Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Yifeng Jiang
PDF, PPTX
15,780 views
Apache Hiveの今とこれから
Apache Hive - Present and Future
Software
◦
Read more
46
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 53
2
/ 53
3
/ 53
4
/ 53
5
/ 53
6
/ 53
7
/ 53
8
/ 53
9
/ 53
10
/ 53
11
/ 53
12
/ 53
13
/ 53
14
/ 53
15
/ 53
16
/ 53
17
/ 53
18
/ 53
19
/ 53
20
/ 53
21
/ 53
22
/ 53
23
/ 53
24
/ 53
25
/ 53
26
/ 53
27
/ 53
28
/ 53
29
/ 53
30
/ 53
31
/ 53
32
/ 53
33
/ 53
34
/ 53
35
/ 53
36
/ 53
37
/ 53
38
/ 53
39
/ 53
40
/ 53
41
/ 53
42
/ 53
43
/ 53
44
/ 53
45
/ 53
46
/ 53
47
/ 53
48
/ 53
49
/ 53
50
/ 53
51
/ 53
52
/ 53
53
/ 53
More Related Content
PDF
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
RDF Semantic Graph「RDF 超入門」
by
オラクルエンジニア通信
PPTX
Apache BigtopによるHadoopエコシステムのパッケージング(Open Source Conference 2021 Online/Osaka...
by
NTT DATA Technology & Innovation
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
ちょっと理解に自信がないなという皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
by
NTT DATA Technology & Innovation
Prestoで実現するインタラクティブクエリ - dbtech showcase 2014 Tokyo
by
Treasure Data, Inc.
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
RDF Semantic Graph「RDF 超入門」
by
オラクルエンジニア通信
Apache BigtopによるHadoopエコシステムのパッケージング(Open Source Conference 2021 Online/Osaka...
by
NTT DATA Technology & Innovation
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
ちょっと理解に自信がないなという皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PostgreSQL 12は ここがスゴイ! ~性能改善やpluggable storage engineなどの新機能を徹底解説~ (NTTデータ テクノ...
by
NTT DATA Technology & Innovation
What's hot
PPTX
WiredTigerを詳しく説明
by
Tetsutaro Watanabe
PDF
[Modern Cloud Day Tokyo 2019] オラクルコンサルが語る!事例でみていくOracle Cloud Infrastructure設...
by
オラクルエンジニア通信
PDF
計算機アーキテクチャを考慮した高能率画像処理プログラミング
by
Norishige Fukushima
PDF
バッチ処理にバインド変数はもうやめません? ~|バッチ処理の突発遅延を題材にして考えてみる~
by
Ryota Watabe
PDF
Linuxにて複数のコマンドを並列実行(同時実行数の制限付き)
by
Hiro H.
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
5G時代のアプリケーション開発とは - 5G+MECを活用した低遅延アプリの実現へ
by
VirtualTech Japan Inc.
PPTX
Druid deep dive
by
Kashif Khan
PPTX
Parquetはカラムナなのか?
by
Yohei Azekatsu
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PDF
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
PDF
30分でわかるマイクロサービスアーキテクチャ 第2版
by
Naoki (Neo) SATO
PDF
Hiveを高速化するLLAP
by
Yahoo!デベロッパーネットワーク
PDF
WebSocket / WebRTCの技術紹介
by
Yasuhiro Mawarimichi
PDF
Why My Streaming Job is Slow - Profiling and Optimizing Kafka Streams Apps (L...
by
confluent
PDF
Linux-HA Japanプロジェクトのこれまでとこれから
by
ksk_ha
PDF
Apache Bigtop3.2 (仮)(Open Source Conference 2022 Online/Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
Hive on Tezのベストプラクティス
by
Yahoo!デベロッパーネットワーク
PDF
Oracle GoldenGateでの資料採取(トラブル時に採取すべき資料)
by
オラクルエンジニア通信
PDF
データ基盤の従来~最新の考え方とSynapse Analyticsでの実現
by
Ryoma Nagata
WiredTigerを詳しく説明
by
Tetsutaro Watanabe
[Modern Cloud Day Tokyo 2019] オラクルコンサルが語る!事例でみていくOracle Cloud Infrastructure設...
by
オラクルエンジニア通信
計算機アーキテクチャを考慮した高能率画像処理プログラミング
by
Norishige Fukushima
バッチ処理にバインド変数はもうやめません? ~|バッチ処理の突発遅延を題材にして考えてみる~
by
Ryota Watabe
Linuxにて複数のコマンドを並列実行(同時実行数の制限付き)
by
Hiro H.
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
5G時代のアプリケーション開発とは - 5G+MECを活用した低遅延アプリの実現へ
by
VirtualTech Japan Inc.
