2025年に入って3度目の自分のサイト再構築をしていた時(どうか突っ込まないでください)、私はあることを思い出しました。それは、「ブラウザは実は魔法のような存在だ」ということです。
私たちが日々扱う終わりなきフォームバリデーションやエラー状態、APIコールの裏側で、Webにはまだ「奇妙な小さな機能」がたくさん詰まっています。それはまるで、昔のゲームで隠しステージを見つけた時のような、思わずニヤリとしてしまうようなものです。
私たちは普段、fetch() や addEventListener() といったお決まりのツールキットにこだわりがちです。しかしブラウザAPIにはエンジニアリングというより「イースターエッグ(隠し要素)」に近い、忘れ去られた層が存在します。CRUDアプリというより、「えっ、こんなところで何してるの?!」という感覚に近いものです。
正直なところ、B2Bダッシュボードの開発でスプリント112あたりを回しているような状況なら、あなたには少しの楽しみが必要でしょう。これらのAPIは、ただ奇妙なものを作るためだけのものではありません。Web開発の楽しさや遊び心、そして純粋な有用さを再発見させてくれるものです。
プログラムでスマホを振動させるのは、確かに面白い。でも、その同じAPIを使えば、モバイルでのエラーハンドリングをよりアクセシブル(親切)にできます。
MIDIキーボードでタイピングをするのは、単なる宴会芸に過ぎないでしょう。でもそれは、代替ハードウェアを必要とする人々にとって正当な入力方法にもなり得るのです。
一見すると常軌を逸しているように見えるこれらの機能も、それぞれが「心地よいインターフェース」「予想外のインタラクション」、そして「思慮深いアクセシビリティの向上」への扉を開いてくれます。
それでは、驚くほど奇妙で素晴らしい5つのブラウザAPIを紹介しましょう。これらは遊び心にあふれ、便利で、Reactコンポーネントのデバッグよりもきっと楽しいはずです。
1. Battery Status API:世話焼き(だけど少し不気味)な友人
- 実用的なユースケース: 電力消費を考慮したUXの設計
- 楽しいユースケース: バッテリー低下時のディスコパーティー
ノートPCのバッテリーが10%を切った時、私のWebサイトはディスコに変わり、「充電しろ!」と叫び始めます。どうやら私のコンピュータは、私の人生の選択に意見したいようです。
navigator.getBattery().then(battery => {
function checkBattery() {
if (battery.level < 0.1) {
document.body.style.animation = 'disco 0.5s infinite';
document.body.insertAdjacentHTML('beforeend', '<div style="position: fixed; top: 50%; left: 50%; transform: translate(-50%, -50%); font-size: 3rem; z-index: 9999;">🔋 GO CHARGE YOURSELF! 🔋</div>');
}
}
battery.addEventListener('levelchange', checkBattery);
});
しかし、落とし穴も…
注意点として、Battery Status APIはプライバシー上の懸念から、ほとんどのブラウザで非推奨となっています。Firefoxでは2016年に削除され、現在は特定のバージョンのChrome系ブラウザでしかサポートされていません。しかし、イースターエッグや実験的な機能としては、今でも完璧(かつ時として便利)です。
思慮深いユースケース:電力を考慮したUX
あなたのサイトが訪問者のバッテリー残量を気遣うことができます。残量が少ない? それなら自動的に軽量テーマに切り替えたり、アニメーションをオフにしたり、PCが切れる前に保存を促したりしましょう。会計ソフトやCMS、ERPといった、重要な作業を伴うサイトには最適です。
その他の試せること
- バッテリー低下時にビデオの画質を下げる
- 残量20%以下で重いアニメーションを無効化する
- 「作業を保存してください」という警告を表示する
2. Vibration API:コードで語るスマホシェイカー
- 実用的なユースケース: エラーやメッセージの触覚フィードバック
- 楽しいユースケース: リズムゲームやビートに同期した振動
振動パターンでメッセージを送ってみましょう。準備はいいですか?モールス信号で「HELLO」を送ります。
// モールス信号 "HELLO": .... . .-.. .-.. ---
if ("vibrate" in navigator) {
navigator.vibrate([
100, 50, 100, 50, 100, 50, 100, // H: ....
300, // pause
100, // E: .
300, // pause
100, 50, 300, 50, 100, 50, 100, // L: .-..
300, // pause
100, 50, 300, 50, 100, 50, 100, // L: .-..
300, // pause
300, 50, 300, 50, 300 // O: ---
]);
}
あなたのスマートフォンが電信機になりました!
Vibration APIの何が良いのか?
Vibration APIを使えば、Webサイトから文字通りユーザーのスマホを揺らすことができます。現代のモバイルブラウザでサポートされています(iOS Safariは残念ながら非対応)。
正当な使い道(本当に)
Webベースのゲームやアプリにおいて、触覚フィードバックは臨場感を高めます。キャラがダメージを受けたら「ブルッ」。タイマーが切れたら「微振動」。フォームの入力エラーなら「クイックな振動」で注意を引く。クリエイティブな活用例には以下があります:
- ビートに同期した振動を伴うリズムゲーム
- 視覚障害者のためのアクセシビリティ機能
- 呼吸パターンに合わせた振動を出す瞑想アプリ
3. Web Speech API:ブラウザの内なる独り言
- 実用的なユースケース: インクルーシブデザイン、スクリーンリーダーの強化、音声操作フォーム
- 楽しいユースケース: 喋るフォーチュンクッキー、高音のロボットボイス
私は、プログラミングの格言をバカバカしいほど高音のロボットボイスで届ける「喋るフォーチュンクッキー」サイトを作りました。ブラウザをモチベーショナル・スピーカーにしたかったからです。
const fortunes = [
"You will debug for exactly three hours and discover the bug was a missing semicolon.",
"A wild merge conflict will appear in your near future.",
"Your code will work perfectly in staging but break spectacularly in production.",
"You are the chosen one. But only until the next deploy."
];
function speakFortune() {
const fortune = fortunes[Math.floor(Math.random() * fortunes.length)];
const utterance = new SpeechSynthesisUtterance(fortune);
utterance.pitch = 1.5; // 少しおどけた感じにする
utterance.rate = 0.9;
speechSynthesis.speak(utterance);
}
ブラウザがロボットボイスでプログラミングの知恵を授けてくれるのは、どこか魔法のような感覚があります。
Web Speech APIは実は強力
このAPIは2つの魔法から成ります。「音声合成(Speech Synthesis)」がブラウザに喋らせ、「音声認識(Speech Recognition)」がブラウザに聞き取らせます。音声合成については、Chrome、Firefox、そしてSafariでも十分にサポートされています。
真のアクセシビリティ向上
このAPIはアクセシビリティにおいて驚異的です。ダッシュボードの更新内容を自動で読み上げたり、複雑なUI要素に音声説明を加えたり、音声制御のナビゲーションを作成したり。これこそが最高のインクルーシブデザインです。
実用的なユースケース
- スクリーンリーダーの機能強化
- 音声制御フォーム
- 視覚障害者向けのオーディオフィードバック
- 発音確認ができる言語学習アプリ
4. WebHID API:ハンドルがスクロールバーになる時
- 実用的なユースケース: アクセシブルなWeb UIの設計
- 楽しいユースケース: スクロールをマリオカート風に
Webの入力といえばキーボードやマウスのことだと思っていた時代を覚えていますか? 新たなレベルへようこそ。それがWebHIDです。
私は古いレーシングホイール(ハンドル型コントローラー)をUSBでブラウザに繋ぎ、ハンドルを左右に切ることでブログ記事をスクロールできるようにしました。だってできるんですから!
人間工学的だったか? 全く違います。 客観的に見て最高だったか? もちろんです。
const devices = await navigator.hid.requestDevice({ filters: [ { vendorId: 0x046d } ]});
if (devices.length) {
await devices[0].open();
devices[0].addEventListener('inputreport', (e) => {
// Assume axis 0 is steering
const steer = e.data.getInt8(0);
window.scrollBy(0, steer); // Steer = scroll!
});
}
突然、LogRocketの記事を読むのがマリオカートをプレイしているような気分になりました。生産性には危険ですが、金曜午後の実験としては最高です。
そもそもWebHIDとは?
WebHID APIを使えば、WebサイトがHID(Human Interface Device)と直接通信できます。ゲームパッド、MIDIドラム、バーコードスキャナー、あるいは引き出しの奥に眠っている謎のUSBハードウェアまで。現在はChrome 89+やEdge 89+でサポートされていますが、FirefoxやSafariでは未対応です。
本当に役に立つの?
もちろんです。STEMフェアの学生たちと協力したり、アクセシブルなWeb UIを設計したりする場面を想像してください。誰かがカスタムジョイスティックや特殊なコントローラーを持っていれば、それをネイティブに動かすことができます。ダウンロードや仲介ソフトは不要、ブラウザから「繋ぐだけ」です。WASMのようですが、良いものです。
他のぶっ飛んだアイデア
- PlayStationコントローラーの入力で動くSVG blob
- MIDIドラムパッドで発動する紙吹雪
- バーコードスキャナーでイースターエッグを解除
5. WebMIDI API:キーストロークを音符に変える
- 実用的なユースケース: インタラクティブなサウンドデザイン
- 楽しいユースケース: リックロール(釣り動画)の絶好のチャンス
埃を被ったMIDIキーボードを引っ張り出し、鍵盤を叩くたびに画面上のあちこちにランダムな絵文字が現れるようにしました。我が家ではこれが「生産性」と呼ばれています。
navigator.requestMIDIAccess().then((access) => {
for (const input of access.inputs.values()) {
input.onmidimessage = (msg) => {
if (msg.data[0] === 144 && msg.data[2] > 0) { // Note-on message
const emoji = ['🎵', '🎶', '🎸', '🥁', '🎹', '🎺', '🎷'][Math.floor(Math.random() * 7)];
document.body.insertAdjacentHTML('beforeend', `<span style="font-size: 2rem; position: absolute; left: ${Math.random() * 100}%; top: ${Math.random() * 100}%;">${emoji}</span>` );
}
};
}
});
演奏するたびにWebサイトが視覚的なシンフォニーへと変わります。馬鹿げているけれど楽しく、驚くほど引き込まれます(そしてリックロールの絶好の機会でもある)。
真面目な側面:共同音楽制作
WebMIDI APIはブラウザを、MIDIメッセージの送受信が可能な楽器へと変貌させます。大陸を超えてミュージシャンがセッションできるWebアプリを想像してください。ベルリンの誰かが弾いた音でモントリオールのシンセを鳴らし、東京の照明を制御し、あなたのブラウザでビジュアライザーを作る。何もインストールせず、ブラウザだけでリアルタイムの音楽コラボレーションが可能になります。
他にも試せるぶっ飛んだ活用法
- ブラウザベースのDAW(デジタル・オーディオ・ワークステーション)やシーケンサー
- 音楽理論を学べる知育アプリ
- インタラクティブなサウンドデザイン・ツール
ボーナスラウンド:さらなるWebの魔法
もっとブラウザの奇妙さを知りたいなら:
- Ambient Light API:部屋の照明に合わせてサイトのテーマを変化させる(動けばラッキー)
- Device Motion API:スマホの傾きに反応するデジタル溶岩ランプを作る
- Clipboard API:コンテンツを自動でフォーマットする「スマート・ペースト」を作成
特にAmbient Light APIは面白いです。照度(ルクス)を検知してUIを調整できるので、Kindleのような読書体験やスマートホームのインターフェースに最適です。
なぜ「奇妙なもの」にこだわるのか?
