Unicode diacritics which should be rendered before character not rendered correctly. #3830
Comments
|
Is it correct that these glyphs are not using zero width to combine with the previous character, but instead expect font layout to handle this? There's no support in Alacritty for advanced font layout, all glyphs are rendered independently without consideration for leading/following glyphs. While it would be possible to have leading diatrics like that using font offsets and zerowidth characters, it does not appear like that is the case for these. I don't think there's currently any interest in supporting this either, since it's basically just a huge performance hit without much benefit for most people. Some limited compositing might be done to get ligatures working, but that's about it. @kchibisov / @nixpulvis should we create a tracking issue for font layout and things Alacritty does not currently support, or do we just want to ignore it for now? |
|
I have a possibly similar problem with diacritics that should be rendered over the previous symbol. When I have a Ũ (U+0168), it is rendered correctly. When there is a Ũ (U+55 U+0303) instead, the tilde is rendered after U and not over the U. The font is DejaVu Sans Mono. The combining diacritic works in rxvt-unicode with this font. These combining diacritics are often encountered when working with Julia, which has quite nice unicode support to keep the code closer to mathematical notation. Is this the same problem? |
|
Closing since text layout like ligatures/RTL is not supported and currently not on the roadmap either. Zero-width diatrics work just fine, it's just that some fonts do not define them properly. Some terminals perform unicode normalization to work around this, but it's not something planned for Alacritty. |
|
@chrisduerr Is what I am describing a unicode feature that is not on the roadmap or a font problem (whose workaround is not on the roadmap either)? |
|
|
|
@nixpulvis Ok, thanks. So switching font is not enough. I will need to switch terminal for Julia development. |
|
I'll just add that there has been work done on this, but nothing that was ever in a position to be merged. I've since lost track of the work myself personally. In general I find ligatures to make it more difficult to program and they open up a wide class of homoglyphic attacks. Without knowing more about Unicode normalization I cannot comment on using Alacritty for projects with a large number of special characters. With that being said, I can say that copy and pasting both of your example characters from above resulted in the combined single glyph on my system, so YMMV. |
|
I see. Honestly, I don't know wether julia does/recommends some normalization there. AFAIK, single glyph Ũ stays single glyph and combined glyph Ũ stays double glyph in their REPL. Copying it back from my comment also shows the combined single glyph. I guess this is part of github. When I copied the letter out of the text field, it still consisted of two glyphs. |
|
What nixpulvis said here is incorrect. For diatrics like these the diatric itself is zerowidth and will be automatically combined if your font has it defined properly. The only thing that Alacritty doesn't support is automatically normalizing from U+55 U+0303 to U+0168 to work around fonts which do not properly define them. With Fira Mono for example the un-combined version is rendered just fine in a single cell. |
|
OK, I swear I tested this, god damn it. But sure enough |
The alignment is based on your font. It can put that wherever it wants it to but of course since it can be combined with any other character it might not look great with every single one of them. |
|
So it sounds like the real answer to @Uroc327's question is that it's not exactly on the roadmap, since we don't have an issue for Unicode normalization. It's also possibly a font issue depending on the specific case, but I'm guessing there are no fonts that combine everything in proper alignment without some special handling. If we were to do Unicode normalization, would we actually replace the character, or simply render it. Meaning, would copying the glyph result in the normalized character or the original text? One option seems more "correct" while the other more efficient. |
Seeing as this comes up somewhat frequently, it might be nice. I clearly would benefit from it myself, since I tend to forget these details. Here's a list of things I've collected:
Many of these represent changes to crossfont, but I suppose I could create a tracking issue here and link to the various existing issues as best I can. |
|
Most of the issues you've mentioned here are not something that would provide much benefit to Alacritty users in my opinion. Things can be largely figured out with just proper fonts and a reasonable font fallback list. |
|
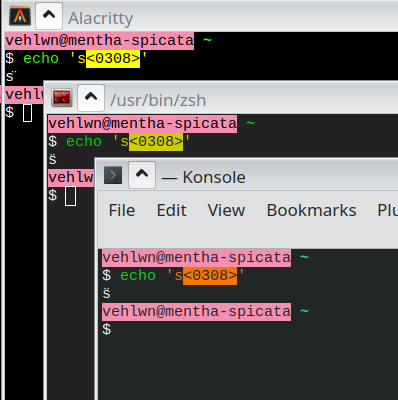
The issue still persists - combining symbols are rendered incorrectly. Try something + Combining Breve U+0306 or Combining Diaeresis U+0308: These symbols don't have combined versions. You can test in with Python's unicodedata module: >>> import unicodedata
>>> unicodedata.normalize('NFKC', 's̆').encode("utf-8")
b's\xcc\x86'
>>> unicodedata.normalize('NFKC', 's̈').encode("utf-8")
b's\xcc\x88'I've configured Alacritty to use Liberation Mono font and these symbols appear broken only here and not in Konsole, Terminator, LibreOffice Writer, Gimp or any other Qt or GTK app in my system. Arch Linux, alacritty 0.11.0.
|

|
@vehlwn I've noticed that some fonts use weird metrics for such glyphs, for example Fira Mono doesn't have this issue at all... |
In certain languages, like the Bengali script (which I am most familiar with), as well as Hindi and several other languages from India, diacritics which follow a character actually need to be written before the character. You can see this in the image on this page: https://en.wikibooks.org/wiki/Bengali/Script/Diacritics. The red parts of each character in the image show the diacritics written afterward. Unfortunately, alacritty places completely inccorectly ি, ে, ৈ, ো, or ৌ, where part or all of the diacritic is to the left of the character. Additionally, া and ী (which are positioned to the right of a character) slightly intersect the character. Finally, the ্য character (which even github also renders incorrectly on my system) is rendered incorrectly by alacritty (github however renders it correctly when it's conjunction with another consonant, like this: ক্য. Alacritty renders it as the ক smooshed against the ্য character). Altogether, this renders the text almost entirely unreadable.
Here is an image of some song lyrics, were you can see that many of the characters are misaligned/overlap/have incorrect spacing.

Here is the same text rendered correctly in mousepad:
 .
.
And here is a list of all the diacritics correctly rendered in mousepad:

compared to alacritty:

I believe the same issue occurs in Hindi (Devanagri script), and several other scripts which use the same type of diacritics, but I do not know those languages, so obviously cannot say anything about them confidently.
System
OS: Linux
Version: 0.4.3
Linux/BSD: X11, picom, bspwm
Font size: Changing font size doesn't change anything, even with really tiny or very big letters.
The text was updated successfully, but these errors were encountered: