.つまり, このモデルでは, 個人は生涯に1回だけ学習と意思決定を行い, その結果得られた知識が次の世代に持ち越されることになる, という, 個人の行動をかなりシンプルに表現している. よって, (経済学部である程度勉強した人向けに補足すると) このモデルでは個人の意思決定は各時点で独立したものであり, 効用の最大化問題を解く際には時間割引率などの動学的な作用を考える必要のない比較的シンプルなものになる. 各個人はその生きている時点で, 共通状態 さらに, いくつかの仮定をおく. 次に, 今後の式のわかりやすさのために, いくつかの記号を定義する. それぞれ, 共通状態の予測のみから得られた報酬 さらにもう1つ, 以下の仮定をおく. 例えば, 医者は患者を診断し, その治療法を見つけるのが仕事である. この場合, 診断する患者はその医師特有のものだから, 患者の病名は 予測を的中させるにするには, 学習の努力が必要である. 努力の量を この努力は, 個人が学習して何かの知識を獲得するための労力を表している. つまり, 予測が的中すれば効用が増えるが, 的中確率を上げるには学習が必要で, 学習をすると効用は下がる. よって, 効用の最大化問題を特には, 各個人は, その生きている期間で学習のための努力をする. しかし, 学習結果には多少のランダム性が伴う. 学習によって「シグナル」を得られるものとする. ここでは「シグナル」とは, 知識として蓄積される前の段階の情報であり, 情報が得られてから, それが知識として蓄積されるものなのかどうかが判定される. 学習で得られるシグナルは以下のような個人状態を期待値とする正規分布に従うと仮定する. 努力は分散パラメータの分母なので, 努力が大きいほどシグナルが 共通状態 ただし, 現実的な例を挙げると, エンジニアが稀な場面でしか発生しないバグを発見することを想像する. 個人にとっては, 自分が直接関わっているシステムのバグを修正することにメリットがある. これは個人学習に対応する. 一方で, スタックオーバーフローに投稿する, オープンソースソフトウェア由来ならGitHubにプルリクエストやIssueとして投稿するなどして, 他のエンジニアにとっても将来役に立つよう知見を共有することもできる. これは共有学習である. しかし, このエンジニアがこうすることで得られる直接の利益はほとんどなく, ボランティアである. AI登場以前の時代では, 自分自身の過去から現在に至るシグナルと, 共有シグナルを記憶している. この時代では, AI以外のツールや, 純粋に人間同士の学習によってのみ知識が共有されていく. よって, 共有知識としして認められなかったものは個人ごとの知識としてのみ残る. 島 次に, AIエージェントの導入をこの構造の変化で表現する. AIは個人ごとに 普段LLMを使っていることを想像すれば, AIエージェントとのやり取りの内容を他の人間は知らないし, 他の人間がどう使っているかも把握できない. よって生成AIがもたらすシグナルは個人的なものであり, 集団全員に共有されていないのは明らかだ. よってここでも, このAIによる情報は, 集団全体ではなく個人に対してもたらされるものなので, 集団にとっては直接観測できないし, 集団の知識を直接向上させるものでもない. そのため, AI登場以降の時代では個人の情報集合にのみAIからのシグナルが加わると仮定し, なおかつ相変わらず個人の持つ情報と集団の持つ情報に差があると仮定する. 改めて, 1期間 (つまり, 1世代) で行われる個人と集団の学習行動を順に書くと, 以下のようになる. ここまでの話が長くなったので, 改めてモデルの設定を直感的な説明で要約する. 以上の設定で作られたモデルから, 人々の行動の帰結はどうなるのかを解いていく. まず, 今回の分析で一番重要な, 共有知識の時系列的な変化部分を考える. これは他の変数との相互作用が少ないため, 簡単に式変形できる. これを解くにあたって, 再び経済学特有の仮定が現れるので補足説明する. 結果が確率に左右される時, 人々はある程度うまく結果を予想できると仮定する. ここでは, 人々は確率的に決まる結果そのものを予想することはできないが, 確率の期待値であれば予想できる程度には賢いと仮定する (経済学ではこのような仮定を合理的期待, rational expectation という). そのため, 人々は結果の期待値に合わせて行動すると想定する. この仮定をもとに得た解が, 後述するベイズ均衡と呼ばれるものである. 