Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Ryuji Tamagawa
PDF, PPTX
4,357 views
Apache Sparkの紹介
このところ長崎とか博多とか神戸でしゃべったSparkの話の資料です。
Software
◦
Read more
31
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 34
2
/ 34
3
/ 34
4
/ 34
5
/ 34
6
/ 34
7
/ 34
8
/ 34
9
/ 34
10
/ 34
11
/ 34
12
/ 34
13
/ 34
14
/ 34
15
/ 34
16
/ 34
17
/ 34
18
/ 34
19
/ 34
20
/ 34
21
/ 34
22
/ 34
23
/ 34
24
/ 34
25
/ 34
26
/ 34
27
/ 34
28
/ 34
29
/ 34
30
/ 34
31
/ 34
32
/ 34
33
/ 34
34
/ 34
More Related Content
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
PPTX
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
PPTX
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PDF
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
PPTX
PostgreSQL14の pg_stat_statements 改善(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
Apache Sparkの基本と最新バージョン3.2のアップデート(Open Source Conference 2021 Online/Fukuoka ...
by
NTT DATA Technology & Innovation
PostgreSQLモニタリングの基本とNTTデータが追加したモニタリング新機能(Open Source Conference 2021 Online F...
by
NTT DATA Technology & Innovation
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
Deep Dive into Spark SQL with Advanced Performance Tuning
by
Takuya UESHIN
PostgreSQL14の pg_stat_statements 改善(第23回PostgreSQLアンカンファレンス@オンライン 発表資料)
by
NTT DATA Technology & Innovation
What's hot
PPTX
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
PPTX
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
PDF
Apache Airflow入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
PDF
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
PDF
Spark Streaming + Amazon Kinesis
by
Yuta Imai
PDF
Hadoop入門
by
Preferred Networks
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
PDF
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
PDF
大規模ソーシャルゲーム開発から学んだPHP&MySQL実践テクニック
by
infinite_loop
PDF
5分で分かるgitのrefspec
by
ikdysfm
PDF
今からでも遅くないDBマイグレーション - Flyway と SchemaSpy の紹介 -
by
onozaty
PPTX
Apache Avro vs Protocol Buffers
by
Seiya Mizuno
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Dockerfile を書くためのベストプラクティス解説編
by
Masahito Zembutsu
PPTX
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
例外設計における大罪
by
Takuto Wada
PDF
RDF Semantic Graph「RDF 超入門」
by
オラクルエンジニア通信
大量のデータ処理や分析に使えるOSS Apache Sparkのご紹介(Open Source Conference 2020 Online/Kyoto ...
by
NTT DATA Technology & Innovation
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
コンテナの作り方「Dockerは裏方で何をしているのか?」
by
Masahito Zembutsu
はじめてのElasticsearchクラスタ
by
Satoyuki Tsukano
Apache Airflow入門 (マーケティングデータ分析基盤技術勉強会)
by
Takeshi Mikami
Hadoop/Spark を使うなら Bigtop を使い熟そう! ~並列分散処理基盤のいま、から Bigtop の最近の取り組みまで一挙ご紹介~(Ope...
