More Related Content

PPTX
iostat await svctm の 見かた、考え方 
PDF
MHA for MySQLとDeNAのオープンソースの話 
PPTX

PDF
分散トレーシング技術について(Open tracingやjaeger) 
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~ 
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発... 
PPTX

PPTX
What's hot

PDF
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料) 
PPTX

PPTX

PPTX

PPT

PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019) 
PPTX
RDB開発者のためのApache Cassandra データモデリング入門 
PDF

PDF
ヤフー社内でやってるMySQLチューニングセミナー大公開 
PDF

PDF

PDF
AWS Black Belt Online Seminar Amazon Aurora 
PDF
忙しい人の5分で分かるDocker 2017年春Ver 
PDF
今からでも遅くないDBマイグレーション - Flyway と SchemaSpy の紹介 - ![[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス](https://cdn.slidesharecdn.com/ss_thumbnails/amazonauroratips-170307140000-thumbnail.jpg?width=640&height=640&fit=bounds)
PDF
[Aurora事例祭り]Amazon Aurora を使いこなすためのベストプラクティス 
PDF
Apache Arrow - データ処理ツールの次世代プラットフォーム 
PPTX
祝!PostgreSQLレプリケーション10周年!徹底紹介!! 
PPTX
その Pod 突然落ちても大丈夫ですか!?(OCHaCafe5 #5 実験!カオスエンジニアリング 発表資料) 
PDF
SQLアンチパターン 幻の第26章「とりあえず削除フラグ」 
PPTX
ポスト・ラムダアーキテクチャの切り札? Apache Hudi(NTTデータ テクノロジーカンファレンス 2020 発表資料) Similar to Cassandraのしくみ データの読み書き編

PDF
Guide to Cassandra for Production Deployments 
PPTX

PDF
InfoTalk springbreak_2012 
PPTX

PDF
Scalable Cooperative File Caching with RDMA-Based Directory Management 
PPTX

PPTX
Coherenceを利用するときに気をつけること #OracleCoherence 
DOC

PDF
2010/07/09 osc kansai-kvsokuyama 
PDF
Cassandraのトランザクションサポート化 & web2pyによるcms用プラグイン開発 
PDF
cassandra 100 node cluster admin operation 
PDF

PDF
20110517 okuyama ソーシャルメディアが育てた技術勉強会 
PPTX

PDF
gumiStudy#1 キーバリューストアのご紹介と利用時の設計モデルについて 
PDF
voldemortの技術 - Dynamoとの比較 
PPT

PDF

PPTX
Hadoopソースコードリーディング8/MapRを使ってみた 
PPTX
Cassandra Summit 2016 注目セッション報告 More from Yuki Morishita

PPTX

PDF
DataStax EnterpriseでApache Tinkerpop入門 
PDF
Apache tinkerpopとグラフデータベースの世界 
PPTX
DataStax Enterpriseによる大規模グラフ解析 
PPTX
サンプルアプリケーションで学ぶApache Cassandraを使ったJavaアプリケーションの作り方 
PPTX
サンプルで学ぶCassandraアプリケーションの作り方 
PPTX
分散グラフデータベース DataStax Enterprise Graph 
PPTX