実のところ、これらのAPIのほとんどは、次のSaaSダッシュボードに革命を起こすようなものではありません。しかし、もっと重要なことを教えてくれます。それは、「Webは今でも実験と喜び、そして嬉しい驚きに満ちた場所である」ということです。
私がWebサイトを作り始めた頃、すべてが可能だと感じられました。これらのAPIはその感覚を呼び戻してくれます。以下のような場面に最適です:
- 学習:ブラウザの内部的な仕組みを理解する
- プロトタイピング:複雑な設定なしに突飛なアイデアを試す
- アクセシビリティ:より包括的な体験を創造する
- 喜び:Webをもう少しだけ魔法のような場所に変える
これらのAPIは、スキルを磨き、型破りなアイデアを形にし、誰にとっても楽しい体験を構築するための完璧な口実になります。平凡な枠を超えて、遊び心を再発見しましょう。
次にフォーム作成やAPIコールの繰り返しに行き詰まったら、これらのAPIを1つ手に取って、「素晴らしいほどに無駄なもの」を作ってみてください。Webの奇妙さを保ってくれたことに、未来の自分が感謝するでしょう。
※訳者註:本翻訳記事は執筆者の意図を尊重するため、原文掲載内容をそのまま掲載しております。また、記載されている会社名、製品名は、各社の商標または登録商標です。
]]>数週間前、私たちの本番アプリがハングし始めました。コンポーネントがランダムに読み込まれなくなったのです。ユーザーの画面ローディングスピナーの前で固まってしまいました。40時間デバッグした末に、私たちは気づきました。React Server Components(RSC)が問題だったのです。
イントロダクション:理想 vs. 現実
当初、React Server Components(RSC)は革命的であるはずでした。 Reactチームは以下を強調していました:
- ✅ パフォーマンスの向上
- ✅ バンドルサイズの削減
- ✅ 自動的なコード分割
- ✅ コンポーネントからのダイレクトなデータベースアクセス
私たちは彼らを信頼し、Next.jsアプリ全体をServer Componentsと共にApp Routerへ移行しました。
3カ月後、私たちのアプリは以下の状況に陥りました:
- 初期ロードが遅い
- デバッグがより複雑に
- 経験の浅い開発者にとって理解しにくい
- 原因不明なキャッシュ問題に悩まされている
この記事は、Reactコミュニティーが必要としている率直な会話です。マーケティングでも、誇張でもありません。React Server Componentsを使った、本番環境でのリアルな体験談です。
Part 1:React Server Componentsとは何か(シンプルバージョン)
従来モデル(Client Components)
// This runs in the browser
'use client'
export default function UserProfile() {
const [user, setUser] = useState(null)
useEffect(() => {
fetch('/api/user')
.then(res => res.json())
.then(setUser)
}, [])
if (!user) return <div>Loading...</div>
return <div>{user.name}</div>
}処理フロー:
- ブラウザーがJavaScriptをダウンロードする
- コンポーネントがマウントされる
useEffectが発火- APIへのフェッチリクエスト
- レスポンスを待機
- stateを更新
- 再レンダリング
結果:ユーザーに「Loading...」が1〜2秒間表示される
Server Componentモデル
// This runs on the server
import { db } from '@/lib/database'
export default async function UserProfile() {
const user = await db.user.findFirst()
return <div>{user.name}</div>
}処理フロー:
- リクエストがサーバーに到達
- コンポーネントがサーバーで実行される
- データベースクエリが実行される
- データを含んだHTMLがブラウザーに送信される
- ユーザーにコンテンツが即座に表示される
結果:ユーザーは即座にデータを閲覧できる(理論上は)
理想
Server Componentsは以下の問題の解決を目指すものでした:
- ローディング状態
- クライアントサイドのデータフェッチ
- APIルートのボイラープレート
- 巨大なJavaScriptバンドル
現実は、もっと複雑です。
Part 2:落とし穴
問題点 1:暗黙のウォーターフォール
Server Componentsで実際に起こることを見てみましょう:
// app/dashboard/page.tsx
export default async function Dashboard() {
const user = await getUser() // 200ms
return (
<div>
<Header user={user} />
<Stats userId={user.id} /> {/* Another server component */}
<RecentActivity userId={user.id} /> {/* Another server component */}
</div>
)
}
// Stats component
async function Stats({ userId }) {
const stats = await getStats(userId) // 300ms - WAITS for parent!
return <div>{stats.total}</div>
}
// RecentActivity component
async function RecentActivity({ userId }) {
const activity = await getActivity(userId) // 250ms - WAITS for Stats!
return <div>{activity.map(...)}</div>
}期待する動作:並列リクエスト(最大300ms)
実際の動作:シーケンシャルなウォーターフォール
getUser()- 200ms- コンポーネントがレンダリングされ、
<Stats>を検出 getStats()- 300ms(ステップ1の後に開始)- コンポーネントがレンダリングされ、
<RecentActivity>を検出 getActivity()- 250ms(ステップ3の後に開始)
合計時間:750ms(並列化されていない!)
なぜこうなるのか:Reactはコンポーネントをシーケンシャルにレンダリングします。各非同期コンポーネントが、次のコンポーネントをブロックするのです。
修正
手動で並列化しなければなりません:
export default async function Dashboard() {
// Run all queries in parallel
const [user, stats, activity] = await Promise.all([
getUser(),
getStats(),
getActivity()
])
return (
<div>
<Header user={user} />
<Stats data={stats} /> {/* Now a regular component */}
<RecentActivity data={activity} /> {/* Now a regular component */}
</div>
)
}しかし、これでは以下の利点が失われます:
- コンポーネントのカプセル化
- 関心の分離
- Server Componentsの目的
問題点 2:キャッシュというブラックボックス
React 19とNext.js 14以降は、積極的なキャッシュ機構を備えています。これは良いことのように聞こえますが、本番環境で問題を起こすまでは、です。
私たちが遭遇した実際のバグ:
// app/posts/page.tsx
export default async function PostsPage() {
const posts = await db.post.findMany()
return <PostList posts={posts} />
}起こったこと:
- ユーザーが新しい投稿を作成
/postsにリダイレクトされる- 新しい投稿が表示されない
- ページをリロードしても無駄
- ブラウザーのキャッシュをクリアしても無駄
理由:Next.jsがサーバー上でデータベースのクエリ結果をキャッシュしていました。そして、そのキャッシュを無効化(invalidate)していなかったのです。
解決策:
export const revalidate = 0 // Disable caching
export default async function PostsPage() {
const posts = await db.post.findMany()
return <PostList posts={posts} />
}しかしながら:
- パフォーマンス上の利点が失われる
- ページロードごとにデータベースにアクセスが走る
- Client Componentsを使っていた頃のパフォーマンスに逆戻り
より深刻な問題:何がキャッシュされているのか確認できません。キャッシュインスペクターのようなものはありません。推測するしかないのです。
問題点 3:クライアントとサーバーの境界が分かりにくい
これが私たちのチームにとって最大の問題です:
// ❌ This looks like it should work
'use client'
import { ServerComponent } from './ServerComponent'
export default function ClientComponent() {
const [count, setCount] = useState(0)
return (
<div>
<button onClick={() => setCount(count + 1)}>
Count: {count}
</button>
<ServerComponent /> {/* Error! */}
</div>
)
}エラー:「Server ComponentをClient Componentにインポートしています」
理由:ひとたび'use client'を使うと、その配下は全てClient Componentでなければならないからです。
修正:
// ✅ Pass Server Component as children
'use client'
export default function ClientComponent({ children }) {
const [count, setCount] = useState(0)
return (
<div>
<button onClick={() => setCount(count + 1)}>
Count: {count}
</button>
{children}
</div>
)
}
// In parent (Server Component)
<ClientComponent>
<ServerComponent />
</ClientComponent>これは直感的でないように見えます。経験の浅い開発者は、この仕様に何週間も苦しめられています。
問題点 4:フォームの複雑性
従来のフォームハンドリング:
'use client'
export default function Form() {
async function handleSubmit(e) {
e.preventDefault()
const res = await fetch('/api/submit', {
method: 'POST',
body: JSON.stringify(formData)
})
if (res.ok) router.push('/success')
}
return <form onSubmit={handleSubmit}>...</form>
}シンプルに機能し、誰もが理解できます。
Server Actions(RSC流):
// app/actions.ts
'use server'
export async function submitForm(formData: FormData) {
const name = formData.get('name')
await db.user.create({ data: { name } })
revalidatePath('/users')
redirect('/success')
}
// Form component
export default function Form() {
return (
<form action={submitForm}>
<input name="name" />
<button type="submit">Submit</button>
</form>
)
}問題点:
- エラーハンドリングが不明確:どこでエラーをキャッチすればよいのでしょう?
- ローディング状態:どうやってスピナーを表示するのでしょう?