既に仮定したように, これまでの設定から, カルマンフィルタを当てはめることで事後分散/精度の遷移がわかる. 同様に, 個人状態に対しても同じように事後精度とその遷移式を書ける. 完全ベイズ均衡は4, 全ての個人と全期間で, 期待効用 よって, この予測のもとでは すると完全ベイズ均衡下での期待効用を以下のように表せる. 第2項は共有知識で, 第3項は共有知識と個人知識の相互補完的な効果に対応している. 各個人は毎期自分の期待効用を最大化するような努力 よって, 全個体を通して努力が 先ほどの完全ベイズ均衡とは, ある時点 共有精度の初期状態 また, 最適応答をこれに代入することで, 1期先への遷移式が得られる. 次に, 定常状態 (steady state) について考える. 定常状態とは, 時間を通して同じ状態に落ち着いていること, あるいはその状態のことである. よって, 均衡解の遷移式について 一方で, 図 2 のように, もし関数 経済モデルにこのような定常状態があるのか, そしてそれは安定的なのかを分析するのも, 経済学の主な関心事である. そしてもう1つの自明な解は, 全てがゼロである. しかし, これが起こるのは初期値がゼロであるときのみなので, あまり重要ではない. ベイズ均衡解の式を見ると, 共有知識には2通りの力が働いていることがわかる. 1つは知識の蓄積で, 共通学習パラメータ 次に, 定常均衡解を考える. 経済学の動学モデル一般では, 定常状態とは, 時間的な変化のパターンが一定に収束している状態を表す. 典型的なものは, 経済成長が均衡によって一定の成長率に収束するような現象である. 前節で導いた では, この定常状態は必ず発生するのか. 著者らは, このモデルで知識崩壊的な定常状態が安定的であるのか, つまり, 知識の崩壊が, 人類がほぼ確実にたどり着く未来となってしまう条件を考察している. まず, 次に, このように, 多くの場面で知識の崩壊状態に収束することになる. しかも, 基本モデルでは, エージェントAIの精度が高いほど, 知識の崩壊状態に収束しやすいという悲観的な結果が出ている. エージェントAIによる推薦を規制することを考える. この仮定の追加で, 入手可能な情報を制限していることを表現している. ここでは, 毎期の撹乱の程度を操作できるものとして, 加法独立的なガウシアンノイズを追加する. その精度パラメータ列として新たに, この設定では, 従来の設定のモデルでのエージェントAIの精度パラメータ 基本モデルでは, エージェントAIは個人に対するシグナルを発するという設定だった. このモデルは, エージェントAIが高性能なら個人レベルで学習の努力をする必要がないため, 誰も新しい知識を探索しなくなる, ということを言っているだけで, 当たり前の結果と言えなくもない. そこで, 個人学習だけでなく知識の集約にもエージェントAIが影響する場合を考える. 島の大きさ AIによる知識集約の強度パラメータ つまり, この結果, 2通りの相反する力が生じる. どちらが上回るかはパラメータ 基本モデルでは, エージェントAIは完全に人間の形成した共有知識だけを再共有し, 自分で新たな知識を作ることはないものとしてきた. この設定は, 得られた知識が正しいとはっきり示されるまで時間がかかるような状況に当てはまる. そして, インターネット上のテキストを学習したので, 出回っている情報の誤りや, ジャンルの偏りがそのまま反映されているというLLMの自己参照的な性質も反映している. 一方で, ある程度限定された環境であれば, AIはかなり「創造的」なこともできる. 例えばルールの決まったゲームでの強化学習の応用 (具体例を挙げるなら, AlphaGo Zero) や, 形式的な証明の確認などでも活躍している. これは, AI の出力に対して正誤のフィードバックを逐一送ることで「創造的な」活動をしてくれる. そこで, 基本モデルではランダムに出力していただけのエージェントAIが, より自律的に目的に沿った出力をするような状況を考えてみる. 基本モデルでは, 知識の獲得に際して, 毎期間ごとに学習の精度が事前の情報で更新され, 少しづつ精度が増すというメカニズムが表現されていた. これは, 情報の蓄積によって学習が適切なものになり, 状態の予測がしやすくなることを意味する. この更新に直接影響するのは人間の学習努力だけだった. しかし今, エージェントAIもまた, この探索に協力できるような状況を考える. この変更により, いくつか結果に変化が現れる. まず, このモデルは「大局的」なモデルである. 