PDF
Datastax Enterpriseをはじめよう 
PDF
How you can contribute to Apache Cassandra 
PDF
Cassandraのしくみ データの読み書き編
- 1.
- 2.
翻訳者募集中 ! 森下雄貴 @yukim Cassandra wiki 翻訳に参加してます http:// wiki.apache.org/cassandra/FrontPage_JP - 3.
- 4.
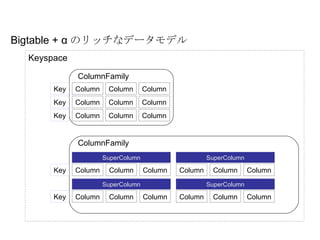
Bigtable + αのリッチなデータモデル Keyspace ColumnFamily Column Column Column Column Column Column Column Column Column Key Key Key ColumnFamily Column Column Column Key Key SuperColumn Column Column Column SuperColumn Column Column Column SuperColumn Column Column Column SuperColumn - 5.
- 6.
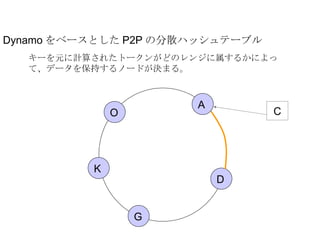
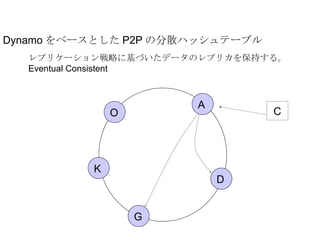
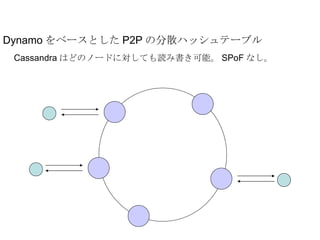
Dynamo をベースとした P2Pの分散ハッシュテーブル レプリケーション戦略に基づいたデータのレプリカを保持する。 Eventual Consistent A D G K O C - 7.
- 8.
操作ごとに制御可能な一貫性レベル W +R > N W: 書き込み時のレベル R: 読み込み時のレベル N: レプリカ数 強い一貫性が得られる ZERO ANY ONE QUORUM (N/2 + 1) ALL ZERO ANY ONE QUORUM (N/2 + 1) ALL Read Write - 9.
- 10.
- 11.
- 12.
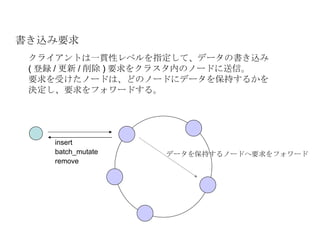
書き込み要求 トークンを計算し、データを保持するノードを決定 レプリケーションを保持するノードを決定Hinted Handoff の必要性を検証 一貫性レベルに応じて挙動がかわる。 を行い書き込み要求をフォワードするノードを決定。 ( ローカルの場合もある ) ZERO 非同期でフォワードを行う。クライアントにすぐ返るが、何も保証されない。 ANY 以上 指定された一貫性レベルの数だけフォワード先からレスポンスが返った場合のみクライアントにレスポンスを返す。どこかでエラーが発生したら TimeoutException 。 - 13.
1. トークンを計算し、データを保持するノードを決定 <Partitioner>org.apache.cassandra.dht.RandomPartitioner </Partitioner> プラッガブル パーティショニング方法 (IPartitioner の実装 ) に基づいてどのノードに属するデータかを決定 RandomPartitioner キーの MD5 ハッシュを元にトークン生成。 OrderingPreservedPartitioner CollatingOrderPreservingPartitioner - 14.
2. レプリケーションを保持するノードを決定レプリケーション戦略 RackUnawareStrategy RackAwareStrategy DatacenterShardStrategy こちらもプラッガブル <ReplicaPlacementStrategy> org.apache.cassandra.locator.RackUnawareStrategy </ReplicaPlacementStrategy> - 15.
3. Hinted Handoffの必要性を判定 ノード故障の判定 本来そのデータを保持するはずだったノードの情報( Hint) をつけて、別のノードにそのデータを格納しておく。 Hinted Handoff を受けとったノードは本来保持するノードのアドレスを SYSTEM テーブルへ保持。 Hinted Handoff “ ϕ accrual failure detector” - ϕ 漸増型故障検出器 - 16.
- 17.
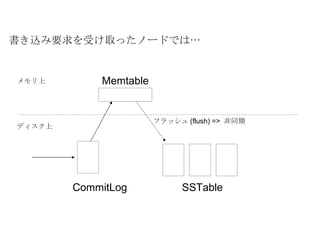
設定 ( デフォルト:128MB) されたサイズに到達するとログがローテートされる コミットログヘッダ RowMutation + チェックサム (CRC32) CF ごとのダーティフラグ CF ごとのファイルポジション リプレイを開始するポジション リプレイが必要か CommitLog セグメント CommitLog すべての書き込み操作 (RowMutation) を記録。 すべての ColumnFamiliy の Memtable が SSTable に書き込まれたら削除される。 ノード起動時に CommitLog があればリカバリーが実行される。リカバリー後は強制フラッシュされ、一旦 CommitLog はクリア。 RowMutation + チェックサム (CRC32) RowMutation + チェックサム (CRC32) - 18.