- バリデーション:クライアントサイドのバリデーションにはClient Componentが必要
「解決」にはuseFormStatusが必要です:
'use client'
import { useFormStatus } from 'react-dom'
import { submitForm } from './actions'
function SubmitButton() {
const { pending } = useFormStatus()
return (
<button disabled={pending}>
{pending ? 'Submitting...' : 'Submit'}
</button>
)
}
export default function Form() {
return (
<form action={submitForm}>
<input name="name" />
<SubmitButton />
</form>
)
}このために必要なもの:
- Server Actions用の別ファイル
- ボタン用のClient Component
- 学習すべき新しいフック
- 増えるファイルと複雑さ
以前の方法のシンプルさと比べて、どれほどのメリットがあるのでしょうか。
問題点 5:TypeScriptの型安全性が失われる
Server Componentsは、TypeScriptを巧妙なやり方で壊します:
// lib/db.ts
export async function getUser() {
return await db.user.findFirst()
}
// app/page.tsx - Server Component
export default async function Page() {
const user = await getUser()
return <UserProfile user={user} /> // Type error!
}
// components/UserProfile.tsx - Client Component
'use client'
interface Props {
user: User // Prisma type with Date objects
}
export default function UserProfile({ user }: Props) {
return <div>{user.createdAt.toISOString()}</div> // Runtime error!
}問題点:Server ComponentsはpropsをJSONにシリアライズします。Dateオブジェクトは文字列になってしまうのです。
TypeScriptはこれを型エラーとして検知できません。本番環境でランタイムエラーが発生します。
修正:手動でのシリアライズ
export async function getUser() {
const user = await db.user.findFirst()
return {
...user,
createdAt: user.createdAt.toISOString() // Manual conversion
}
}このために必要なこと:
- データベース呼び出しごとのシリアライズ関数
- サーバー用とクライアント用で別々の型定義
- 安全のためのランタイムチェック
Part 3:Server Componentsがうまく機能するケース
ただ否定ばかりしたいわけではありません。Server Componentsがうまく機能する特定のユースケースもあります。
✅ ユースケース 1:静的コンテンツサイト
// Blog post page
export default async function BlogPost({ params }) {
const post = await getPost(params.slug)
return (
<article>
<h1>{post.title}</h1>
<Markdown content={post.content} />
</article>
)
}うまくいく理由:
- インタラクティビティーが不要
- コンテンツの変更がまれ
- キャッシュに最適
- SEOに強い
結論:Server Componentsが輝ける場所です。
✅ ユースケース 2:ダッシュボードのレイアウト
export default async function DashboardLayout({ children }) {
const user = await getCurrentUser()
return (
<div>
<Sidebar user={user} />
<main>{children}</main>
</div>
)
}うまくいく理由:
- 全てのページでユーザーデータが必要
- レイアウト部分のインタラクティビティーは最小限
- ユーザーセッションをキャッシュできる
結論:良いユースケースです。
✅ ユースケース 3:データテーブル(フィルターなし)
export default async function UsersTable() {
const users = await db.user.findMany()
return (
<table>
{users.map(user => (
<tr key={user.id}>
<td>{user.name}</td>
<td>{user.email}</td>
</tr>
))}
</table>
)
}うまくいく理由:
- 表示専用のデータ
- クライアントサイドのstateが不要
- サーバーサイドレンダリングの方が速い
結論:適切なユースケースです。
Part 4:Server Componentsが失敗するケース
❌ アンチパターン 1:リアルタイム更新
// ❌ This doesn't work
export default async function LiveFeed() {
const posts = await getPosts()
return <PostList posts={posts} />
}問題点:更新をサブスクライブする方法がありません。WebSocketを利用するためにはClient Componentが必要です。
必要なもの:useEffectとWebSocket接続を持つClient Component。
Server Componentsはこういった場面では力を発揮できません。
❌ アンチパターン 2:複雑なフォーム
// ❌ This gets messy fast
export default function MultiStepForm() {
// How do you manage form state across steps?
// How do you validate before submission?
// How do you show field-level errors?
}問題点:フォームはクライアントサイドのstateを必要とします。Server Actionsとクライアントのstateを混ぜるのは混乱のもとです。
解決策:制御された入力を持つClient Componentを使う。
❌ アンチパターン 3:インタラクティブ性の高いUI
// ❌ Server Components are wrong here
export default async function DataGrid() {
const data = await getData()
// Users need to:
// - Sort columns
// - Filter rows
// - Select items
// - Paginate
return <Table data={data} />
}問題点:全てのインタラクションでサーバーとのラウンドトリップが必要になります。
解決策:ローカルstateまたはTanstack Query(旧React Query)等を持つClient Component。
Part 5:Server Componentsの本当のコスト
Server Componentsの隠れたコストについて話しましょう。
コスト 1:開発者体験
Server Components以前:
- 経験の浅い開発者がチームに参加
- Reactフックを学ぶ
- クライアントサイドのデータフェッチを理解する
- 1〜2週間で価値を発揮し始める
Server Components以後:
- 経験の浅い開発者がチームに参加
- Reactフックを学ぶ
- Server Componentsを学ぶ
- クライアント/サーバーの境界ルールを学ぶ
- Server Actionsを学ぶ
- キャッシュの挙動を学ぶ
- どのパターンをいつ使うべきか学ぶ
- 1〜2カ月で生産的になる(運が良ければ)
私たちのチームの実際の統計:オンボーディング期間が2週間から6週間に増加しました。
コスト 2:デバッグの難しさ
Client Componentのバグ:
- DevToolsを開く
- コンソールでエラーを確認
- ブレークポイントを追加
- コードをステップ実行
- バグを修正
所要時間:10〜30分
Server Componentのバグ:
- エラーはターミナルに表示される(ブラウザーではない)
- ブラウザーのDevToolsが使えない
- console.log文を追加
- 問題を再現させる
- ターミナルのログを確認
- ステップ3〜6を何度も繰り返す
- 最終的にバグを発見
所要時間:1〜3時間
コスト 3:バンドルサイズ
理想:Server Components利用によるバンドルサイズ削減
現実の確認:
Server Components以前(純粋なクライアント):
- Reactバンドル:45KB
- アプリコード:120KB
- 合計:165KB
Server Components以後:
- Reactバンドル:45KB
- React Server Componentsランタイム:28KB(new!)
- アプリコード(クライアント部分):80KB
- Server Actionボイラープレート:15KB
- 合計:168KB
バンドルサイズ +3KB(1.8%)
しかし、待ってください、まだあります:
- HTMLサイズの増加(サーバーでレンダリングされたコンテンツ)
- ネットワークリクエストの増加(Server Componentツリー)
- RSCペイロードのオーバーヘッド
実際の結果:初期バンドルは減少どころかわずかに増大し、総転送データ量は増加しました。
コスト 4:パフォーマンス(という驚き)
移行前後で測定しました:
メトリクス:Time to Interactive (TTI)
Server Components以前:
- ホームページ:1.2秒
- ダッシュボード:1.8秒
- 製品ページ:1.4秒
Server Components以後:
- ホームページ:1.9秒(58%悪化!)
- ダッシュボード:2.4秒(33%悪化!)
- 製品ページ:1.1秒(21%改善)
なぜ遅くなったのか?
- サーバーレンダリングに時間がかかる
- ウォーターフォールリクエスト(問題点 1を参照)
- APIレスポンスのクライアントサイドキャッシュがない
なぜ製品ページは速くなったのか?
- シンプルでデータ中心のページ
- インタラクティビティーがない
- RSCの完璧なユースケース
学び:Server Componentsは自動的に速くなるわけではありません。
Part 6:コミュニケーションの問題
私が最もフラストレーションを感じるのは、Reactチームがこれらの問題を認識していたことです。
私の率直な印象:
- ウォーターフォール問題:Reactのドキュメントに記載があるがやや伝わりづらい
- キャッシュ問題:「より良いdevtoolsを開発中です」(2年間ずっと)
- TypeScript問題:「これは期待される動作です」
- デバッグの難しさ:「console.logを使ってください」(本気で?)
コミュニティーは、ドキュメントからではなく、本番環境でのつらい経験を通じてこれらの問題を発見しました。
以下と比較してみてください:
- Svelte:優れたドキュメント、明確な制限事項
- Vue:トレードオフについて正直
- Solid:学習曲線について率直
Part 7:では、実際どうすべきか?