Druid deep dive
by
Kashif Khan
Parquetはカラムナなのか?
by
Yohei Azekatsu
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
Javaのログ出力: 道具と考え方
by
Taku Miyakawa
30分でわかるマイクロサービスアーキテクチャ 第2版
by
Naoki (Neo) SATO
Hiveを高速化するLLAP
by
Yahoo!デベロッパーネットワーク
WebSocket / WebRTCの技術紹介
by
Yasuhiro Mawarimichi
Why My Streaming Job is Slow - Profiling and Optimizing Kafka Streams Apps (L...
by
confluent
Linux-HA Japanプロジェクトのこれまでとこれから
by
ksk_ha
Apache Bigtop3.2 (仮)(Open Source Conference 2022 Online/Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Hive on Tezのベストプラクティス
by
Yahoo!デベロッパーネットワーク
Oracle GoldenGateでの資料採取(トラブル時に採取すべき資料)
by
オラクルエンジニア通信
データ基盤の従来~最新の考え方とSynapse Analyticsでの実現
by
Ryoma Nagata
Viewers also liked
PDF
[db tech showcase Tokyo 2015] C15:DevOps MySQL in カカクコム~ OSSによる可用性担保とリアルタイムパフ...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...
by
Insight Technology, Inc.
PDF
[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラスタリ...
by
Funada Yasunobu
PDF
[db tech showcase Tokyo 2015] C32:「データ一貫性にこだわる日立のインメモリ分散KVS~こだわりの理由と実現方法とは~」 ...
by
Insight Technology, Inc.
PDF
Presto in Treasure Data
by
Mitsunori Komatsu
PDF
[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2015] B27:インメモリーDBとスケールアップマシンによりBig Dataの課題を解決する by S...
by
Insight Technology, Inc.
PDF
Db tech show - hivemall
by
Makoto Yui
PDF
[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2015] D23:MySQLはドキュメントデータベースになり、HTTPもしゃべる - MySQL Lab...
by
Insight Technology, Inc.
PDF
Dbts2015 tokyo vector_in_hadoop_vortex
by
Koji Shinkubo
PDF
[db tech showcase Tokyo 2015] C16:Oracle Disaster Recovery at New Zealand sto...
by
Insight Technology, Inc.
PDF
Mongodb x business
by
emin_press
PDF
[db tech showcase Tokyo 2015] D25:The difference between logical and physical...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2015] B24:最高峰の可用性 ~NonStop SQLが止まらない理由~ by 日本ヒューレット・パ...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...
by
Insight Technology, Inc.
PDF
[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう
by
datastaxjp
[db tech showcase Tokyo 2015] C15:DevOps MySQL in カカクコム~ OSSによる可用性担保とリアルタイムパフ...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...
by
Insight Technology, Inc.
[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラスタリ...
by
Funada Yasunobu
[db tech showcase Tokyo 2015] C32:「データ一貫性にこだわる日立のインメモリ分散KVS~こだわりの理由と実現方法とは~」 ...
by
Insight Technology, Inc.
Presto in Treasure Data
by
Mitsunori Komatsu
[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2015] B27:インメモリーDBとスケールアップマシンによりBig Dataの課題を解決する by S...
by
Insight Technology, Inc.
Db tech show - hivemall
by
Makoto Yui
[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2015] D23:MySQLはドキュメントデータベースになり、HTTPもしゃべる - MySQL Lab...
by
Insight Technology, Inc.
Dbts2015 tokyo vector_in_hadoop_vortex
by
Koji Shinkubo
[db tech showcase Tokyo 2015] C16:Oracle Disaster Recovery at New Zealand sto...
by
Insight Technology, Inc.
Mongodb x business
by
emin_press
[db tech showcase Tokyo 2015] D25:The difference between logical and physical...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2015] B24:最高峰の可用性 ~NonStop SQLが止まらない理由~ by 日本ヒューレット・パ...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...
by
Insight Technology, Inc.
[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう
by
datastaxjp
Similar to Apache Hiveの今とこれから
PDF
Apache Hiveの今とこれから - 2016
by
Yuta Imai
PDF
Hortonworksが提供する データ活用方法の紹介
by
Kimihiko Kitase
PDF
Hive-sub-second-sql-on-hadoop-public
by
Yifeng Jiang
PDF
Hadoop Trends & Hadoop on EC2
by
Yifeng Jiang
PDF
Yifeng hadoop-present-public
by
Yifeng Jiang
PDF
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
PDF
OLAP options on Hadoop
by
Yuta Imai
PPTX
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
PDF
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
PDF
Hadoop上の多種多様な処理でPigの活きる道 (Hadoop Conferecne Japan 2013 Winter)
by
NTT DATA OSS Professional Services
PDF
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
PPTX
B34 Extremely Tuned Hadoop Cluster by Daisuke Hirama
by
Insight Technology, Inc.