by
NTT DATA Technology & Innovation
Spark Streaming + Amazon Kinesis
by
Yuta Imai
Hadoop入門
by
Preferred Networks
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
何となく勉強した気分になれるパーサ入門
by
masayoshi takahashi
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
大規模ソーシャルゲーム開発から学んだPHP&MySQL実践テクニック
by
infinite_loop
5分で分かるgitのrefspec
by
ikdysfm
今からでも遅くないDBマイグレーション - Flyway と SchemaSpy の紹介 -
by
onozaty
Apache Avro vs Protocol Buffers
by
Seiya Mizuno
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Dockerfile を書くためのベストプラクティス解説編
by
Masahito Zembutsu
NTTデータが考えるデータ基盤の次の一手 ~AI活用のために知っておくべき新潮流とは?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
例外設計における大罪
by
Takuto Wada
RDF Semantic Graph「RDF 超入門」
by
オラクルエンジニア通信
Similar to Apache Sparkの紹介
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PPTX
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
by
Tanaka Yuichi
PPTX
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
PDF
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
PDF
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
PDF
ビッグじゃなくても使えるSpark Streaming
by
chibochibo
PDF
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PDF
Hadoopとは
by
Hirokazu Yatsunami
PDF
ちょっと理解に自信がないなという皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
PDF
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
PPTX
JP version - Beyond Shuffling - Apache Spark のスケールアップのためのヒントとコツ
by
Holden Karau
PDF
20161125 Asakusa Framework Day オラクル講演資料
by
オラクルエンジニア通信
PDF
Spark at Scale
by
Yuta Imai
PDF
Spark shark
by
Tsuyoshi OZAWA
PDF
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
PDF
[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29
by
The Hive
PDF
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
by
日本ヒューレット・パッカード株式会社
PDF
20160127三木会 RDB経験者のためのspark
by
Ryuji Tamagawa
PDF
Oracle Big Data Cloud Serviceのご紹介
by
オラクルエンジニア通信
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
ApacheSparkを中心としたOSSビッグデータ活用と導入時の検討ポイント
by
Tanaka Yuichi
Spark Summit 2014 の報告と最近の取り組みについて
by
Recruit Technologies
Introduction to Hadoop and Spark (before joining the other talk) and An Overv...
by
DataWorks Summit/Hadoop Summit
開発中の新機能 Spark Declarative Pipeline に飛びついてみたが難しかった(JEDAI DAIS Recap#2 講演資料)
by
NTT DATA Technology & Innovation
ビッグじゃなくても使えるSpark Streaming
by
chibochibo
ビッグデータ活用を加速する!分散SQLエンジン Spark SQL のご紹介 20161105 OSC Tokyo Fall
by
YusukeKuramata
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
Hadoopとは
by
Hirokazu Yatsunami
ちょっと理解に自信がないなという皆さまに贈るHadoop/Sparkのキホン (IBM Datapalooza Tokyo 2016講演資料)
by
hamaken
クラウドストレージの基礎知識(Cloudian white paper)
by
CLOUDIAN KK
JP version - Beyond Shuffling - Apache Spark のスケールアップのためのヒントとコツ
by
Holden Karau
20161125 Asakusa Framework Day オラクル講演資料
by
オラクルエンジニア通信
Spark at Scale
by
Yuta Imai
Spark shark
by
Tsuyoshi OZAWA
Apache Spark 1000 nodes NTT DATA
by
NTT DATA OSS Professional Services
[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29
by
The Hive
Hadoop/AI基盤における考慮点、PoCの進め方、基盤構成例
by
日本ヒューレット・パッカード株式会社
20160127三木会 RDB経験者のためのspark
by
Ryuji Tamagawa
Oracle Big Data Cloud Serviceのご紹介
by
オラクルエンジニア通信
