Downloaded 16 times
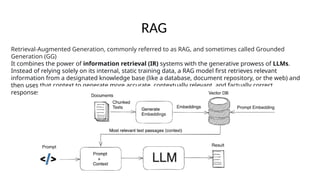









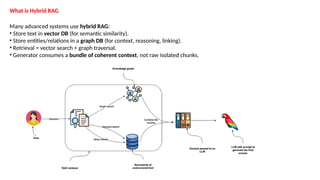



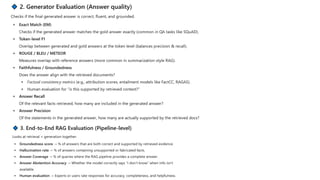


his guide dives deep into Retrieval-Augmented Generation (RAG) — what it is, why it matters, and how to make it work in real-world applications. Learn about the core problems RAG solves, why LLMs need retrieval, how RAG pipelines work, and the common pitfalls (like chunking issues). It also covers best practices, hybrid RAG, the role of graph databases, and effective evaluation techniques to build reliable, trustworthy RAG systems. Perfect for AI practitioners, ML engineers, and anyone looking to deploy LLM-powered applications with stronger grounding and less hallucination.





















































