PDF
S01 t3 data_engineer
by
Takeshi Akutsu
PDF
20100930 sig startups
by
Ichiro Fukuda
PDF
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
PDF
[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...
by
オラクルエンジニア通信
PDF
クラウドにおけるビッグデータ分析環境
by
Kimihiko Kitase
PDF
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
PDF
"Programming Hive" Reading #1
by
moai kids
PDF
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
Apache Hiveの今とこれから - 2016
by
Yuta Imai
Hortonworksが提供する データ活用方法の紹介
by
Kimihiko Kitase
Hive-sub-second-sql-on-hadoop-public
by
Yifeng Jiang
Hadoop Trends & Hadoop on EC2
by
Yifeng Jiang
Yifeng hadoop-present-public
by
Yifeng Jiang
Hadoop最新事情とHortonworks Data Platform
by
Yuta Imai
OLAP options on Hadoop
by
Yuta Imai
sparksql-hive-bench-by-nec-hwx-at-hcj16
by
Yifeng Jiang
HadoopとRDBMSをシームレスに連携させるSmart SQL Processing (Hadoop Conference Japan 2014)
by
Hadoop / Spark Conference Japan
Hadoop上の多種多様な処理でPigの活きる道 (Hadoop Conferecne Japan 2013 Winter)
by
NTT DATA OSS Professional Services
Beginner must-see! A future that can be opened by learning Hadoop
by
DataWorks Summit
B34 Extremely Tuned Hadoop Cluster by Daisuke Hirama
by
Insight Technology, Inc.
S01 t3 data_engineer
by
Takeshi Akutsu
20100930 sig startups
by
Ichiro Fukuda
Hadoopデータプラットフォーム #cwt2013
by
Cloudera Japan
[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...
by
オラクルエンジニア通信
クラウドにおけるビッグデータ分析環境
by
Kimihiko Kitase
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
"Programming Hive" Reading #1
by
moai kids
TokyoWebminig カジュアルなHadoop
by
Teruo Kawasaki
More from Yifeng Jiang
PDF
Hive spark-s3acommitter-hbase-nfs
by
Yifeng Jiang
PDF
introduction-to-apache-kafka
by
Yifeng Jiang
PDF
Hive2 Introduction -- Interactive SQL for Big Data
by
Yifeng Jiang
PDF
Introduction to Streaming Analytics Manager
by
Yifeng Jiang
PDF
HDF 3.0 IoT Platform for Everyone
by
Yifeng Jiang
PDF
Hortonworks Data Cloud for AWS 1.11 Updates
by
Yifeng Jiang
PDF
Spark Security
by
Yifeng Jiang
PDF
Introduction to Hortonworks Data Cloud for AWS
by
Yifeng Jiang
PDF
Real-time Analytics in Financial
by
Yifeng Jiang
PDF
Nifi workshop
by
Yifeng Jiang
PDF
Sub-second-sql-on-hadoop-at-scale
by
Yifeng Jiang
PDF
Yifeng spark-final-public
by
Yifeng Jiang
PDF
Kinesis vs-kafka-and-kafka-deep-dive
by
Yifeng Jiang
PPTX
Hive present-and-feature-shanghai
by
Yifeng Jiang
PDF
Hadoop Present - Open Enterprise Hadoop
by
Yifeng Jiang
PDF
HDFS Deep Dive
by
Yifeng Jiang
PDF
Apache Ambari Overview -- Hadoop for Everyone
by
Yifeng Jiang
PDF
HDP Security Overview
by
Yifeng Jiang
PDF
Data Science on Hadoop
by
Yifeng Jiang
Hive spark-s3acommitter-hbase-nfs
by
Yifeng Jiang
introduction-to-apache-kafka
by
Yifeng Jiang
Hive2 Introduction -- Interactive SQL for Big Data
by
Yifeng Jiang
Introduction to Streaming Analytics Manager
by
Yifeng Jiang
HDF 3.0 IoT Platform for Everyone
by
Yifeng Jiang
Hortonworks Data Cloud for AWS 1.11 Updates
by
Yifeng Jiang
Spark Security
by
Yifeng Jiang
Introduction to Hortonworks Data Cloud for AWS
by
Yifeng Jiang
Real-time Analytics in Financial
by
Yifeng Jiang
Nifi workshop
by
Yifeng Jiang
Sub-second-sql-on-hadoop-at-scale
by
Yifeng Jiang
Yifeng spark-final-public
by
Yifeng Jiang
Kinesis vs-kafka-and-kafka-deep-dive
by
Yifeng Jiang
Hive present-and-feature-shanghai
by
Yifeng Jiang
Hadoop Present - Open Enterprise Hadoop
by
Yifeng Jiang
HDFS Deep Dive
by
Yifeng Jiang
Apache Ambari Overview -- Hadoop for Everyone
by
Yifeng Jiang
HDP Security Overview
by
Yifeng Jiang
Data Science on Hadoop
by
Yifeng Jiang
Apache Hiveの今とこれから
1.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Apache Hiveの今とこれから Yifeng Jiang Solutions Engineer, Hortonworks, inc. June 11, 2015
2.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved 自己紹介 蒋 逸峰 (Yifeng Jiang) • Solutions Engineer @ Hortonworks Japan • HBase book author • ⽇日本に来て10年年経ちました… • 趣味は⼭山登り • Twitter: @uprush
3.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved アジェンダ • Apache Hiveの今 • 100倍早くなった仕組み • 1秒以下のレスポンスを実現していく
4.
© Hortonworks Inc.