1期間が人間の1人の生涯に相当しており, 個人の1生涯での動的な意思決定は表現されていない. そのため, 人間が自分の人生設計を見据えて動いたとしたら, このモデルで描いているよりも短い期間のなかでどう変化するかは, このモデルは説明しない. 一方で, モデルの変更の最後で論じられたような動きの例として挙げられている強化学習とかエージェントAIによる証明とかは, 人間の生涯よりも長期的にうまく作用した事例はまだ確立されていない 「知識の崩壊状態」に陥らないような希望に満ちた含意とも言えるが, 現実の例にうまく合致したものがないように見える (最近登場したのだから当たり前ではある). 基本モデルまでの話はエージェントAIに限らない気がする. つまり, エージェントAIが普及する以前からインターネットでの情報収集のやり方は大学の初等教育で課題になっており, とりわけウィキペディアのコピペレポートが顕著だった. であれば, 現在のエージェントAIに対してでなくても実証的な研究もできるのではないかと思う (おそらく成長理論とか情報の経済学とかの分野になると思う. もう既にあったら私が不勉強なだけだ) さて, あなたはこの長文を最後までクソ真面目に読んだだろうか, 途中で飽きてチャットGPTなどに要約させて満足しただろうか? 両者を読み比べたら, このモデルが描写している, 人間が知識獲得をやめるメカニズムについて気づきがあるかもしれない. 日本語では, 概要をそのまま翻訳したか, AI要約をそのまま載せたようなものがいくつかと, 研究者の断片的な反応が見つかる程度だった.↩︎ 業界では10年以上前から「いつか絶対受賞するだろう」と言われ続けていた.↩︎ Acemoglu はこれまでにも, AIやオートメーションによる技術革新と労働市場の関係に関心を示しており (例えば私が昔書いた話 https://ill-identified.hatenablog.com/entry/2019/03/01/135627 ), 「人間の主体性」の問題に対しても発言している (https://www.rieti.go.jp/users/hirono-ayako/serial/007.html).↩︎ この「ベイズ」とは 前回 (https://ill-identified.hatenablog.com/entry/2026/04/27/130805) 触れたものと同じ意味であるが, 意味するところが分からなければ無視しても問題ない.↩︎
概要
時事ネタの尻馬に乗ってバズりたいから解説する.1
はじめに
紹介する論文の要約
モデルの説明
全体の流れ
経済学的なモデルの作り方
記法と基本的な仮定
とする. 時期
は世代と読み替えてもよい. 毎期個人の数が
あり, それらを
] というインデックスで表す. 個人はいくつかの「島」に分かれて存在しており, 島の内部では知識を共有できるが, 異なる島とは共有できないものとする. ここでは, 全ての島に個人が均等に存在すると仮定し,
とする. よって, 島
に住む個人は [tex: I_m:= [mI, (m+1)I と表せる. この「島」は, 何らかの専門的な領域を表しており, そこに属する個人はその分野の専門家ということになる. つまりこれは, 高度な専門分野間の知識の転移は難しいが, 共有知識という形で間接的に伝播するというメカニズムを表現している. また, 後述の設定では, 人の多い分野ほど知識獲得の効率に影響があることになる.
と表す. 状態変数
は, 以下のようなランダムウォークな過程で遷移する.
として, 以下のような遷移をする. この式が示すように, 個人知識の状態はホワイトノイズ的であり, 個体間でも独立している. つまり, 個人の人生に特有の要因を表している.
個人の効用
と自分自身の個人の状態
を予測して行動しようとする. それぞれの予測値を
とする. 予測は正解に近いほうが好ましいので, 予測値の誤差に応じて報酬を得られる関数
を仮定する. 単純のため, 2つの状態の予測について, それぞれ誤差が一定以内かどうかの2通りだけを考える.
は, 共通状態
に対する個人の予測
の差が1以内なら1, そうでないなら0を表している. 以降では, 単に「予測が的中する」といえば, このしきい値を満たしていることを意味することにする. この式を使い, 共通状態と個人状態それぞれに対して予測が的中したかどうかの2通りの, 合計4通りの結果に対する結果だけを考えればすむような設定にする. このとき, 報酬関数は
であり, 以下のように表せる.