More from Ryuji Tamagawa
PDF
20171012 found IT #9 PySparkの勘所
by
Ryuji Tamagawa
PDF
20170927 pydata tokyo データサイエンスな皆様に送る分散処理の基礎の基礎、そしてPySparkの勘所
by
Ryuji Tamagawa
PPTX
hbstudy 74 Site Reliability Engineering
by
Ryuji Tamagawa
PDF
PySparkの勘所(20170630 sapporo db analytics showcase)
by
Ryuji Tamagawa
PDF
20170210 sapporotechbar7
by
Ryuji Tamagawa
PDF
20161215 python pandas-spark四方山話
by
Ryuji Tamagawa
PDF
20161004 データ処理のプラットフォームとしてのpythonとpandas 東京
by
Ryuji Tamagawa
PDF
20160708 データ処理のプラットフォームとしてのpython 札幌
by
Ryuji Tamagawa
PDF
20151205 Japan.R SparkRとParquet
by
Ryuji Tamagawa
PDF
Performant data processing with PySpark, SparkR and DataFrame API
by
Ryuji Tamagawa
PDF
足を地に着け落ち着いて考える
by
Ryuji Tamagawa
PDF
ヘルシープログラマ・翻訳と実践
by
Ryuji Tamagawa
PDF
Google Big Query
by
Ryuji Tamagawa
PDF
BigQueryの課金、節約しませんか
by
Ryuji Tamagawa
PDF
You might be paying too much for BigQuery
by
Ryuji Tamagawa
PDF
Google BigQueryについて 紹介と推測
by
Ryuji Tamagawa
PDF
lessons learned from talking at rakuten technology conference
by
Ryuji Tamagawa
PDF
丸の内MongoDB勉強会#20LT 2.8のストレージエンジン動かしてみました
by
Ryuji Tamagawa
PDF
Mongo dbを知ろう devlove関西
by
Ryuji Tamagawa
PDF
Seleniumをもっと知るための本の話
by
Ryuji Tamagawa
20171012 found IT #9 PySparkの勘所
by
Ryuji Tamagawa
20170927 pydata tokyo データサイエンスな皆様に送る分散処理の基礎の基礎、そしてPySparkの勘所
by
Ryuji Tamagawa
hbstudy 74 Site Reliability Engineering
by
Ryuji Tamagawa
PySparkの勘所(20170630 sapporo db analytics showcase)
by
Ryuji Tamagawa
20170210 sapporotechbar7
by
Ryuji Tamagawa
20161215 python pandas-spark四方山話
by
Ryuji Tamagawa
20161004 データ処理のプラットフォームとしてのpythonとpandas 東京
by
Ryuji Tamagawa
20160708 データ処理のプラットフォームとしてのpython 札幌
by
Ryuji Tamagawa
20151205 Japan.R SparkRとParquet
by
Ryuji Tamagawa
Performant data processing with PySpark, SparkR and DataFrame API
by
Ryuji Tamagawa
足を地に着け落ち着いて考える
by
Ryuji Tamagawa
ヘルシープログラマ・翻訳と実践
by
Ryuji Tamagawa
Google Big Query
by
Ryuji Tamagawa
BigQueryの課金、節約しませんか
by
Ryuji Tamagawa
You might be paying too much for BigQuery
by
Ryuji Tamagawa
Google BigQueryについて 紹介と推測
by
Ryuji Tamagawa
lessons learned from talking at rakuten technology conference
by
Ryuji Tamagawa
丸の内MongoDB勉強会#20LT 2.8のストレージエンジン動かしてみました
by
Ryuji Tamagawa
Mongo dbを知ろう devlove関西
by
Ryuji Tamagawa
Seleniumをもっと知るための本の話
by
Ryuji Tamagawa
Apache Sparkの紹介
1.
ビッグデータ処理の プラットフォームとして注目されている Apache Sparkのご紹介 玉川竜司
2.
本日の内容 • 少しだけ自己紹介 • Hadoopとそのエコシステムの説明 •
Sparkの概要説明
3.
少しだけ自己紹介 • 大阪のソフトウェア開発企業 (Sky株式会社)勤務。 • コンピュータの技術書翻訳を やってます。 •
ビッグデータ、ソフトウェア開 発に関する本が中心。
4.
既刊書の一部
5.
今年の本 7月 8月 年内
6.
「ビッグデータ」の定義 • 実は広く認められている定義はない • マーケティング的には言ったもん勝ち的な・・・ •
純粋に量のこともあれば、レコード数のこともある • 個人的には「数台のサーバーでは扱いきれない量のデータ」 という感覚を持っています • 技術的には、運用上障害の発生の可能性が無視できなくな ると、一気に難易度が上がる
7.
Hadoopの登場
8.
2000年頃の状況 • もくろみ:山盛りのデータを捨てずに活用したらいいことあるのでは? • 状況:そうはいってもコストが合わない。 コンピュータ単体の性能向上は行き詰まり気味。 •
ブレークスルー : スケールアウト型の分散処理フレームワーク。 ブレークスルーになったのが GoogleのGFS / MapReduce
9.
Hadoopが実現・解決したこと 多台数のPCによる分散処理のカジュアル化 「それまでに比べれば」はるかに低いコスト・労力で、 分散処理が利用可能に
10.
Hadoop 0.x • 分散ファイルシステム:HDFS •
分散コンピューティングフレー ムワーク:MapReduce • 生MapReduceでプログラムを書 くのは非常に大変 HadoopRDB OS ファイルI/O メモリバッファ クエリ実行エンジン SQL ドライバ OS HDFS MapReduce 注:この対比はちょっと無理矢理です
11.
