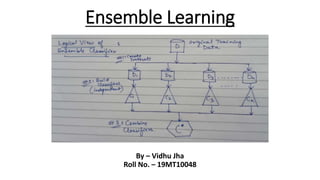
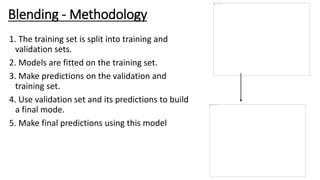
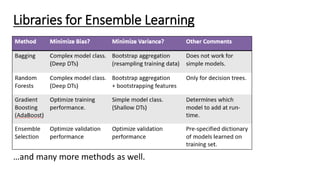
This document discusses ensemble learning techniques. Ensemble learning combines multiple machine learning models to obtain better predictive performance than a single model. Basic techniques include majority voting, averaging predictions, and weighted averaging. Advanced techniques include stacking, blending, bagging, and boosting. Stacking uses predictions from base models as input to a meta-model. Blending uses a holdout set and base model predictions to build a final model. Bagging creates random subsets of data to train base models on. Boosting sequentially trains models to focus on examples previously misclassified. These ensemble methods can reduce bias and variance to create stronger learners from weak ones.











































![ensemblelearning-181220105413[1].pptxwdewf](https://cdn.slidesharecdn.com/ss_thumbnails/ensemblelearning-1812201054131-251224052506-1976e79c-thumbnail.jpg?width=640&height=640&fit=bounds)

