とする
は弱い増加関数である
は
に正規化されている.
, 個人状態の予測のみから得られた報酬
, 両方同時に予測できたことから得られた報酬
を表している. そして, 正規化の仮定から,
である.
,
とする.
に対応する. 一方で, 診断に成功した場合, 次に治療法を予測する必要がある. 治療法は医者の間で共有されるものだから, こちらは
に対応する. よって,
かつ
とは, 医者が患者の病気を特定できたが, 治療法を知らない場合はその仕事は価値を生み出さない, ということを表している. 一方で,
という仮定はしていない. 純粋に共有状態だけを予測する行為にも, 一定の価値があると仮定しているからである. 医者のたとえでは, 高度な診断ができなくとも初歩的な医療知識があれば一定の効果がある, ということを表している. なお, この仮定を満たす関数形には, 古典的な生産関数の1つである Leontief 型生産関数
がある.
個人と集団の学習メカニズムの表現
で表し, 各時点・各個人は以下のような効用を最大化するように行動するものと仮定する.
が予測にどう影響するかも知る必要がある.
に近づく確率が高くなる. さらにパラメータ
は努力の係数であり, 大きいほど分散が低下する. これを個人技術パラメータと呼ぶ.
は各島ごとに決まり, こちらも努力とその係数である共通技術パラメータ
が大きいほど, シグナルが
に近づく. しかし一方で, 共通知識の蓄積は個人の努力ではなく, 集団全員の努力が影響する.
である, 共通シグナル
は, 島の集団の次の世代の個人全員に共有される.
の定義から, 共通知識に対する個人の貢献は無限小であり, この設定では個人は共通知識に対して貢献するインセンティブを全く持たない. 知識の共有によって, 将来別の人が有用な発見をすることで共有知識の発展に貢献することはあっても, 共有した個人が直接利益を得ることがないという想定である.
AI前後の情報共有の変化
の個人
を
と表すと, 個人の情報集合と集団の情報集合は以下のようになる.
に対するシグナルを提供し, それは以下のような正規分布に従う確率変数で表現される. パラメータ
はAIの出力の正確さを意味している. そして, AIのシグナルは努力
に依存しないから, 特に努力をしなくても個人にとっては未知の知識が入手できることになる.
の各個人
は自分の島の共通知識
をもとに, 自分の効用が最大になるよう学習努力の量
を決定する.
は個人的なシグナル
を知る. AI以降の時代なら, さらにシグナル
を知る.
を考え, その結果が的中したかどうかで効用が決まる.
ごとに, 集団の共通知識を集約し, そこから新たな共有シグナル
を発信する. このシグナルは来期の島
の全員がアクセスできる.
ここまでの要約
モデルの解き方
信念の更新
時点までの共有情報を得た状態での共有状態
は正規分布に従う. この時点までの知識を全て利用したうえで状態変数の条件分散を事後分散といい,
と表す, さらに, 事後分散の逆数を事後精度 (posterior precision) と呼び,
と表す. 精度は分散の逆数なので, 値が大きいほど結果の値がどうなるかを絞り込めることになる. 分散より精度で表したほうが式が簡単になるため, これ以降では精度を使って表現する.
完全ベイズ均衡
を最大化するような
である. ここで各個人は各期で, 状態変数
に対して事後期待値に基づいた1期先ベイズ予測をするものとする.
となり, 「予測が的中」するかどうかの確率を
と書ける.
を決定する. ここまでに述べた仮定から, 期待効用は
に対して強い凹関数になるので, 一階条件から期待効用の最大値を求められる. ここから,
に対する個人の最適な努力の集合である「最適努力応答集合」は以下のようになる.
と一致するのが均衡状態となる.
動的均衡
での解を表している. どの時点でも成り立つが, では全ての時点で完全ベイズ均衡が成り立つ場合,
が時間経過するにつれ発生する動的な変化にはどのような特徴があるのか, というのが次の問いである.
が既知の状態では, 対称な完全ベイズ均衡経路が一意に存在し, 任意の時点
について以下を満たす経路
が一意解となる.