戦略 1:選択的導入(推奨)
Server Componentsを使うケース:
- 静的コンテンツ
- シンプルなデータ表示
- レイアウトコンポーネント
- SEOが重要なページ
Client Componentsを使うケース:
- バリデーション付きのフォーム
- リアルタイム機能
- インタラクティブなUI
- 複雑なstate管理
構成例:
app/
(marketing)/ # Server Components
page.tsx
about/page.tsx
(dashboard)/ # Mixed
layout.tsx # Server Component
page.tsx # Client Component (interactive)
(blog)/ # Server Components
[slug]/page.tsx戦略 2:ハイブリッドレンダリング
// Server Component (page)
export default async function ProductPage({ params }) {
const product = await getProduct(params.id)
// Render static content on server
return (
<div>
<h1>{product.name}</h1>
<p>{product.description}</p>
{/* Interactive parts as Client Components */}
<AddToCartButton productId={product.id} />
<Reviews productId={product.id} />
</div>
)
}
// Client Component (interactive)
'use client'
function AddToCartButton({ productId }) {
const [loading, setLoading] = useState(false)
async function handleClick() {
setLoading(true)
await addToCart(productId)
setLoading(false)
}
return <button onClick={handleClick}>Add to Cart</button>
}これがうまくいく理由:
- サーバーが静的コンテンツをレンダリング
- クライアントがインタラクティビティーを処理
- 関心の分離が明確
戦略 3:待つ(議論の余地はあるが、妥当)
新しいプロジェクトを始める場合:
以下に該当するなら、まだServer Componentsを使わないことを検討してください:
- 小規模なチームである
- 迅速なイテレーションが必要
- アプリのインタラクティブ性が高い
- 開発者体験を重視する
代わりに以下を使い続けてください:
- Pages Router(Next.js 12までの標準)
- Tanstack Queryを使ったClient Components
- 従来のAPIルート
理由:これらのパターンは:
- ドキュメントが整備されている
- よく理解されている
- 実戦でテスト済み
- デバッグが容易
Server Componentsはいずれ成熟します。エコシステムも改善されるでしょう。移行は後からでもできます。
Part 8:移行ガイド(どうしても移行する場合)
ステップ 1:アプリの棚卸し
全てのページを分類します:
✅ Good for RSC:
- Marketing pages
- Blog posts
- Documentation
- Static dashboards
⚠️ Maybe:
- User profiles
- Product listings
- Search results
❌ Bad for RSC:
- Real-time chat
- Complex forms
- Canvas/drawing apps
- Admin panels with lots of interactivityステップ 2:小さく始める
全てを書き換えないでください。1種類のページタイプを選びます:
// Start with: Static blog posts
// app/blog/[slug]/page.tsx
export default async function BlogPost({ params }) {
const post = await getPost(params.slug)
return <Article post={post} />
}まずはシンプルなページでパターンを学びましょう。
ステップ 3:徐々にインタラクティビティーを追加する
// app/blog/[slug]/page.tsx (Server Component)
export default async function BlogPost({ params }) {
const post = await getPost(params.slug)
return (
<article>
<h1>{post.title}</h1>
<Content>{post.content}</Content>
{/* Client Component for interactions */}
<LikeButton postId={post.id} />
<Comments postId={post.id} />
</article>
)
}Server Componentsは、データフェッチと静的コンテンツに集中させましょう。
ステップ 4:ウォーターフォールに注意する
React DevToolsのProfilerを使いましょう:
// ❌ Bad: Sequential
<ServerComponent1 />
<ServerComponent2 /> {/* Waits for 1 */}
<ServerComponent3 /> {/* Waits for 2 */}
// ✅ Good: Parallel
const [data1, data2, data3] = await Promise.all([
getData1(),
getData2(),
getData3()
])ステップ 5:適切なエラー境界(Error Boundary)を設定する
// app/error.tsx
'use client' // Error boundaries must be Client Components
export default function Error({ error, reset }) {
return (
<div>
<h2>Something went wrong!</h2>
<p>{error.message}</p>
<button onClick={reset}>Try again</button>
</div>
)
}Server Componentsは本番環境で失敗する可能性があるため、エラー境界が必要です。
Part 9:代替案
代替案 1:Client Components + Tanstack Queryを使い続ける
'use client'
import { useQuery } from '@tanstack/react-query'
export default function ProductPage({ params }) {
const { data: product, isLoading } = useQuery({
queryKey: ['product', params.id],
queryFn: () => fetch(`/api/products/${params.id}`).then(r => r.json())
})
if (isLoading) return <Skeleton />
return <ProductDetails product={product} />
}メリット:
- よく理解されたパターン
- 優れたDX
- 強力なキャッシュ
- 容易なデバッグ
デメリット:
- クライアントサイドのローディング状態
- 大きめの初期バンドル
- SEOには追加作業が必要
結論:多くのアプリにとって、いまだに素晴らしい選択肢です。
代替案 2:Remixに移行する
Remixには Next.js より前から(loader を通じて)Server Components に類似した仕組みがありました:
// routes/products/$id.tsx
export async function loader({ params }) {
return json(await getProduct(params.id))
}
export default function Product() {
const product = useLoaderData()
return <ProductDetails product={product} />
}メリット:
- よりシンプルなメンタルモデル
- より整備されたドキュメント
- 明確なデータローディングパターン
- 優れたエラーハンドリング
デメリット:
- 異なるフレームワーク
- 移行コスト
結論:新規プロジェクトでは検討する価値があります。
代替案 3:Astroとアイランドアーキテクチャ
---
// src/pages/product/[id].astro
const product = await getProduct(Astro.params.id)
---
<Layout>
<h1>{product.name}</h1>
<p>{product.description}</p>
<AddToCartButton client:load productId={product.id} />
</Layout>メリット:
- デフォルトで静的
- オプトインでインタラクティブにできる
- 優れたパフォーマンス
- シンプルなメンタルモデル
デメリット:
- 純粋なReactではない
- エコシステムが小さい
結論:コンテンツ中心のサイトには最適です。
Part 10:未来(これから)
Reactチームのロードマップ
最近のRFCや議論から:
- より良いDevTools - 「近日公開」(2年間聞き続けていますが)
- キャッシュの改善 - よりきめ細かな制御
- ストリーミングの改善 - Suspenseとのより良い統合
- TypeScriptサポート - Server Componentsの型サポート改善
私たちが本当に必要としているもの
- Server Componentsを使うべきでない時についての明確なドキュメント
- 実際のベンチマークを伴うパフォーマンスガイドライン
- RSCを安全に導入するための移行ツール
- 実際に機能するデバッグツール
- 制限についての正直なコミュニケーション
結論
React Server Componentsは銀の弾丸(決め手)ではありません。特定のユースケース、重大な複雑さ、そして現実的なトレードオフを伴うツールです。
現実:
- 一部のアプリには適しているが、他のアプリには適していない
- メンタルモデルの大幅な転換が必要
- ドキュメントが不十分
- 本番環境での問題が頻発している
- 学習曲線が険しい
私の率直なお勧め:
Server Componentsを使うべきケース:
- ✅ コンテンツ中心のサイトを構築している
- ✅ 複雑さを扱えるシニアチームがいる
- ✅ アーリーアダプターであることをいとわない
- ✅ 学習に時間を投資できる
Server Componentsを使うべきでないケース:
- ❌ アプリのインタラクティブ性が高い
- ❌ 経験の浅い開発者が多い
- ❌ 迅速な開発が必要
- ❌ 安定性が最重要
Reactコミュニティーは、以下について率直に話し合う必要があります:
- RSCが助けになる時 vs ならない時
- 本当のDXコスト
- 実際のパフォーマンスへの影響
- ドキュメントの不備
Server ComponentsはReactの未来です。しかし、一部のアプリケーションにとってはまだ先の話です。 賢明な選択を。
クイック意思決定フレームワーク
自問してみてください:
①アプリの何%がインタラクティブですか?
- 30%未満:Server Componentsを検討
- 30〜70%:ハイブリッドアプローチを使用
- 70%超:Client Componentsを堅持
②チームの経験レベルは?
- 全員シニア:問題なし
- 混合:慎重に進める
- ほぼ経験が浅い開発者:待つ
③タイムラインは?
- 学習プロジェクト:実験する
- 厳しいデッドライン:避ける
- 長期的な投資:検討の余地あり
④優先事項は?
- パフォーマンス:まず測定する
- DX:待つ方がよいかも
- SEO:良いユースケース
- 複雑さ:避ける
リソース
]]>クイックサマリー:この記事の目的は、CSSカスケードレイヤーを既存のレガシーなコードベースに統合するプロセスを、ありのままに全てお伝えすることです。具体的には、何も壊さないように既存のCSSをリファクタリングしてカスケードレイヤーを使えるようにする方法について解説します。
Stephenie Eckles氏の記事「Getting Started With CSS Cascade Layers」を読めば、いつでも素晴らしい概要を学べます。しかし、この記事では、カスケードレイヤーを実際のコードに統合する体験、その長所、短所、そしてスパゲッティコードとの格闘まで、全てお話ししたいと思います。
よくある解説記事のようにサンプルプロジェクトを用意することもできます。しかし現実の世界はそんな風にはいきません。なぜか動いているけれど、誰もその理由を知らないようなスタイルが書かれたコードを引き継ぐ、といった感じで、実際に手を汚してみたいのです。
カスケードレイヤーを使っていないプロジェクトを見つけるのは簡単でした。難しいのは、詳細度や構成に問題を抱えるほど散らかっていて、なおかつカスケードレイヤー統合のさまざまな側面を説明できるくらい幅広いプロジェクトを見つけることでした。
皆さま、Drishtant Ghosh氏が作成した、こちらのDiscordボットのWebサイトをご紹介します。Drishtant氏がご自身の作品を事例として使うことを許可してくださったことに、深く感謝します。このプロジェクトは、ナビゲーションバー、ヒーローセクション、いくつかのボタン、モバイルメニューを備えた、典型的なランディングページです。
 (拡大プレビュー)
(拡大プレビュー)
外見は完璧に見えるのがお分かりでしょう。しかし、その裏側にあるCSSスタイルを見てみると、事態は面白くなってきます。
プロジェクトを理解する
あちこちで@layerを使い始める前に、まずは私たちが扱う対象をしっかりと理解しましょう。GitHubリポジトリをクローンし、今回はCSSカスケードレイヤーを扱うことに主眼を置いているため、index.html、index.css、index.jsの3つのファイルで構成されるメインページにのみ焦点を当てます。
注: このチュートリアルが冗長になりすぎるのを避けるため、プロジェクトの他のページは含めていません。しかし、実験として他のページをリファクタリングしてみるのも良いでしょう。
index.cssファイルは450行以上のコードがあり、ざっと目を通しただけでも、いくつかの懸念点が見て取れます。
- 同じHTML要素を指す同じセレクタで、多くのコードが重複している。
#idセレクタがかなり多い。これについてはCSSで使うべきではないと主張する人もいるでしょう(私もその一人です)。#botLogoが2回定義されており、その間は70行以上も離れている。!importantキーワードがコード全体で安易に使われている。
それでも、サイトは機能しています。ここには「技術的に」間違っていることは何もありません。これこそが、CSSが巨大で美しいモンスターであるもう一つの理由です。エラーが表に出てこないのです!