Hadoop 1.x • HBase(NoSQLデータベース)、 Hive(SQLクエリエンジン)など が登場し、エコシステムができは じめる HadoopRDB OS ファイルI/O メモリバッファ クエリ実行エンジン SQL ドライバ OS HDFS Hive
e.t.c. HBase MapReduce ドライバ
12.
HBase • HDFS上で動作するNoSQLデータベースエ ンジン • 「生」のHadoop(HDFS)は徹底した バッチ指向で、大量のデータをまとめて 書き、一気に読み込んで処理をすること に対してチューニングされている。 •
これに対し、HBaseはHDFSを基盤にしつ つも、小さいデータのランダムな書き込 み・更新・読み取りに高い性能を発揮で きる。スケーラビリティも極めて高い。
13.
Hive • HDFS+MapReduce上で動作するSQLクエリエ ンジン • MapReduceは処理のスケーラビリティや耐障 害性を担保するものの、「生」MapReduceは プログラミングが大変 •
おなじみのSQLを使って、HDFS上に保存され ているデータに対してアクセスできるようになっ た • しかし意外と速くない(特に小さいクエリ) ことが問題視されることに・・・ • Schema on Read関連はエコシステムの他の ツールからも利用されます
14.
Hadoop 2.x • クラスタのリソースマネージャー としてYARN(Yet
Another Resource Manager)が登場、 MapReduce以外の分散コンピュー ティングフレームワークの誕生の 素地となる • そして新たに登場したのがSpark • 別のトレンドとして、インメモリ 系のSQLエンジンが増えてきた OS HDFS Hive e.t.c. HBaseMapReduce YARN Spark (Spark Streaming, MLlib, GraphX, Spark SQL) 注:この階層図は技術的に正確ではありません。 複雑すぎて正確に描くことはたぶん無理・・・ Impalaなど (インメモ リ系SQL) 「Hadoopって何?」という問いに対する答はどんどん難しく なっていて、狭義ではHDFS+YARN+MapReduceあたりで す。ただ、全部ひっくるめて「エコシステム」と表現するこ とが多くなりました。
15.
ここからSparkの話
16.
Sparkとは • 分散処理のコンピューティングフレームワーク • あえて言うなら相当するのはMapReduceのところ •
特徴となるのは高速性とプログラミングの容易さ OS HDFS Hive e.t.c. HBaseMapReduce YARN Impalaなど (インメモ リ系SQL) Spark (Spark Streaming, MLlib, GraphX, Spark SQL)
17.
Sparkとは • エンジンそのものはScalaで書かれています。 • ScalaはJVM上で動作する関数型言語で、型推論や高度なデー タ型をサポートしているおり、複雑なアルゴリズムを簡潔なコー ドで表現できます。 •
Spark上で動作するアプリケーションを書くための言語として は、Scala、Java、Pythonが標準。ただし、Javaはコードが 冗長になりがちで、Pythonはいろいろと制約があります。
18.
Sparkの狙い • CPUの利用効率の向上 • Hadoop(HDFS+MapReduce)ではCPUを使い切れていなかった •
mapフェーズ、reduceフェーズごとのHDFSへのI/OとJVMの起動 が問題 • 抽象度の高いプログラミングモデルの提供による開発効率の向上 • インタラクティブな利用(Spark-shellやPySpark、SparkR、Spark- SQLなど)からバッチ処理までサポートする
19.
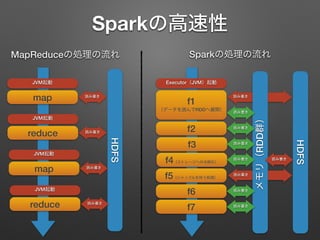
Sparkの高速性 map JVM起動 読み書き HDFS reduce JVM起動 読み書き map JVM起動 読み書き reduce JVM起動 読み書き f1 (データを読んでRDDへ展開) Executor(JVM)起動 HDFS 読み書き f2 f3 f4(ストレージへの永続化) f5(シャッフルを伴う処理) 読み書き f6 f7 MapReduceの処理の流れ Sparkの処理の流れ メモリ(RDD群) 読み書き 読み書き 読み書き 読み書き 読み書き 読み書き 読み書き
20.