定常均衡
定常状態とは
が成り立つような
が定常状態を表す (つまり, 定常状態とは数式上は不動点と同じものである.). このモデルの定常状態について書く前に, 定常状態の一般的な考え方を解説する. 遷移式
から, もし関数
が
となるなら, 時期の
減少していき,
なら増加していく. よって,
の形状がわかるなら, 45度線と
を描けば定常状態があるのかどうかということと, 定常状態へ収束するかどうかが視覚的にわかる. 例えば 図 1 は,
なら
が増加し,
なら
が減少するため, 初期値に関係なく, 時間経過とともに定常状態
へと収束する. このように, どんな初期値であっても収束するような定常状態を「安定的」な定常状態という. ただし この例では初期値
は唯一の例外で, 初期値がこの値の場合は永遠に
となる.

図 1 定常状態へ収束する単純な例 が減少関数ならば, ほとんどの場合で
は
から離れていく. 初期状態の時点で
でない限り, 定常状態にたどり着かない. このような定常状態は「不安定」な定常状態と呼ばれる. 図 2 はわかりやすさのために単純な直線にしているが, 関数が複雑で, 45度線との間に複数の交点があると複数の定常状態が発生する可能性もある.
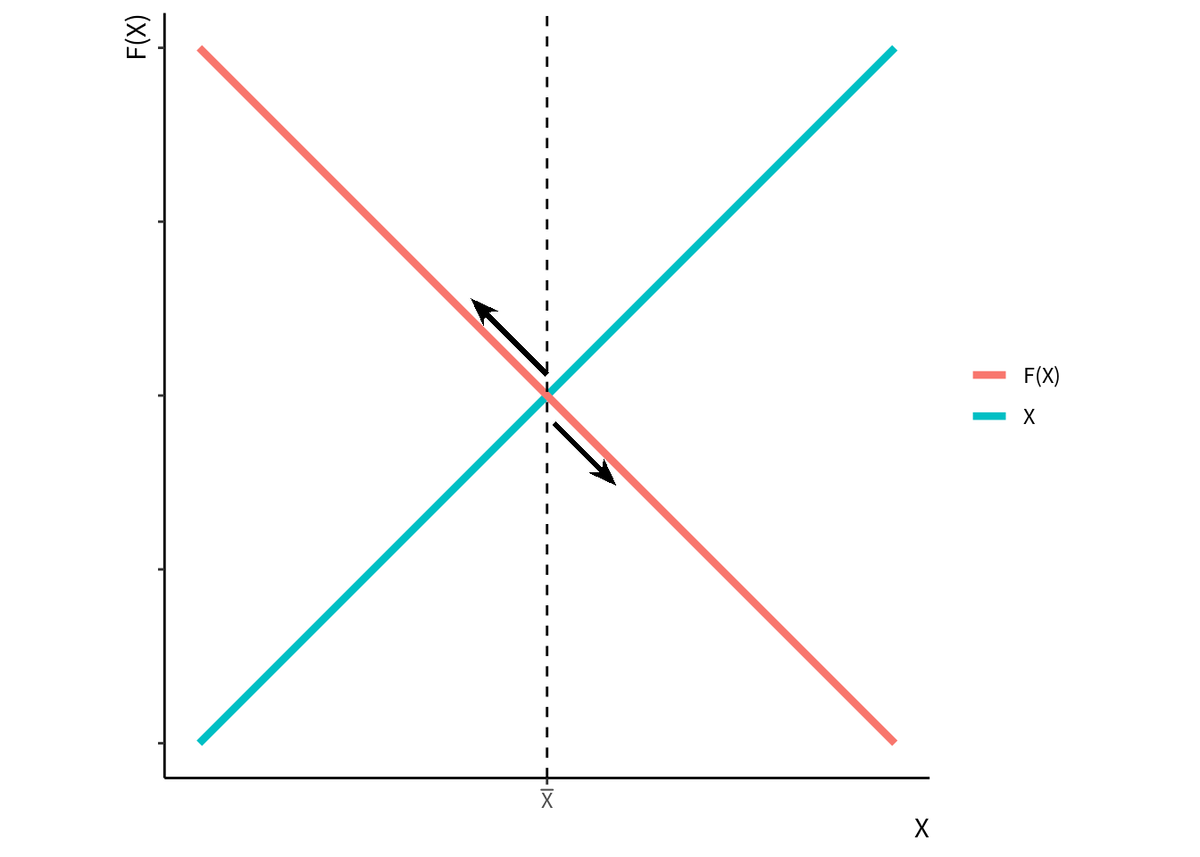
図 2 不安定な定常状態の例
定常均衡
となるときに, 状態変数に関係する
,
も同様に定常状態になるとすれば,
から,
である.