レイヤー構造を計画する
さて、「全てのスタイルを@layer legacyのような単一のレイヤーにまとめてしまえば、それで終わりじゃないか?」と考える人もいるかもしれません。
それでもいいですが…私はそうすべきではないと思います。
考えてみてください。もしlegacyレイヤーの後にさらにレイヤーが追加された場合、それらの新しいレイヤーはlegacyレイヤーに含まれるスタイルを上書きするはずです。なぜなら、レイヤーの詳細度は優先順位によって整理されており、後から宣言されたレイヤーほど高い優先順位を持つからです。
/* newの方が詳細度が高い */
@layer legacy, new;
/* legacyの方が詳細度が高い */
@layer new, legacy;とはいえ、このサイトの既存スタイルでは!importantキーワードが多用されていることを忘れてはなりません。そうなると、カスケードレイヤーの順序は逆転します。ですから、レイヤーが次のように定義されていても、
@layer legacy, new;!importantが宣言されたスタイルがあると、状況は一変します。この場合、優先順位は次のようになります。
legacyレイヤー内の!importantスタイル(最も強力)newレイヤー内の!importantスタイルnewレイヤー内の通常スタイルlegacyレイヤー内の通常スタイル(最も弱い)
この点だけは、はっきりさせておきたかったのです。では、続けましょう。
カスケードレイヤーは、各レイヤーが明確な責務を持ち、後のレイヤーが常に勝つという明確な順序を作ることで詳細度を管理します。
そこで私は、5つの異なるレイヤーに分割することにしました。
- reset:
box-sizingやmargin、paddingといったブラウザのデフォルトスタイルのリセット。 - base:
body、h1、p、aなどのHTML要素のデフォルトスタイル。デフォルトのタイポグラフィや色も含む。 - layout: 要素の配置を制御するための、主要なページ構造に関するもの。
- components: ボタン、カード、メニューなど、再利用可能なUIセグメント。
- utilities: 一つのことだけをうまくこなす、単一目的のヘルパー修飾子。
これはあくまで私がスタイルを分割し、整理するのが好きな方法です。例えば、Zell Liew氏は、レイヤーとして定義できる4つの異なる分類を持っています。
さらに、物事をサブレイヤーに分割するという考え方もあります。
@layer components {
/* sub-layers */
@layer buttons, cards, menus;
}
/* or this: */
@layer components.buttons, components.cards, components.menus;これも便利かもしれませんが、物事を過度に抽象化したくはありません。この戦略は、明確に定義されたデザインシステムを対象とするプロジェクトには、より適しているかもしれません。
私たちが活用できるもう一つのことは、レイヤー化されていないスタイルと、カスケードレイヤーに含まれないスタイルが最も高い優先順位を持つという事実です。
@layer legacy { a { color: red !important; } }
@layer reset { a { color: orange !important; } }
@layer base { a { color: yellow !important; } }
/* unlayered */
a { color: green !important; } /* highest priority */しかし、私は全てのスタイルを明確なレイヤーで整理しておくという考え方が好きです。少なくともこの文脈においては、物事をモジュール化し、保守しやすく保つことができます。
それでは、このプロジェクトにカスケードレイヤーを追加していきましょう。
カスケードレイヤーを統合する
まず、ファイルの先頭でレイヤーの順序を定義する必要があります。
@layer reset, base, layout, components, utilities;これにより、どのレイヤーがどのレイヤーよりも優先されるかが簡単に分かります(左から右に行くにつれて優先度が高くなります)。これで、セレクタの詳細度ではなく、レイヤーの責務という観点で考えられるようになります。ここからは、スタイルシートを上から下へと進めていきます。
最初に気づいたのは、PoppinsフォントがHTMLとCSSの両方のファイルでインポートされていたことです。フォントを素早く読み込むためには、一般的にHTMLでのインポートが推奨されるため、CSSのインポートを削除し、index.htmlの方を残しました。
次はユニバーサルセレクタ(*)のスタイルです。これには@layer resetに最適な、古典的なリセットスタイルが含まれています。
@layer reset {
* {
margin: 0;
padding: 0;
box-sizing: border-box;
}
}それが片付いたら、次はbodyセレクタです。これには背景やフォントといったプロジェクトの核となるスタイルが含まれているので、@layer baseに入れます。
@layer base {
body {
background-image: url("bg.svg"); /* 分かりやすいようにbg.svgにリネーム */
font-family: "Poppins", sans-serif;
/* ... other styles */
}
}ここでの私の方針は、「baseレイヤーのスタイルは基本的にドキュメント全体に影響を与えるもの」とすることです。今のところ、ページの表示崩れなどは起きていません。
IDをクラスに置き換える
body要素セレクタの次にあるのは、IDセレクタ#loaderとして定義されているページローダーです。
none
私は、可能な限りIDセレクタよりもクラスセレクタを使うべきだと考えています。デフォルトで詳細度を低く保つことができ、詳細度の競合を防ぎ、コードをはるかに保守しやすくするからです。
そこで、index.htmlファイルを開き、id="loader"を持つ要素をclass="loader"にリファクタリングしました。その過程で、id="page"を持つ別の要素を見つけたので、それも同時に変更しました。
index.htmlファイルにいる間に、いくつかのdiv要素で閉じタグが欠けていることに気づきました。ブラウザがそれに対して寛容なのは驚きです。ともかく、それらをクリーンアップし、<script>タグを.heading要素の外に移動させて、bodyの直接の子要素にしました。スクリプトの読み込みをこれ以上困難にするのはやめましょう。
IDをクラスに移行して詳細度の条件をそろえたので、これらをcomponentsレイヤーに入れることができます。ローダーはまさに再利用可能なコンポーネントですからね。
@layer components {
.loader {
width: 100%;
height: 100vh;
/* ... */
}
.loader .loading {
/* ... */
}
.loader .loading span {
/* ... */
}
.loader .loading span:before {
/* ... */
}
}アニメーション
次はキーフレームです。これは少し厄介でしたが、最終的にアニメーションを独自の新しい5番目のレイヤーに分離し、それを含むようにレイヤーの順序を更新することにしました。
@layer reset, base, layout, components, utilities, animations;しかし、なぜanimationsを最後のレイヤーに置くのでしょうか?それは、アニメーションは一般的に最後に実行されるものであり、スタイルの競合の影響を受けるべきではないからです。
プロジェクトのスタイルから@keyframesを検索し、それらを新しいレイヤーに放り込みました。
@layer animations {
@keyframes loading {
/* ... */
}
@keyframes loading2 {
/* ... */
}
@keyframes pageShow {
/* ... */
}
}これにより、静的なスタイルと動的なスタイルが明確に区別され、再利用性が確保できます。
レイアウト
#pageセレクタも#idと同じ問題を抱えていましたが、先ほどHTMLで修正したので、これを.pageに変更し、layoutレイヤーに入れることができます。その主な目的はコンテンツの初期の表示状態を制御することだからです。
@layer layout {
.page {
display: none;
}
}カスタムスクロールバー
これらはどこに置くべきでしょうか?スクロールバーはサイト全体で持続するグローバルな要素です。これはグレーゾーンかもしれませんが、グローバルでデフォルトの機能であるため、@layer baseに完璧に収まると言えるでしょう。
@layer base {
/* ... */
::-webkit-scrollbar {
width: 8px;
}
::-webkit-scrollbar-track {
background: #0e0e0f;
}
::-webkit-scrollbar-thumb {
background: #5865f2;
border-radius: 100px;
}
::-webkit-scrollbar-thumb:hover {
background: #202225;
}
}また、見つけ次第!importantキーワードも削除していきました。
ナビゲーション
nav要素は非常に分かりやすいです。ナビゲーションバーの位置と寸法を定義する主要な構造コンテナだからです。これは間違いなくlayoutレイヤーに入れるべきです。
@layer layout {
/* ... */
nav {
display: flex;
height: 55px;
width: 100%;
padding: 0 50px; /* 一貫した左右のpadding */
/* ... */
}
}ロゴ
ロゴに関連するスタイルブロックが3つあります。nav .logo、.logo img、#botLogoです。これらの名前は冗長であり、継承によるコンポーネントの再利用性の恩恵を受けることができます。
私は次のようにアプローチしています。
nav .logoは、ロゴが他の場所でも再利用できることを考えると、詳細度が高すぎます。navを削除して、セレクタを単に.logoにしました。そこには!importantキーワードもあったので、削除しました。- 以前は柔軟性の低い絶対配置で設定されていた
.logo imgを配置しやすくするため、.logoをFlexboxコンテナに更新しました。 #botLogoIDは2回宣言されていたので、2つのルールセットを1つに統合し、.botLogoクラスにすることで詳細度を下げました。そしてもちろん、HTMLを更新してIDをクラスに置き換えました。.logo imgセレクタは.botLogoとなり、ロゴの全ての要素をスタイリングするためのベースクラスになります。
そして、残ったのは次のコードです。
/* initially .logo img */
.botLogo {
border-radius: 50%;
height: 40px;
border: 2px solid #5865f2;
}
/* initially #botLogo */
.botLogo {
border-radius: 50%;
width: 180px;
/* ... */
}違いは、一方がナビゲーションで、もう一方がヒーローセクションの見出しで使われている点です。2つ目の.botLogoは、.heading .botLogoセレクタで少し詳細度を上げることで変換できます。ついでに、重複しているスタイルも整理しておきましょう。
ロゴを再利用可能なコンポーネントにうまく変えることができたので、コード全体をcomponentsレイヤーに配置しましょう。
@layer components {
/* ... */
.logo {
font-size: 30px;
font-weight: bold;
color: #fff;
display: flex;
align-items: center;
gap: 10px;
}
.botLogo {
aspect-ratio: 1; /* widthに合わせて正方形の寸法を維持 */
border-radius: 50%;
width: 40px;
border: 2px solid #5865f2;
}
.heading .botLogo {
width: 180px;
height: 180px;
background-color: #5865f2;
box-shadow: 0px 0px 8px 2px rgba(88, 101, 242, 0.5);
/* ... */
}
}これは少し手間がかかりました!しかしこれで、ロゴは新しいレイヤーアーキテクチャに完璧にフィットするコンポーネントとして、適切に設定されました。