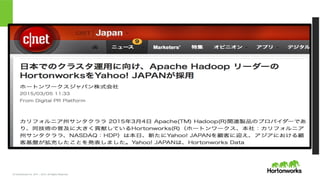
2011 – 2015. All Rights Reserved 専門家集団: 開発に深く携わるコア・メンバーにより構成 沿革 2011年6月: Yahoo! で初代の Hadoop 開発を手がけたアーキテクト、デベロッパー、 オペレータ 24名によって創立 2014年12月: 社員数600を超えるHadoopの専門家集団に成長 400以上のお客様、うち2/3はF1000企業 Apache Project Committers PMC Members Hadoop 27 21 Pig 5 5 Hive 18 6 Tez 16 15 HBase 6 4 Phoenix 4 4 Accumulo 2 2 Storm 3 2 Slider 11 11 Falcon 5 3 Flume 1 1 Sqoop 1 1 Ambari 36 28 Oozie 3 2 Zookeeper 2 1 Knox 13 3 Ranger 11 n/a TOTAL 164 109
5.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved
6.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Hortonworks Data Platform (HDP) 2.2 Stack Hive: SQL on Hadoop
7.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Apache Hiveの今 Transaction, Temp Table, Security, Performance
8.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Apache Hiveを振り返てみる Page 8Hive & HBase For Transaction Processing • Facebook社がOSS化したHadoop上のSQLデータ・ウェアハウス • 2009年年にApache Hiveとしてはじめのリリース • 最初のゴールはSQL⾔言語でMapReduceを簡単に実⾏行行できるように – ほとんどのクエリが数分から数時間かかっていた – 主にバッチのETLジョブに利利⽤用されてた
9.
© Hortonworks Inc.
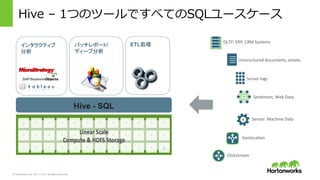
2011 – 2015. All Rights Reserved Hive – 1つのツールですべてのSQLユースケース OLTP, ERP, CRM Systems Unstructured documents, emails Clickstream Server logs Sen>ment, Web Data Sensor. Machine Data Geoloca>on インタラクティブ 分析 バッチレポート/ ディープ分析 Hive - SQL ETL処理
10.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 あらゆるワークロードまでスケールするHive Page 10 Hive at Facebook • 100PB以上のデータ • 毎⽇日15TB以上をHiveにロード • 毎⽇日6万以上のHiveクエリ実⾏行行 • 毎⽇日1千以上のHiveユーザーが利利⽤用
11.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved トランザクション Insert, Update and Delete SQL Statements
12.
© Hortonworks Inc.
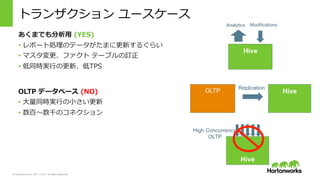
2011 – 2015. All Rights Reserved トランザクション ユースケース あくまでも分析⽤用 (YES) • レポート処理理のデータがたまに更更新するぐらい • マスタ変更更、ファクト テーブルの訂正 • 低同時実⾏行行の更更新、低TPS OLTP データベース (NO) • ⼤大量量同時実⾏行行の⼩小さい更更新 • 数百〜~数千のコネクション Hive OLTP Hive Replication Analytics Modifications Hive High Concurrency OLTP
13.
© Hortonworks Inc.
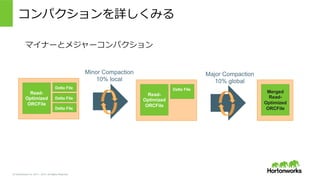
2011 – 2015. All Rights Reserved Deep Dive: トランザクション Hiveのトランザクション対応とACID • Hiveてのネイティブ対応 • フェーズに分けて: • Phase 1: Hive Streaming Ingest (append) • Phase 2: INSERT / UPDATE / DELETE Support • Phase 3: BEGIN / COMMIT / ROLLBACK Txn [Done] [Done] [Next] Read- Optimized ORCFile Delta File Merged Read- Optimized ORCFile 1. Original File Task reads the latest ORCFile Task Read- Optimized ORCFile Task Task 2. Edits Made Task reads the ORCFile and merges the delta file with the edits 3. Edits Merged Task reads the updated ORCFile Hive ACID Compactor periodically merges the delta files in the background.
14.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved コンパクションを詳しくみる Read- Optimized ORCFile Delta File Merged Read- Optimized ORCFile Read- Optimized ORCFile Delta File Delta File Delta File Minor Compaction 10% local Major Compaction 10% global マイナーとメジャーコンパクション
15.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved セキュリティ Hive Userʼ’s perspective
16.
© Hortonworks Inc.
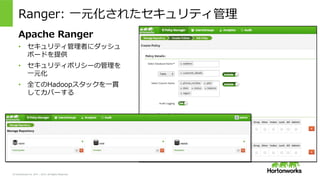
2011 – 2015. All Rights Reserved Ranger: ⼀一元化されたセキュリティ管理理 Apache Ranger • セキュリティ管理理者にダッシュ ボードを提供 • セキュリティポリシーの管理理を ⼀一元化 • 全てのHadoopスタックを⼀一貫 してカバーする
17.
© Hortonworks Inc.