periodic ( デフォルト) CommitLog への書き込みは待たず、 Memtable へ書き込みに行く。 < CommitLogSyncPeriodInMS > で指定されたミリ秒ごとに CommitLog への書き込みバッファをデバイスへ書き込み。 batch CommitLog への書き込み完了を待ってから、 Memtable へ書き込みに行く。 < CommitLogSyncBatchWindowInMS > ??? <CommitLogSync> CommitLog <CommitLogDirectory> <CommitLogRotationThresholdInMB> CommitLog をローテートする閾値 CommitLog を保持するディレクトリ - 19.
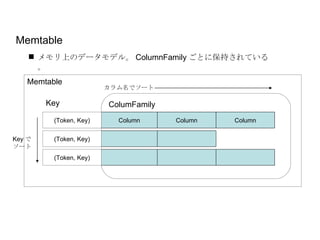
Memtable Key ColumnColumn Column Token で ソート カラム名でソート Memtable メモリ上のデータモデル。 ColumnFamily ごとに保持されている。 (Token, Key) ColumFamily (Token, Key) (Token, Key) OrderPreservingPartitioner のみ キーでのソートが保証される - 20.
Memtable < MemtableThroughputInMB> < MemtableFlushAfterMinutes > < MemtableOperationsInMillions > フラッシュされるまでの閾値。 保持されるカラム数の最大値 ( デフォルト : 0.3) フラッシュされるまでの閾値。 Memtable に対して行われた操作の総データ量 ( デフォルト : 64) フラッシュされるまでの閾値。 この時間がたってもまだフラッシュされていなければ強制フラッシュ。 本番環境では多めに設定しておいたほうが良い。 ( デフォルト : 60) - 21.
Memtable が閾値を超えると、 非同期でMemtable の内容がディスクに書き出される。その際 Bloom Filter 、 Index が一緒にディスクに書き出される。 一度書き出したら不変。 コンパクション (Compaction) で複数の SSTable を 1 つにまとめられる。 SSTable Bloom Filter Index Data Memtable の内容が格納されたデータファイル。 あるキーがデータファイルに存在するか ( ただし偽陽性 ) をコンパクトに 知るためのファイル。 ( おそらく ) キーに対応するデータの位置を保存。 - 22.
マイナーコンパクション 同じ程度のサイズの SSTableを 1 つにまとめる。 メジャーコンパクション 1 つにマージ。 コンパクション (Compaction) 2 種類のコンパクション ディスクの残りに注意 すべての SSTable ファイルをマージして新しくファイルを作成したあと、元の SSTable ファイルを削除する。 容量が足りない場合はコンパクションが行われない。 ( ログにエラー出力 ) ディスクの残量に注意 ! - 23.
- 24.
- 25.
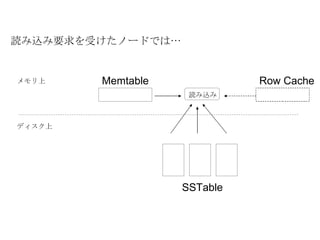
読み込み要求 一貫性レベルに応じて挙動がかわる。 ONEトークンを計算し、データを保持する一番近いノードを決定。 そのノードに読み取り要求を送信。 データを受け取ったらクライアントに返す。 QUORUM 以上 トークンを計算し、データを保持する一番近いノードを決定。 レプリケーションを保持するノードを決定。 一番近いノードにデータの読み取り要求を送信。ほかのノードにはダイジェストのみの読み取り要求を送信。 一貫性レベルで指定された数のレスポンスが返ってくるまで待つ。 ダイジェストが一致していれば、読み取ったデータをクライアントに返す。 ダイジェストに不一致があれば実データを読み込みにいき、 Read Repair を実行。 - 26.
- 27.
- 28.
Row Cache 1行分のデータをキャッシュ。たとえ 1 部のカラムの値のみの問い合わせてもすべてのカラムをキャッシュとして保持する。 デフォルトではオフ。 Key Cache(0.6.0 から ) SSTable 内のデータの位置をキャッシュ。 キャッシュ Cassandra は 2 種類のキャッシュを備える - 29.
Bloom Filter 、Index の活用 Memtable 、 SSTable からの読み込み すべての SSTable ファイルからあるキーを探し出す必要があるため、極力ムダを省きたい。 まず Bloom Filter をチェックし、読み込む SSTable のファイルを絞り込む。 - 30.
まとめ Cassandra は内部的にCommitLog 、 Memtable 、 SSTable の 3 つの物理的なデータ構造を持っている。 書き込みは CommitLog への追記 + Memtable への書き込みで終了、なので高速。 読み込み時は Memtable と全ての SSTable からデータを探すので若干遅い。けど Bloom Filter 、 Cache 等で工夫して高速化している。 内部構造を知っておいた方が環境構築にもデータモデルの設計にも運用にも役立つはず。