ナビゲーションリスト
これは典型的なナビゲーションのパターンです。非順序リスト(<ul>)を、全てのリスト項目を同じ行に水平に(折り返しを許可して)表示する柔軟なコンテナに変えます。これは再利用可能なナビゲーションの一種であり、componentsレイヤーに属します。しかし、追加する前に少しリファクタリングが必要です。
既に.mainMenuクラスがあるので、これを活用しましょう。nav ulセレクタを全てそのクラスに置き換えます。繰り返しますが、これにより詳細度を低く保ちつつ、その要素が何をするのかがより明確になります。
@layer components {
/* ... */
.mainMenu {
display: flex;
flex-wrap: wrap;
list-style: none;
}
.mainMenu li {
margin: 0 4px;
}
.mainMenu li a {
color: #fff;
text-decoration: none;
font-size: 16px;
/* ... */
}
.mainMenu li a:where(.active, .hover) {
color: #fff;
background: #1d1e21;
}
.mainMenu li a.active:hover {
background-color: #5865f2;
}
}コードには、小さい画面でナビゲーションが折りたたまれたときに、「開く」状態と「閉じる」状態を切り替えるために使われるボタンも2つあります。これは.mainMenuコンポーネントに特有のものなので、全てをcomponentsレイヤーにまとめておきます。その過程で、セレクタを結合・簡略化して、よりクリーンで読みやすいスタイルにすることができます。
@layer components {
/* ... */
nav:is(.openMenu, .closeMenu) {
font-size: 25px;
display: none;
cursor: pointer;
color: #fff;
}
}また、CSS内の他のいくつかのセレクタがHTMLのどこにも使われていないことに気づきました。そこで、コードをきれいな状態に保つために、それらのスタイルを削除しました。これを行うための自動化された方法もあります。
メディアクエリ
メディアクエリは専用のレイヤー(@layer responsive)を持つべきでしょうか、それとも対象要素と同じレイヤーにあるべきでしょうか?このプロジェクトのスタイルをリファクタリングしている間、私はこの問題に本当に苦労しました。いくつか調査とテストを行った結果、私の判断は後者、つまりメディアクエリは影響を与える要素と同じレイヤーにあるべきだ、というものです。
私の理由は、それらを一緒に保つことで、
- レスポンシブスタイルと、そのベースとなる要素のスタイルを一緒に維持できる。
- 上書きが予測可能になる。
- 現代のWeb開発で一般的なコンポーネントベースのアーキテクチャとうまく調和する。
しかし、これはレスポンシブロジックがレイヤー間に散らばることも意味します。ですが、要素がスタイリングされるレイヤーと、そのレスポンシブな振る舞いが管理されるレイヤーとの間にギャップがあるよりはマシです。私にとって、それは避けたいアプローチです。なぜなら、あるレイヤーでスタイルを更新し、それに対応するレスポンシブスタイルをresponsiveレイヤーで更新し忘れがちだからです。
もう一つの大きなポイントは、同じレイヤー内のメディアクエリは、その要素と同じ優先順位を持つということです。これは、CSSカスケードをシンプルで予測可能に保ち、スタイルの競合をなくすという私の全体的な目標と一致しています。
さらに、CSSネスティング構文は、メディアクエリと要素の関係を非常に明確にします。componentsレイヤーにメディアクエリをネストした場合の見た目の省略例を次に示します。
@layer components {
.mainMenu {
display: flex;
flex-wrap: wrap;
list-style: none;
}
@media (max-width: 900px) {
.mainMenu {
width: 100%;
text-align: center;
height: 100vh;
display: none;
}
}
}これにより、コンポーネントの子要素のスタイル(例:nav .openMenuとnav .closeMenu)もネストできます。
@layer components {
nav {
&.openMenu {
display: none;
@media (max-width: 900px) {
&.openMenu {
display: block;
}
}
}
}
}タイポグラフィとボタン
.titleと.subtitleはタイポグラフィのコンポーネントと見なせるので、それらと関連するレスポンシブスタイルは、ご想像の通り、componentsレイヤーに入ります。
@layer components {
.title {
font-size: 40px;
font-weight: 700;
/* etc. */
}
.subtitle {
color: rgba(255, 255, 255, 0.75);
font-size: 15px;
/* etc.. */
}
@media (max-width: 420px) {
.title {
font-size: 30px;
}
.subtitle {
font-size: 12px;
}
}
}ボタンについてはどうでしょう?多くのWebサイトと同様に、このサイトにもそのコンポーネントのための.btnクラスがあるので、それらもそこに入れてしまいましょう。
@layer components {
.btn {
color: #fff;
background-color: #1d1e21;
font-size: 18px;
/* etc. */
}
.btn-primary {
background-color: #5865f2;
}
.btn-secondary {
transition: all 0.3s ease-in-out;
}
.btn-primary:hover {
background-color: #5865f2;
box-shadow: 0px 0px 8px 2px rgba(88, 101, 242, 0.5);
/* etc. */
}
.btn-secondary:hover {
background-color: #1d1e21;
background-color: rgba(88, 101, 242, 0.7);
}
@media (max-width: 420px) {
.btn {
font-size: 14px;
margin: 2px;
padding: 8px 13px;
}
}
@media (max-width: 335px) {
.btn {
display: flex;
flex-direction: column;
}
}
}最後のレイヤー
まだutilitiesレイヤーには触れていませんでしたね!私はこのレイヤーを、特定の目的のために設計されたヘルパークラス用に確保しています。例えばコンテンツを非表示にしたり、このケースでは、ぴったりな.noselectクラスがあります。これには、要素の選択を無効にするという単一の再利用可能な目的があります。
というわけで、これが私たちのutilitiesレイヤーにおける唯一のスタイルルールになります。
@layer utilities {
.noselect {
-webkit-touch-callout: none;
-webkit-user-select: none;
-khtml-user-select: none;
-webkit-user-drag: none;
-moz-user-select: none;
-ms-user-select: none;
user-select: none;
}
}以上です!私たちは実在するプロジェクトのCSSを、CSSカスケードレイヤーを使うように完全にリファクタリングしました。作業開始時点のコードと最終的なコードを比較することができます。
全てが簡単だったわけではない
カスケードレイヤーでの作業が困難だったというわけではありませんが、その過程でいくつかの厄介な点があり、一度立ち止まって自分が何をしているのかを慎重に考えさせられました。
作業中にいくつかのメモを取りました。
-
既存のプロジェクトでどこから手をつけるべきかを判断するのは難しい。 しかし、最初にレイヤーを定義し、その優先順位レベルを設定することで、既存のCSSに完全には慣れていなくても、特定のスタイルをどのように、どこに移動させるかを決定するためのフレームワークができました。これにより、自分を疑ったり、余分で不要なレイヤーを定義したりする状況を避けることができました。
-
ブラウザサポートは依然として問題! 私がこれを書いている時点で、カスケードレイヤーは94%のサポート率を誇りますが、あなたのサイトがレイヤー化されたスタイルをサポートできないレガシーブラウザに対応する必要があるかもしれません。
-
メディアクエリがプロセスの中でどこに当てはまるのかが明確ではなかった。 メディアクエリは、それらが最も効果的に機能する場所を見つけるという難題を私に突きつけました。セレクタと同じレイヤーにネストするのか、それとも完全に別のレイヤーにするのか?ご存じの通り、私は前者を選びました。
-
!importantキーワードの扱いは、まるで綱渡りのようです。これはレイヤーの優先順位システム全体を反転させてしまうのですが、このプロジェクトでは至る所で使われていました。これらを一つずつ取り除いていくと、既存のCSSアーキテクチャが崩れていきます。そのため、コードをリファクタリングしつつ既存の挙動を壊さないように修正し、スタイルが最終的にどう適用される(カスケードする)のかを正確に把握する、というバランス感覚が求められます。
全体として、CSSカスケードレイヤーのためにコードベースをリファクタリングすることは、一見すると少し気が遠くなる作業です。しかし重要なのは、物事を複雑にしているのはレイヤーそのものではなく、既存のコードベースであると認識することです。
新しいアプローチがエレガントであっても、誰かの既存のアプローチを新しいものに完全に刷新するのは難しいものです。
カスケードレイヤーが役立った点(と、そうでもなかった点)
レイヤーを確立したことで、コードは間違いなく改善されました。未使用のスタイルや競合するスタイルを削除できたので、パフォーマンスベンチマークにもいくつか改善が見られるはずですが、真の価値は、より保守しやすくなったスタイル一式にあります。必要なものを見つけ、特定のスタイルルールが何をしているのかを把握し、今後新しいスタイルをどこに挿入すればよいかが、より簡単になりました。
同時に、カスケードレイヤーが銀の弾丸のような解決策だとは言いません。忘れてはならないのは、CSSはそれがクエリするHTML構造と本質的に結びついているということです。もし扱っているHTMLが構造化されておらず、divの乱用に苦しんでいるのであれば、その混乱を解きほぐす努力はより大きくなり、同時にマークアップの書き換えも伴うと見て間違いないでしょう。
カスケードレイヤーのためのCSSリファクタリングは、メンテナンス性の向上だけでも、間違いなくその価値があります。
ゼロから始めて、作業を進めながらレイヤーを定義していく方が「簡単」かもしれません。なぜなら、整理すべき継承されたオーバーヘッドや技術的負債が少ないからです。しかし、既存のコードベースから始めなければならない場合は、まずスタイルの複雑さを解きほぐし、どの程度のリファクタリングが必要かを正確に判断する必要があるかもしれません。
]]>想像してみてください。あなたは夢のNext.jsアプリケーションを構築し、ネイティブのfetch関数を使って楽しくAPIコールを行っています。全てが順調に見えましたが、アプリケーションを本番環境にデプロイした途端、事態は一変します。反復的なエラー処理のコードに溺れ、コンポーネントのあちこちに散らばった認証トークンと格闘し、なぜ一部のリクエストがサーバーでは成功するのにクライアントでは失敗するのか、そのデバッグに髪をかきむしる日々……。
聞き覚えがありませんか?あなただけではありません。Next.jsはfetchを強力なキャッシュ機能や再検証機能で拡張していますが、中心的な課題は残っています。本番環境に対応した堅牢なAPIレイヤーを構築するには、素のfetchコールだけでは不十分なのです。
本記事では、あなたのAPIレイヤーを頭痛の種から、扱うのが楽しくなるものへと変える、本番環境対応のfetchラッパーを作成します。その構築方法だけでなく、なぜそれぞれの決定が重要なのか、そしてそれがNext.js特有の実行モデルにどう適合するのかを掘り下げていきましょう。
素のfetchが抱える問題点(Next.jsでも)
まず、多くの開発者が最初にfetchに出会ったときに書くコードを見てみましょう。
// ナイーブなアプローチ - 本番環境では使わないでください!