モデルの解からわかること
, 島の集約容量
と努力量
の積である
の部分に相当する.
は, 次の時点の共通精度を向上させる共通知識のシグナルの増加に寄与する. もう1つは, 知識の減衰方向への力である. 共通状態はランダムウォークに従うため, 過去の状態をもとに予測するのが難しく, そして変化の大きさはイノベーションパラメータ
に依存する. 仮に, ある時偶然に, 精度が高くなった時があったとしても, 次回にはまた
となる.
は
を超えることはない.
定常均衡の安定性
という解は, 集団が長期的には使える共有知識を全く生み出さなくなっているという状況を示している. この式にはエージェントAIの動きも織り込み済みであるから, エージェントAIが個人に対して何らかの有用な知識を与えていたとしても, それは社会全体でみれば既知の事柄であり, 社会全体では新しい知識獲になっていないことを表している. そのため著者らはこの解を「知識崩壊 (knowledge-collapse) 的な定常状態」と呼んでいる.
必ず知識崩壊に向かう場合
の場合, AIの精度
の増大に対応して
は減少し,
は増大する. そして,
が増大すると, これら3つは全て増大する. つまり, エージェントAIの精度
が優れているほど, 定常状態では, 個人の知識は増えるが, 人間側の知識獲得の努力
は小さくなり, 共有知識の蓄積も小さくなる. 一方で, 知識集約の容量
が大きくなるほど定常状態を高水準にする. いずれにせよ, この場合
になるのは, 初期状態がゼロのとき, つまり
の場合だけである. (図 3)
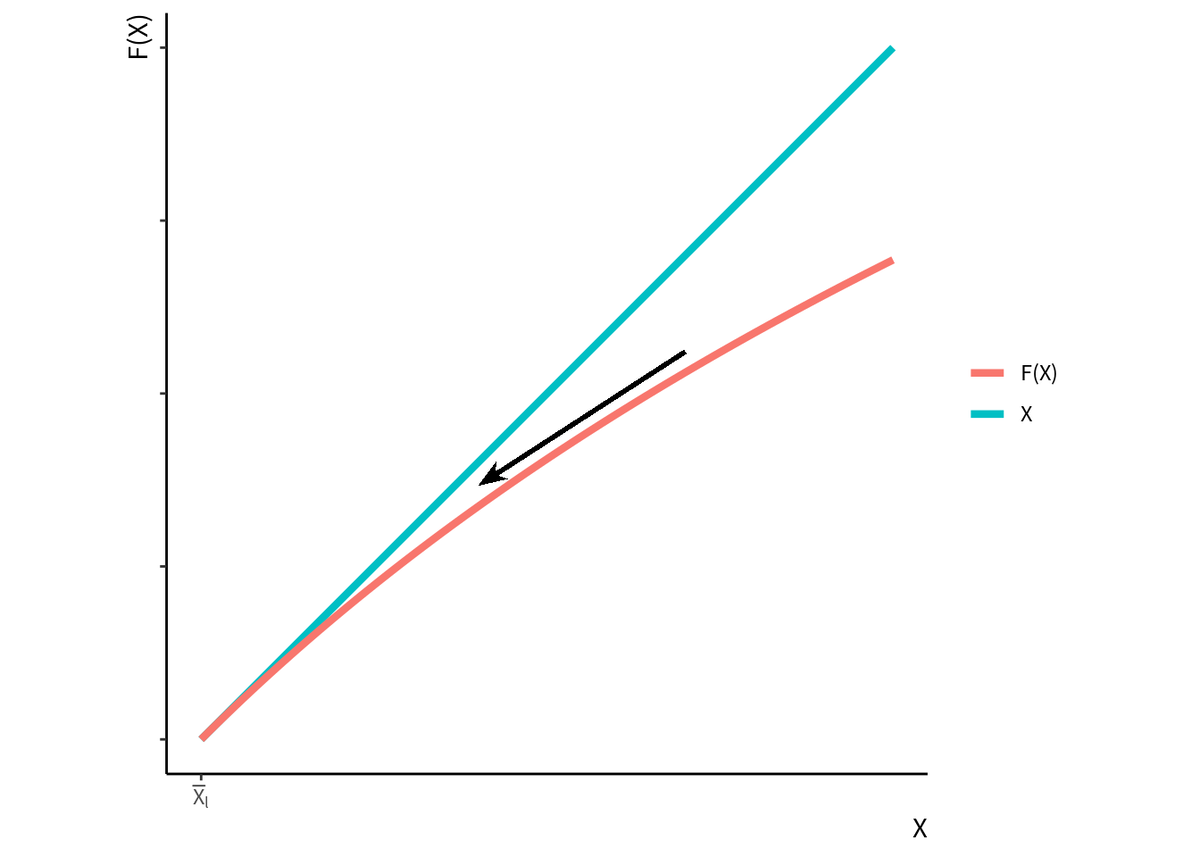
図 3 必ずゼロに収束する場合
知識崩壊に陥らない可能性が残っている場合
のときは, あるしきい値
があって, さらにそれを境に定常状態の性質が変わる, 「複数均衡」の場合である.
のとき,
は, ゼロの場合を含め3通り存在する.
のうち,
は局所安定的であり,
は局所不安定である. どれに収束するかは初期状態
に依存する (図 4).
のとき, 知識の崩壊状態が唯一の定常均衡であり, この定常状態は大域安定的である.

図 4 複数の均衡がある場合 が大きいほどそうなりやすい. つまり, エージェントAIの出力する情報がより的確になればなるほど, 人々は自分で学習することをやめてしまい, 人類全体での知識の進歩が止まってしまうということになる.
モデルの変更
エージェントAIの規制