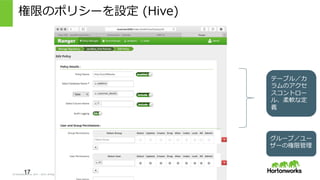
2011 – 2015. All Rights Reserved 権限のポリシーを設定 (Hive) 17 テーブル/カ ラムのアクセ スコントロー ル、柔軟な定 義 グループ/ユー ザーの権限管理理
18.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved 100倍早くなった仕組み ORC, Tez, CBO, Vectorization
19.
© Hortonworks Inc.
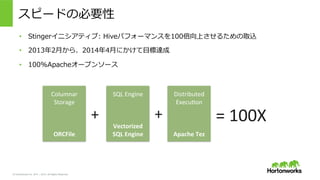
2011 – 2015. All Rights Reserved スピードの必要性 • Stingerイニシアティブ: Hiveパフォーマンスを100倍向上させるための取込 • 2013年年2⽉月から、2014年年4⽉月にかけて⽬目標達成 • 100%Apacheオープンソース SQL Engine Vectorized SQL Engine Columnar Storage ORCFile = 100X + + Distributed Execu>on Apache Tez
20.
© Hortonworks Inc.
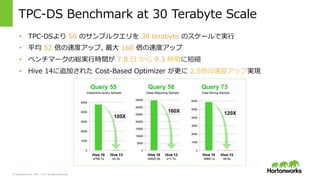
2011 – 2015. All Rights Reserved TPC-‐‑‒DS Benchmark at 30 Terabyte Scale • TPC-‐‑‒DSより 50 のサンプルクエリを 30 terabyte のスケールで実⾏行行 • 平均 52 倍の速度度アップ, 最⼤大 160 倍の速度度アップ • ベンチマークの総実⾏行行時間が 7.8 ⽇日 から 9.3 時間に短縮 • Hive 14に追加された Cost-‐‑‒Based Optimizer が更更に 2.5倍の速度度アップ実現
21.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved ORC ファイル フォーマット Columnar Storage for Hive
22.
© Hortonworks Inc.
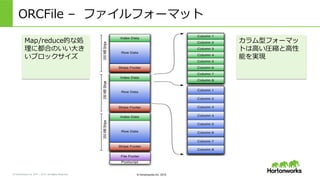
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 ORCFile – Hiveのためのカラム型ストレージ • カラム別にデータを格納 • データ型認識識 – データ型固有のエンコーダを使⽤用 – 統計情報も格納(min, max, sum, count) • 軽量量なインデックスつき – 関係のない⾏行行をスキップ Page 22
23.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 ORCFile – ファイルフォーマット Map/reduce的な処 理理に都合のいい⼤大き いブロックサイズ カラム型フォーマッ トは⾼高い圧縮と⾼高性 能を実現
24.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 ORCFile – テーブル定義の例例 • テーブルまたはパーティション別に定義 • 選べられる圧縮コーデック Page 24 create table Addresses ( name string, street string, city string, state string, zip int ) stored as orc tblproperties ("orc.compress"=”ZLIB");
25.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 ORCFile – テキストからORCに変換 • ORCを使わない理理由はない • SQL 1つでテキストからORCに変換 Page 25 -- Create Text & ORC tables CREATE TABLE test_details_txt( visit_id INT, store_id SMALLINT) STORED AS TEXTFILE; CREATE TABLE test_details_orc( visit_id INT, store_id SMALLINT) STORED AS ORC; -- Load into Text table LOAD DATA LOCAL INPATH '/home/user/test_details.csv' INTO TABLE test_details_txt; -- Copy to ORC table INSERT OVERWRITE INTO test_details_orc SELECT * FROM test_details_txt;
26.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Tez実⾏行行エンジン Beyond MapReduce
27.
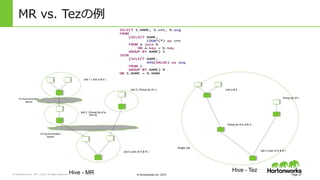
© Hortonworks Inc.
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 I/O Synchronization Barrier I/O Synchronization Barrier Job 1 ( Join a & b ) Job 3 ( Group by of c ) Job 2 (Group by of a Join b) Job 4 (Join of S & R ) Hive - MR MR vs. Tezの例例 Page 27 Single Job Hive - Tez Join a & b Group by of a Join b Group by of c Job 4 (Join of S & R )
28.
© Hortonworks Inc.
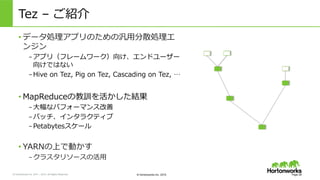
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 Tez – ご紹介 Page 28 • データ処理理アプリのための汎⽤用分散処理理エ ンジン – アプリ(フレームワーク)向け、エンドユーザー 向けではない – Hive on Tez, Pig on Tez, Cascading on Tez, … • MapReduceの教訓を活かした結果 – ⼤大幅なパフォーマンス改善 – バッチ、インタラクティブ – Petabytesスケール • YARNの上で動かす – クラスタリソースの活⽤用
29.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 Tez – MapReduceからの切切替 • コマンド1つでMapReduceからTezに切切替 Page 29 set hive.execution.engine=tez; SELECT * FROM my_table; • Hadoop 2なら、デフォルトをTezにしましょう $ vi hive-site.xml hive.execution.engine=tez
30.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Cost Based Optimizer Making the SQL smarter
31.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved 実⾏行行プラン – Cost Based Optimizer in Hive Cost-‐‑‒Based Optimizer (CBO) はHiveテーブルの統計情報を使って最適な実 ⾏行行プランを作成 なぜ cost-‐‑‒based optimization? • 利利⽤用は簡単 – 例例えば、Joinの順番を⾃自動調整してくれる • SQLチューニングの必要性を削減 • 効率率率な実⾏行行プランはクラスタの有効利利⽤用に繋がる Page 31
32.