async function getUser(id) {
const response = await fetch(`/api/users/${id}`);
const user = await response.json();
return user;
}これは一見無害に見えますが、時を刻む時限爆弾です。APIが404を返すと、次のようになります。
// エラーレスポンスからJSONをパースしようとすると、エラーがthrowされます
const user = await getUser('nonexistent-id'); // 💥 ドカン!根本的な問題は、fetchがHTTPのエラーステータスを例外として扱わない点にあります。404、500、その他のエラーステータスも、fetchにとっては「成功した」リクエストと見なされます。fetchがrejectするのはネットワークエラーの場合のみです。そのため、Next.jsを使っている場合でも、手動でresponse.okをチェックし、適切にエラーを処理する必要があります。
しかし、これはほんの始まりに過ぎません。実際のアプリケーションでは、以下のような事柄も処理する必要があります。
- 保護されたルートのための認証トークン
- アプリ全体で一貫したエラーハンドリング
- リクエスト/レスポンスの変換(JSONの自動パースなど)
- ローディング状態とエラーバウンダリ
- 型安全性のためのTypeScriptサポート
- Next.jsにおけるサーバーとクライアントのコンテキストによる挙動の違い
これら全ての問題をエレガントに解決するラッパーを構築していきましょう。
Fetchラッパーのアーキテクチャ設計
コードに入る前に、理想的なラッパーが提供すべきものを考えてみましょう。
- HTTPステータスコードの自動エラーハンドリング
- 適切なエラー処理を備えた組み込みのJSONパース
- 認証トークンの管理
- 適切な型付けによるTypeScriptサポート
- Next.jsのコンテキスト認識(サーバー vs. クライアント)
- さまざまな環境に対応できる拡張可能な設定
- 自然に使える一貫したAPI
このラッパーを、退屈でエラーを起こしやすいタスクを全て処理しつつ、クリーンで予測可能なインターフェースを提供してくれる、親切なアシスタントだと考えてください。
基盤の構築:ラッパーのコア構造
まずは基本的な構造から始めましょう。Next.jsの慣習に従い、lib/api.tsというファイルを作成します。
// lib/api.ts
interface ApiConfig {
baseUrl?: string;
defaultHeaders?: Record<string, string>;
timeout?: number;
}
interface ApiResponse<T = any> {
data: T;
status: number;
headers: Headers;
}
class ApiError extends Error {
constructor(
message: string,
public status: number,
public response?: Response
) {
super(message);
this.name = 'ApiError';
}
}
class ApiClient {
private config: Required<ApiConfig>;
constructor(config: ApiConfig = {}) {
this.config = {
baseUrl: config.baseUrl || '',
defaultHeaders: {
'Content-Type': 'application/json',
...config.defaultHeaders,
},
timeout: config.timeout || 10000,
};
}
private async makeRequest<T>(
endpoint: string,
options: RequestInit = {}
): Promise<ApiResponse<T>> {
// 次にこれを実装します
}
}なぜクラスベースのアプローチなのか? Reactでは関数型アプローチが人気ですが、クラスにはいくつかの利点があります。
- 状態管理: 設定や、場合によってはキャッシュデータを保存できます。
- メソッドチェーン: 流れるようなAPIメソッドを後からでも追加できます。
- 継承: チームは特定のユースケースのためにベースクラスを拡張できます。
- カプセル化: privateメソッドで実装の詳細を隠蔽できます。
ラッパーの心臓部:リクエストロジック
では、コアとなるリクエストロジックを実装しましょう。ここが肝心な部分です。
// lib/api.ts (続き)
class ApiClient {
// ... 前のコード
private async makeRequest<T>(
endpoint: string,
options: RequestInit = {}
): Promise<ApiResponse<T>> {
const url = this.buildUrl(endpoint);
const requestOptions = this.buildRequestOptions(options);
try {
// タイムアウト用のAbortControllerを作成
const controller = new AbortController();
const timeoutId = setTimeout(() => controller.abort(), this.config.timeout);
const response = await fetch(url, {
...requestOptions,
signal: controller.signal,
});
clearTimeout(timeoutId);
// ここがキーポイントです。ステータスをチェックし、エラーの場合はthrowします
if (!response.ok) {
throw new ApiError(
`HTTP ${response.status}: ${response.statusText}`,
response.status,
response
);
}
// JSONを安全にパース
const data = await this.parseResponse<T>(response);
return {
data,
status: response.status,
headers: response.headers,
};
} catch (error) {
if (error.name === 'AbortError') {
throw new ApiError('Request timeout', 408);
}
throw error;
}
}
private buildUrl(endpoint: string): string {
// 絶対URLと相対URLの両方を処理
if (endpoint.startsWith('http')) {
return endpoint;
}
return `${this.config.baseUrl}${endpoint.startsWith('/') ? endpoint : `/${endpoint}`}`;
}
private buildRequestOptions(options: RequestInit): RequestInit {
return {
...options,
headers: {
...this.config.defaultHeaders,
...options.headers,
},
};
}
private async parseResponse<T>(response: Response): Promise<T> {
const contentType = response.headers.get('content-type');
if (contentType?.includes('application/json')) {
try {
return await response.json();
} catch (error) {
throw new ApiError('Invalid JSON response', response.status, response);
}
}
// テキストレスポンスを処理
return (await response.text()) as unknown as T;
}
}ここでの重要な点は、fetchの挙動をより直感的なものに変換していることです。response.okをチェックし、HTTPエラーに対してエラーをthrowすることで、アプリケーション全体でエラーハンドリングが予測可能で一貫したものになります。
HTTPメソッドの便利なラッパーメソッドを追加する
次に、開発者が実際に使用するメソッドを追加しましょう。
// lib/api.ts (続き)
class ApiClient {
// ... 前のコード
async get<T>(endpoint: string, options?: RequestInit): Promise<ApiResponse<T>> {
return this.makeRequest<T>(endpoint, { ...options, method: 'GET' });
}
async post<T>(
endpoint: string,
data?: any,
options?: RequestInit
): Promise<ApiResponse<T>> {
return this.makeRequest<T>(endpoint, {
...options,
method: 'POST',
body: data ? JSON.stringify(data) : undefined,
});
}
async put<T>(
endpoint: string,
data?: any,
options?: RequestInit
): Promise<ApiResponse<T>> {
return this.makeRequest<T>(endpoint, {
...options,
method: 'PUT',
body: data ? JSON.stringify(data) : undefined,
});
}
async delete<T>(endpoint: string, options?: RequestInit): Promise<ApiResponse<T>> {
return this.makeRequest<T>(endpoint, { ...options, method: 'DELETE' });
}
async patch<T>(
endpoint: string,
data?: any,
options?: RequestInit
): Promise<ApiResponse<T>> {
return this.makeRequest<T>(endpoint, {
...options,
method: 'PATCH',
body: data ? JSON.stringify(data) : undefined,
});
}
}POST、PUT、PATCHリクエストのデータを自動的にJSON.stringifyしている点に注目してください。これにより、リクエストボディのstringifyを忘れるという、もう一つのよくあるバグの原因を排除します。
認証:トークン管理の課題
Next.jsでは認証が面白くなるところです。従来のSPAとは異なり、サーバーサイドとクライアントサイドの両方のコンテキストを考慮する必要があります。認証サポートを追加しましょう。
// lib/api.ts (続き)
interface AuthConfig {
tokenProvider?: () => Promise<string | null> | string | null;
tokenHeader?: string;
tokenPrefix?: string;
}
class ApiClient {
private authConfig: AuthConfig;
constructor(config: ApiConfig = {}, authConfig: AuthConfig = {}) {
// ... 前のコンストラクタのコード
this.authConfig = {
tokenHeader: 'Authorization',
tokenPrefix: 'Bearer',
...authConfig,
};
}
private async buildRequestOptions(options: RequestInit): Promise<RequestInit> {
const headers = { ...this.config.defaultHeaders };
// 利用可能な場合は認証トークンを追加
if (this.authConfig.tokenProvider) {
const token = await this.authConfig.tokenProvider();
if (token) {
headers[this.authConfig.tokenHeader!] =
`${this.authConfig.tokenPrefix} ${token}`;
}
}
return {
...options,
headers: {
...headers,
...options.headers,
},
};
}
// makeRequestを更新して、非同期のbuildRequestOptionsを使用するようにする
private async makeRequest<T>(
endpoint: string,
options: RequestInit = {}
): Promise<ApiResponse<T>> {
const url = this.buildUrl(endpoint);
const requestOptions = await this.buildRequestOptions(options);
// ... メソッドの残りの部分は同じ
}
}ここではトークンプロバイダーパターンが非常に重要です。トークンを直接保存する代わりに、それを取得できる関数を提供します。これにより、以下のことが可能になります。
- さまざまなソース(localStorage、Cookie、メモリ)から新しいトークンをフェッチする
- トークン更新ロジックを透過的に処理する
- 異なるストレージメカニズムを持つサーバーとクライアントの両方のコンテキストで動作する
コンテキストを意識したAPIインスタンスの作成
ここからがNext.jsならではの魔法の出番です。実行コンテキストごとに異なる設定が必要です。
// lib/api.ts (続き)
// クライアントサイドのトークンプロバイダー(ブラウザのみ)
const getClientToken = (): string | null => {
if (typeof window === 'undefined') return null;
return localStorage.getItem('auth_token');
};
// サーバーサイドのトークンプロバイダー(SSR用)
const getServerToken = (): string | null => {
// サーバーコンポーネントでは、Cookieからトークンを取得することがあります
// これは簡略化された例です - 実際にはNext.jsのheaders()を使用します
return null;
};
// コンテキストごとに異なるインスタンスを作成
export const clientApi = new ApiClient(
{
baseUrl: process.env.NEXT_PUBLIC_API_URL || '/api',
},
{
tokenProvider: getClientToken,
}
);
export const serverApi = new ApiClient(
{
baseUrl: process.env.API_URL || process.env.NEXT_PUBLIC_API_URL || 'http://localhost:3000/api',
},
{
tokenProvider: getServerToken,
}
);
// 利便性のために、コンテキストを意識したAPIをエクスポート
export const api = typeof window === 'undefined' ? serverApi : clientApi;これは非常に画期的なアプローチです。コンテキストを意識したインスタンスを作成することで、サーバーとクライアントで異なる挙動をさせながら、どこでも同じAPIインターフェースを使用できます。サーバーインスタンスは絶対URLとサーバーサイド認証を使用し、クライアントインスタンスは相対URLとブラウザストレージを使用するといった具合です。
TypeScript:型安全にする
ラッパーをさらに堅牢にするために、適切なTypeScriptサポートを追加しましょう。
// lib/api.ts - TypeScriptインターフェースの追加
interface User {
id: string;
name: string;
email: string;
}
interface ApiEndpoints {
// APIの形状を定義
'/users': {
GET: { data: User[] };
POST: { body: Omit<User, 'id'>; data: User };
};
'/users/:id': {
GET: { data: User };
PUT: { body: Partial<User>; data: User };
DELETE: { data: { success: boolean } };
};
}
// 型安全なラッパーメソッド
class TypedApiClient extends ApiClient {
async getTyped<T extends keyof ApiEndpoints, M extends keyof ApiEndpoints[T]>(
endpoint: T,
method: M extends 'GET' ? 'GET' : never
): Promise<ApiEndpoints[T][M] extends { data: infer D } ? D : never> {
const response = await this.get(endpoint as string);
return response.data;
}
// POST、PUT、DELETEなどについても同様のメソッド...