開発の容易性 public void map(….)
… { String line = value.toString(); StringTokenizer tokenizer = new StringTokenizer(line); while (tokenizer.hasMoreTokens()) { word.set(tokenizer.nextToken()); output.collect(word, one); } } public void reduce(…) … { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); } val textFile = spark.textFile("hdfs://...") val counts = textFile.flatMap(line => line.split(" ")) .map(word => (word, 1)) .reduceByKey(_ + _) counts.saveAsTextFile("hdfs://...") Spark MapReduce シェルから 直接実行可能
21.
Sparkの様々なモジュール Spark SQL (DataFrameAPI) RDDをデータベースのテーブルのように扱うためのモジュー ル。SQL(HiveQL)でRDDのデータにアクセスできる。1.4 からは、さらに汎用的なDataFrame APIが提供されている。 Spark
Streaming ストリーミングデータ処理を行うためのモジュール。センサ ーデータなどの処理に。 MLlib 機械学習のライブラリ。特に並列処理が活用できるアルゴリ ズムを中心に、活発に開発が続けられている。 GraphX グラフデータベースのモジュール。
22.
Sparkの動作環境 • ローカルモード(単一のPCでも一応動作します。開発OK) • Standaloneクラスタ(10台くらいまでならなんとか使えるかも。た だし分散ストレージがないのはハンデ) •
本命はYARN(Hadoop 2.x)上での運用 • Mesos(Apache Software Foundationのクラスタマネージャ)上で も動作するものの、ケースとしては少なさそう
23.
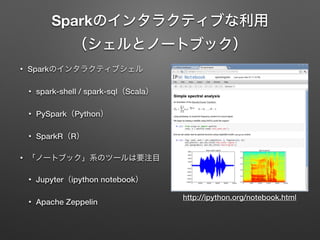
Sparkのインタラクティブな利用 (シェルとノートブック) • Sparkのインタラクティブシェル • spark-shell
/ spark-sql(Scala) • PySpark(Python) • SparkR(R) • 「ノートブック」系のツールは要注目 • Jupyter(ipython notebook) • Apache Zeppelin http://ipython.org/notebook.html
24.
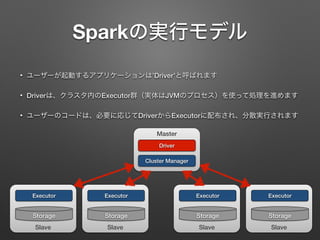
Sparkの実行モデル • ユーザーが起動するアプリケーションは’Driver’と呼ばれます • Driverは、クラスタ内のExecutor群(実体はJVMのプロセス)を使って処理を進めます •
ユーザーのコードは、必要に応じてDriverからExecutorに配布され、分散実行されます Slave Executor Storage Master Driver Cluster Manager Slave Executor Storage Slave Executor Storage Slave Executor Storage
25.
SparkR • Rの強み:豊富なライブラリ、既存のユーザー • Hadoop/Sparkの強み:スケーラビリティ •
SparkR : RによるSparkシェル • SparkのDataFrameをRから操作できる • SparkのDataFrameをRのDataFrameと変換できる
26.
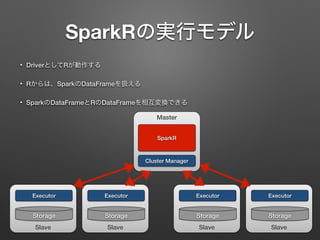
SparkRの実行モデル • DriverとしてRが動作する • Rからは、SparkのDataFrameを扱える •
SparkのDataFrameとRのDataFrameを相互変換できる Slave Executor Storage Master SparkR Cluster Manager Slave Executor Storage Slave Executor Storage Slave Executor Storage
27.
RDD(Resilient Distributed Dataset) •
論理的にはコレクション • 物理的にはクラスタ内のノードに分散配置される • RDDに対して「変換」をかけて、新たなRDDを生成する。その際に生 成されるのはRDD間の系統グラフであり、まだ演算処理は行われない • RDDに対して「アクション」を行うと、系統グラフをさかのぼって計 算が実行される # テキストを読んでRDDを生成 rmRDD = sc.textfile(‘readme.md’) #フィルタをかけて次のRDDを生成 spRDD = rmRDD.filter(…) #もう1つフィルタ。 sp10RDD = spRDD.filter(…) #この時点ではまだテキストファイルも読まれていない #行数のカウント。この時点ですべての処理が走る count = sp10RDD.count() 元のファイル rmRDD spRDD sp10RDD
28.