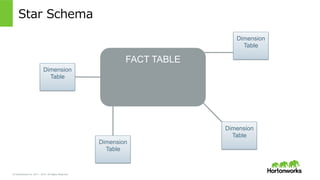
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Star Schema FACT TABLE Dimension Table Dimension Table Dimension Table Dimension Table
33.
© Hortonworks Inc.
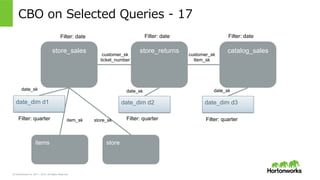
2011 – 2015. All Rights Reserved CBO on Selected Queries -‐‑‒ 17 store_sales store_returns catalog_sales items store date_dim d1 date_dim d2 date_dim d3 Filter: quarterFilter: quarterFilter: quarter Filter: dateFilter: dateFilter: date customer_sk ticket_number customer_sk Item_sk date_sk date_sk date_sk item_sk store_sk
34.
© Hortonworks Inc.
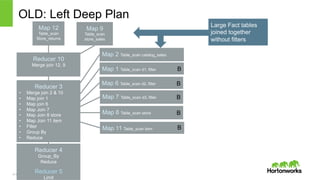
2011 – 2015. All Rights Reserved OLD: Left Deep Plan Reducer 3 • Merge join 2 & 10 • Map join 1 • Map join 6 • Map Join 7 • Map Join 8 store • Map Join 11 item • Filter • Group By • Reduce Map 12 Table_scan Store_returns Map 6 Table_scan d2, filter Map 7 Table_scan d3, filter Reducer 4 Group_By Reduce Reducer 10 Merge join 12, 9 Map 9 Table_scan store_sales Map 1 Table_scan d1, filter Map 2 Table_scan catalog_sales Reducer 5 Limit B B B Map 11 Table_scan item Map 8 Table_scan store B Large Fact tables joined together without filters B
35.
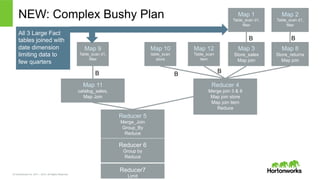
© Hortonworks Inc.
2011 – 2015. All Rights Reserved NEW: Complex Bushy Plan Reducer 4 Merge join 3 & 8 Map join store Map join item Reduce Map 10 table_scan store Map 12 Table_scan item Map 3 Store_sales Map join Map 8 Store_returns Map join Reducer 5 Merge_Join Group_By Reduce Map 11 catalog_sales, Map Join Map 9 Table_scan d1, filter Map 1 Table_scan d1, filter Map 2 Table_scan d1, filter Reducer 6 Group by Reduce Reducer7 Limit B B B B B All 3 Large Fact tables joined with date dimension limiting data to few quarters
36.
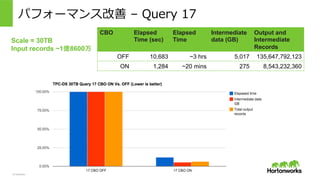
© Hortonworks Inc.
2011 – 2015. All Rights Reserved パフォーマンス改善 – Query 17 Scale = 30TB Input records ~1億8600万 CBO Elapsed Time (sec) Elapsed Time Intermediate data (GB) Output and Intermediate Records OFF 10,683 ~3 hrs 5,017 135,647,792,123 ON 1,284 ~20 mins 275 8,543,232,360
37.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 CBO – 有効にする • クエリを実⾏行行前にCBOを有効に Page 37 set hive.cbo.enable=true; set hive.compute.query.using.stats=true; set hive.stats.fetch.column.stats=true; set hive.stats.fetch.partition.stats=true; • 統計情報を更更新 ANALYZE TABLE my_table COMPUTE STATISTICS FOR COLUMNS;
38.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Vectorized Query Execution Process 1024 Rows at a Time
39.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 Vectorization – ベクターSQLエンジン • 機能: – 1⾏行行づつの代わりに、⼀一回に1024⾏行行を処理理 – モーデンなハードウェア アーキテクチャの活⽤用 • 利利点: – ⼤大きいクエリは最⼤大3倍早い – CPU使⽤用時間を削減、クラスタリソースの有効利利⽤用 Page 39
40.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved © Hortonworks Inc. 2015 Vectorization – 有効にする • ベクターSQLエンジンを有効に Page 40 set hive.vectorized.execution.enabled = true set hive.vectorized.execution.reduce.enabled = true; • ORCのみサポート • ⼀一部サポートしていないデータタイプや機能がある
41.