を定義する. 各パラメータは [tex: \kappa_t \in [0, +\infty とする. 従来のエージェントAIから個人へのシグナルは
から 以下の
に置き換わる. なお,
ならば, 規制が発生しないことになる.
が
] に置き換わったのと同等で, よって毎期の精度パラメータを
] の範囲で制御できるという状況を表している. 既に示したように,
つまり複数均衡のある場合では, 知識の崩壊状態に収束するか, 持続的な知識蓄積状態に収束するかは初期値と精度パラメータに依存する. そのため, 自明な解を除いた初期値
であれば, 知識の崩壊状態への収束を阻止する規制
があると示している. この規制とは, 知識の崩壊状態へ収束する経路に乗らないように最初は完全に規制し, 経路を脱してからは適切な水準に規制することが最適だというものである.
エージェントAIが共通知識の獲得にも寄与する場合
を
を追加して考える.
はAI以前の
を表している.
はこれまで人口に相当するものだったが, 同時に知識集約の能力の大きさを表す変数でもあった. この追加の仮定では, AIが集約能力を促進するということを表している. しかし一方で, 共有シグナルのそれ以外の仮定は基本モデルのままであり,
である. よって, 共有シグナルの式が以下のように変わる.
が大きいほど,
は減少する. つまり, 個人由来の共有知識の獲得が低下する.
が大きいほど,
が増加する. つまり, 個人の努力の集約がより共有知識の獲得が増加する.
しだいである. そのしきい値は
と導出している.
合成データ
に関するシグナルに精度
が追加される場合を考える. つまり, 一般知識に対するシグナルの精度の遷移は以下のように変更される.
とするだけで
が保証されるため, 知識ゼロ状態が定常状態から消える.
の複数均衡の場合では, 基本モデルでは「知識の崩壊状態」が安定定常状態として存在したが, これにより少なくとも知識ゼロではなく, 知識がゼロより大きくなる「比較的低知識状態」に置き換わる.
個人的な意見・考察
参考文献
Acemoglu, Daron, Dingwen Kong, and Asuman Ozdaglar. 2026. “AI, Human Cognition and Knowledge Collapse.” w34910. Cambridge, MA: National Bureau of Economic Research. 10.3386/w34910.