RDD(Resilient Distributed Dataset) •
アクションを実行すると、各エクゼキュータ内で一気に系統グラフの計算が行われる。 • JVMの再起動は伴わず、ディスクへのアクセスも少ない。 • CPUのI/O待ちが少なく、使用効率が上がる # テキストを読んでRDDを生成 rmRDD = sc.textfile(‘readme.md’) #フィルタをかけて次のRDDを生成 spRDD = rmRDD.filter(…) #もう1つフィルタ。 sp10RDD = spRDD.filter(…) #この時点ではまだテキストファイルも読まれていない #行数のカウント。この時点ですべての処理が走る count = sp10RDD.count() 元のファイル rmRDD spRDD sp10RDD 123
29.
RDD(Resilient Distributed Dataset) •
計算されたRDDの内容は、メモリもしくはディスクにキャッシュできる • 初回のアクション実行時にキャッシュが行われ、それ以降のアクション実行時 には、キャッシュされたところまでしか系統グラフはさかのぼらない rmRDD = sc.textfile(‘readme.md’) spRDD = rmRDD.filter(…) #キャッシュの指示。この時点ではまだキャッシュされない spRDD.persist() sp10RDD = spRDD.filter(…) sp20RDD = spRDD.filter(…) #行数のカウント。この時点でspRDDがキャッシュされる count10 = sp10RDD.count() #行数のカウント。spRDDの再計算は走らない count20 = sp20RDD.count() 元のファイル rmRDD spRDD sp10RDD 123
30.
RDD(Resilient Distributed Dataset) •
計算されたRDDの内容は、メモリもしくはディスクにキャッシュできる • 初回のアクション実行時にキャッシュが行われ、それ以降のアクション実行時には、キャッシュされ たところまでしか系統グラフはさかのぼらない • 繰り返しの処理を伴うアルゴリズムを効率的に実行できるため、機械学習との相性がいい rmRDD = sc.textfile(‘readme.md’) spRDD = rmRDD.filter(…) #キャッシュの指示。この時点ではまだキャッシュされない spRDD.persist() sp10RDD = spRDD.filter(…) sp20RDD = spRDD.filter(…) #行数のカウント。この時点でspRDDがキャッシュされる count10 = sp10RDD.count() #行数のカウント。spRDDの再計算は走らない count20 = sp20RDD.count() 元のファイル rmRDD spRDD sp10RDD 123 sp20RDD 456
31.
試用と運用について
32.
Hadoopエコシステムの利用 • 自前での運用と構築は大変です。 • 一番お勧めなのは、クラウドのHadoopのサービスを使うこと(AWSの Elastic
MapReduceとかAzureのHDInsight)。 • たいていの場合、「Hadoopの運用力」がビジネスの競争力の源泉ではない はずなので、そこはプロバイダに任せるほうが合理的だと思います(よほ どクリティカルな部分でHadoopを使うのでなければ)。 • データセンターで運用する場合、あるいはお試し的に手元でクラスタ組む 場合は、Clouderaのディストリビューション(http://www.cloudera.co.jp/ products-services/cdh/cdh.html)が第一候補になると思います。
33.
Sparkの試用 • ローカルで動かしてみる、あ るいは開発してみるだけなら かなりお手軽です。 • ぜひトライしてみてください。
34.
ご清聴ありがとうございました。
Download











































































![[Japanese Content] Lance Riedel_The App Server, The Hive in Tokyo_Aug29](https://cdn.slidesharecdn.com/ss_thumbnails/lanceriedelappserver-thehiveaug29-130920154018-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)






