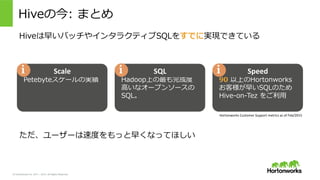
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Hiveの今: まとめ Hiveは早いバッチやインタラクティブSQLをすでに実現できている ただ、ユーザーは速度度をもっと早くなってほしい Petebyteスケールの実績 Scale i Hadoop上の最も完成度度 ⾼高いなオープンソースの SQL。 SQL i 90 以上のHortonworks お客様が早いSQLのため Hive-‐‑‒on-‐‑‒Tez をご利利⽤用 Speed i Hortonworks Customer Support metrics as of Feb/2015
42.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved 1秒以下のレスポンスを実現していく Solving Hiveʼ’s Top Performance Challenges
43.
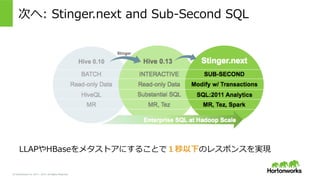
© Hortonworks Inc.
2011 – 2015. All Rights Reserved 次へ: Stinger.next and Sub-‐‑‒Second SQL LLAPやHBaseをメタストアにすることで1秒以下のレスポンスを実現
44.
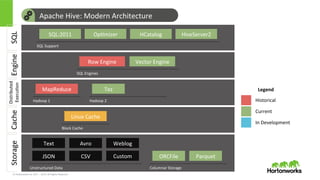
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Apache Hive: Modern Architecture Storage Columnar Storage ORCFile Parquet Unstructured Data JSON CSV Text Avro Custom Weblog Engine SQL Engines Row Engine Vector Engine SQL SQL Support SQL:2011 Op>mizer HCatalog HiveServer2 Cache Block Cache Linux Cache Distributed Execu>on Hadoop 1 MapReduce Hadoop 2 Tez Historical Current In Development Legend
45.
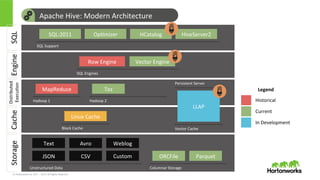
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Apache Hive: Modern Architecture Storage Columnar Storage ORCFile Parquet Unstructured Data JSON CSV Text Avro Custom Weblog Engine SQL Engines Row Engine Vector Engine SQL SQL Support SQL:2011 Op>mizer HCatalog HiveServer2 Cache Block Cache Linux Cache Distributed Execu>on Hadoop 1 MapReduce Hadoop 2 Tez Vector Cache LLAP Persistent Server Historical Current In Development Legend
46.
© Hortonworks Inc.
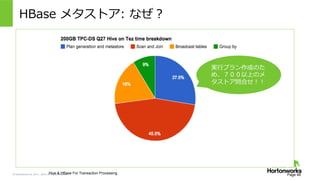
2011 – 2015. All Rights Reserved HBase メタストア: なぜ? Page 46Hive & HBase For Transaction Processing 実⾏行行プラン作成のた め、700以上のメ タストア問合せ!!
47.
© Hortonworks Inc.
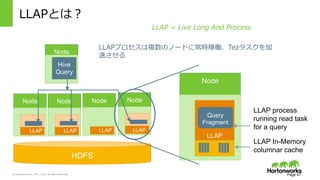
2011 – 2015. All Rights Reserved LLAPとは? Page 47 Node LLAP Process HDFS Query Fragment LLAP In-Memory columnar cache LLAP process running read task for a query LLAPプロセスは複数のノードに常時稼働、Tezタスクを加 速させる Node Hive Query Node NodeNode Node LLAP LLAP LLAP LLAP LLAP = Live Long And Process
48.
© Hortonworks Inc.
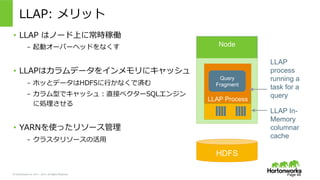
2011 – 2015. All Rights Reserved LLAP: メリット Page 48 • LLAP はノード上に常時稼働 – 起動オーバーヘッドをなくす • LLAPはカラムデータをインメモリにキャッシュ – ホッとデータはHDFSに⾏行行かなくで済む – カラム型でキャッシュ:直接ベクターSQLエンジン に処理理させる • YARNを使ったリソース管理理 – クラスタリソースの活⽤用 Node LLAP Process Query Fragment LLAP In- Memory columnar cache LLAP process running a task for a query HDFS
49.
© Hortonworks Inc.
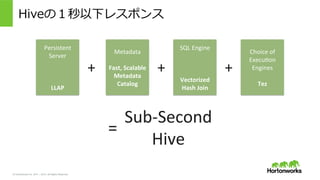
2011 – 2015. All Rights Reserved Hiveの1秒以下レスポンス = Sub-‐Second Hive Metadata Fast, Scalable Metadata Catalog Persistent Server LLAP + + SQL Engine Vectorized Hash Join Choice of Execu>on Engines Tez +
50.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved まとめ Hive Present and Future
51.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Hiveの今とこれから • HiveはSQL on Hadoopの標準 • バッチから、インタラクティブ処理理まで1つのSQLツールで • ETL、レポート、分析あらゆるSQLユースケースをHiveで • これからもHiveは進化していく • SQL:2011 Analytics標準対応 • トランザクション強化 • 1秒以下のクエリレスポンス
52.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved 今すぐHiveを • 今すぐHiveの最新機能を使いましょう • Hive on Tez • ORCファイル • CBOを有効に • ベクターSQLエンジン • ただ数⾏行行の設定変更更/SQLですぐ利利⽤用できます • これからのHive進化を楽しみに
53.
© Hortonworks Inc.
2011 – 2015. All Rights Reserved Thank you Yifeng Jiang, Solutions Engineer, Hortonworks @uprush
Download










![© Hortonworks Inc. 2011 – 2015. All Rights Reserved
Deep Dive: トランザクション
Hiveのトランザクション対応とACID
• Hiveてのネイティブ対応
• フェーズに分けて:
• Phase 1: Hive Streaming Ingest (append)
• Phase 2: INSERT / UPDATE / DELETE Support
• Phase 3: BEGIN / COMMIT / ROLLBACK Txn
[Done]
[Done]
[Next]
Read-
Optimized
ORCFile
Delta File
Merged
Read-
Optimized
ORCFile
1. Original File
Task reads the latest
ORCFile
Task
Read-
Optimized
ORCFile
Task Task
2. Edits Made
Task reads the ORCFile and merges
the delta file with the edits
3. Edits Merged
Task reads the
updated ORCFile
Hive ACID Compactor
periodically merges the delta
files in the background.](https://image.slidesharecdn.com/hive-present-and-feature-db-tech-showcase-yifeng-150611043617-lva1-app6891/85/Apache-Hive-13-320.jpg)




























![[Modern Cloud Day Tokyo 2019] オラクルコンサルが語る!事例でみていくOracle Cloud Infrastructure設...](https://cdn.slidesharecdn.com/ss_thumbnails/mcd19o-2-190822001458-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[db tech showcase Tokyo 2015] C15:DevOps MySQL in カカクコム~ OSSによる可用性担保とリアルタイムパフ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c15mysqlkakaku-150618053752-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B36:Hitachi Advanced Data Binder 実践SQLチューニング方法 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b36hadbhitachi-150619110029-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C17:MySQL Cluster ユーザー事例紹介~JR東日本情報システム様における導入事例...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c17mysql-clusterhp-150619091220-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DB tech showcase Tokyo 2015] B37 :オンプレミスからAWS上のSAP HANAまで高信頼DBシステム構築にHAクラスタリ...](https://cdn.slidesharecdn.com/ss_thumbnails/b37dbtechshowcasetokyo2015haclusteringsoftware20150612-150611165311-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] C32:「データ一貫性にこだわる日立のインメモリ分散KVS~こだわりの理由と実現方法とは~」 ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c32kvshitachi-150619110419-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] D13:PCIeフラッシュで、高可用性高性能データベースシステム?! by 株式会社HGSTジ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d13hardwareflashhgst-150629025827-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D32:HPの全方位インメモリDB化に向けた取り組みとSAP HANAインメモリDB の効果を...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d32in-memorysap-hanahp-150619092635-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B27:インメモリーDBとスケールアップマシンによりBig Dataの課題を解決する by S...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b27sap-hanasap-japan-150618080033-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] B34:データの仮想化を具体化するIBMのロジカルデータウェアハウス by 日本アイ・ビー・エ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b34hadoopibm-150629025630-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D16:マイケルストーンブレーカー発の超高速データベースで実現する分析基盤の簡単構築・運用ステ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d16verticahp-150619081330-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] D23:MySQLはドキュメントデータベースになり、HTTPもしゃべる - MySQL Lab...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d23mysqloracle-mysqlgbu-150619101210-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] C16:Oracle Disaster Recovery at New Zealand sto...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015c16oracledbvisit-softwareinsight-technology-150619090553-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)

![[db tech showcase Tokyo 2015] D25:The difference between logical and physical...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015d25oracledbvisit-software-150619090737-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] B24:最高峰の可用性 ~NonStop SQLが止まらない理由~ by 日本ヒューレット・パ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015b24nonstop-sqlhp-150619075240-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] A33:Amazon Aurora Deep Dive by アマゾン データ サービス ジャ...](https://cdn.slidesharecdn.com/ss_thumbnails/dbts-tokyo-2015a34amazon-auroraamazondataservicejapan-150623010528-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)
![[db tech showcase Tokyo 2015] E35: Web, IoT, モバイル時代のデータベース、Apache Cassandraを学ぼう](https://cdn.slidesharecdn.com/ss_thumbnails/e35cassandra-150624022814-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)















![[Oracle Innovation Summit Tokyo 2018] 水環境の持続を支えるクラウド型ICTプラットフォーム「Water Busine...](https://cdn.slidesharecdn.com/ss_thumbnails/ist18a-2-180822044642-thumbnail.jpg?width=640&height=640&fit=bounds)






