}これにより複雑さは増しますが、素晴らしい開発者体験を提供します。IDEがエンドポイントをオートコンプリートし、タイプミスを検知し、正しいペイロードの型を渡していることを保証してくれます。
Next.jsコンポーネントでの使用方法
では、実際のNext.jsのシナリオで、このラッパーがどのように輝くかを見てみましょう。
サーバーコンポーネントでの使用例
// app/users/page.tsx - サーバーコンポーネント
import { serverApi } from '@/lib/api';
interface User {
id: string;
name: string;
email: string;
}
export default async function UsersPage() {
try {
const { data: users } = await serverApi.get<User[]>('/users');
return (
<div>
<h1>Users</h1>
{users.map(user => (
<div key={user.id}>{user.name}</div>
))}
</div>
);
} catch (error) {
if (error instanceof ApiError) {
return <div>Error: {error.message}</div>;
}
return <div>Something went wrong</div>;
}
}Reactフックを使用したクライアントコンポーネント
// components/UserProfile.tsx - クライアントコンポーネント
'use client';
import { useState, useEffect } from 'react';
import { clientApi, ApiError } from '@/lib/api';
interface User {
id: string;
name: string;
email: string;
}
interface UserProfileProps {
userId: string;
}
export function UserProfile({ userId }: UserProfileProps) {
const [user, setUser] = useState<User | null>(null);
const [loading, setLoading] = useState(true);
const [error, setError] = useState<string | null>(null);
useEffect(() => {
async function fetchUser() {
try {
setLoading(true);
const { data } = await clientApi.get<User>(`/users/${userId}`);
setUser(data);
} catch (err) {
if (err instanceof ApiError) {
setError(err.message);
} else {
setError('An unexpected error occurred');
}
} finally {
setLoading(false);
}
}
fetchUser();
}, [userId]);
if (loading) return <div>Loading...</div>;
if (error) return <div>Error: {error}</div>;
if (!user) return <div>User not found</div>;
return (
<div>
<h2>{user.name}</h2>
<p>{user.email}</p>
</div>
);
}ルートハンドラでの使用例
// app/api/users/route.ts - APIルートハンドラ
import { NextRequest } from 'next/server';
import { serverApi } from '@/lib/api';
export async function GET(request: NextRequest) {
try {
// 外部APIにリクエストを転送
const { data } = await serverApi.get('/external-api/users');
return Response.json(data);
} catch (error) {
if (error instanceof ApiError) {
return Response.json(
{ error: error.message },
{ status: error.status }
);
}
return Response.json(
{ error: 'Internal server error' },
{ status: 500 }
);
}
}高度な機能:キャッシュとリクエストの重複排除
本番アプリケーションでは、キャッシュやリクエストの重複排除を追加したくなるかもしれません。
// lib/api.ts - 高度な機能
class ApiClient {
private cache = new Map<string, { data: any; timestamp: number }>();
private pendingRequests = new Map<string, Promise<any>>();
async get<T>(
endpoint: string,
options?: RequestInit & { cache?: boolean; cacheTTL?: number }
): Promise<ApiResponse<T>> {
const cacheKey = `GET:${endpoint}`;
const now = Date.now();
// まずキャッシュをチェック
if (options?.cache) {
const cached = this.cache.get(cacheKey);
const ttl = options.cacheTTL || 60000; // デフォルトは1分
if (cached && (now - cached.timestamp) < ttl) {
return { data: cached.data, status: 200, headers: new Headers() };
}
}
// 同時リクエストを重複排除
if (this.pendingRequests.has(cacheKey)) {
return this.pendingRequests.get(cacheKey)!;
}
const requestPromise = this.makeRequest<T>(endpoint, { ...options, method: 'GET' });
this.pendingRequests.set(cacheKey, requestPromise);
try {
const response = await requestPromise;
// 成功したレスポンスをキャッシュ
if (options?.cache && response.status === 200) {
this.cache.set(cacheKey, { data: response.data, timestamp: now });
}
return response;
} finally {
this.pendingRequests.delete(cacheKey);
}
}
}エラーハンドリング戦略
このラッパーの最大の利点の一つは、エラーハンドリングを一元化できることです。以下にその活用方法を示します。
// lib/error-handler.ts
import { ApiError } from './api';
export function handleApiError(error: unknown): string {
if (error instanceof ApiError) {
switch (error.status) {
case 401:
// ログインにリダイレクトするか、トークンを更新
return '続行するにはログインしてください';
case 403:
return 'この操作を実行する権限がありません';
case 404:
return '要求されたリソースが見つかりませんでした';
case 500:
return 'サーバーエラーです。後でもう一度お試しください';
default:
return error.message;
}
}
return '予期しないエラーが発生しました';
}
// コンポーネントでの使用例
import { handleApiError } from '@/lib/error-handler';
try {
await api.get('/protected-resource');
} catch (error) {
const errorMessage = handleApiError(error);
toast.error(errorMessage);
}ファイル構造と整理
APIレイヤーを整理するため、以下のようなファイル構造をお勧めします。
lib/
├── api/
│ ├── index.ts # メインのAPIクライアントとエクスポート
│ ├── types.ts # TypeScriptインターフェース
│ ├── endpoints.ts # エンドポイントの定義
│ └── error-handler.ts # エラーハンドリングユーティリティ
├── hooks/
│ ├── useApi.ts # カスタムReactフック
│ └── useAuth.ts # 認証フック
└── utils/
└── api-helpers.ts # ユーティリティ関数この構造により、APIレイヤーが整理され、チームメンバーが必要なものを簡単に見つけられるようになります。
ベストプラクティスとよくある落とし穴
推奨事項:
- 常にエラーを明示的に処理する - 捕捉されないまま放置しない
- リクエスト/レスポンスの形状にTypeScriptインターフェースを使用する
- 異なる環境やサービスごとに別のインスタンスを作成する
- コンポーネントに適切なローディング状態を実装する
- ネットワークリクエストを減らすため、必要に応じてレスポンスをキャッシュする
非推奨事項:
- 本番アプリケーションで機密性の高いトークンをlocalStorageに保存しない(httpOnly Cookieを使用する)
- HTTPステータスコードを無視しない - 異なるステータスを適切に処理する
- レンダーメソッドでAPIコールを行わない - useEffectまたはサーバーコンポーネントを使用する
- リクエストタイムアウトを忘れない - ハングするリクエストを防ぐ
- URLをハードコードしない - 環境変数を使用する
よくある落とし穴:
- 「私のマシンでは動くのに」という罠: 常に異なるNext.jsのコンテキスト(サーバー、クライアント、APIルート)でテストする。
- トークン更新地獄: 必要になる前に、適切なトークン更新ロジックを実装する。
- エラーバウンダリの軽視: APIを利用するコンポーネントをエラーバウンダリでラップする。
大局的に見る:なぜこれが重要なのか
堅牢なfetchラッパーを構築することは、単にコードをクリーンにすることだけが目的ではありません。アプリケーションのための信頼性の高い基盤を築くことが重要です。APIレイヤーがしっかりしていると、以下のことが可能になります。
- ネットワーク問題のデバッグではなく、機能開発に集中できる
- リクエスト処理の一貫性が保たれているため、自信を持ってスケールできる
- 明確で文書化されたAPIインターフェースにより、新しい開発者のオンボーディングが迅速になる
- 一元化されたエラーハンドリングと型付けにより、より良いコード品質を維持できる
これは未来の自分への投資だと考えてください。このラッパーの構築に費やす1時間は、本番環境の問題をデバッグしたり、反復的なエラー処理コードを書いたり、ネットワーク関連のバグを探したりする何十時間もの時間を節約してくれるでしょう。
結論:APIレイヤーを競争上の優位性として
私たちは、素のfetchコールの質素な始まりから、認証、エラー、TypeScriptの安全性、そしてNext.js特有の実行コンテキストを処理する、洗練された本番環境対応のAPIクライアントへと旅をしてきました。しかし、重要なのは、これは単により良いコードを書くことだけではないということです。
今日の開発環境において、APIレイヤーの品質は、チームの開発速度とアプリケーションの信頼性に直接影響します。巧みに作られたfetchラッパーは、チームが迅速に動き、自信を持って製品を届けられるようにする、目に見えないインフラとなるのです。
私たちが探求してきたパターン(コンテキスト認識、適切なエラーハンドリング、TypeScriptの統合、そして考え抜かれたアーキテクチャ)は、単なる「あれば良いもの」ではありません。それらは、本番環境で壊れやすい脆弱なアプリケーションと、現実世界の事象を適切に処理する堅牢なシステムの分かれ目となるのです。
Reactがこれまでどのように開発されてきたかについての詳細な考察と、コミュニティでよく見られる混乱や懸念事項についての説明
はじめに
今日、Reactとそのエコシステムの状況は複雑で分裂しており、成功、懐疑、そして論争が入り混じっています。
ポジティブな面として、Reactは最も広く利用されているUIフレームワークであり、そのコンセプトはJSエコシステムの他の部分にも影響を与えてきました。Reactチームは数年にわたる開発の末、先日React 19をリリースしました。これは、公式に安定版となったReact Server Componentsのサポート、Promiseを扱うための新しいuseフック、複数の新しいフォーム連携、そして長らく非推奨であった多くの時代遅れな機能の削除を含む、大規模なリリースでした。
しかし、私が観察し、また経験してきたところでは、Reactコミュニティでは、Reactの向かう先やその開発方法、推奨される利用アプローチ、そしてReactチームとコミュニティ間の相互作用について、たくさんの意見が交わされています。これは、過去数年間にわたってReactおよびWeb開発コミュニティ全体で飛び交ってきた何十もの異なる議論や、Reactの動作に関する特定の技術的懸念、他の類似JSフレームワークとの比較、そして今後Webアプリをどのように構築すべきかといった問題と重なっています。
事態をさらに悪化させているのは、誰もがこれらの懸念の異なる一部分について議論や討論をしており、表明されている懸念の多くが誤りであるか、完全なFUDであることです。残念ながら、これらの議論と恐怖は、Reactチームと開発者間の適切なコミュニケーションの不足などによって、さらに複雑化しています。これら全てが密接に絡み合っているのです。 不安や懸念、不透明感
私はソーシャルメディア上で関連する多くの議論に参加してきました。Reactチームを擁護し、また批判するコメントを数多く書き、彼らが特定の決定を下した理由や物事の実際の経緯を説明し、ドキュメントや説明の改善を求め、その他多くの活動を行ってきました。 これらのトピックのほんの一部をカバーしようとするだけでも、広範で詳細な記事が必要となります(そして私は、「Reactは悪いのか/Reactは他のツールと比べてどうなのか?」という、さらにスコープ外のトピックには触れるつもりすらありません)。しかし、あまりにも多くの時間を討論と説明に費やしてきた今、これらのトピックの多くをまとめて扱う統合的な記事を書く必要性を感じています。 また、私は過去にこの記事のトピックに基づいた講演も行っています。
この記事の目的
この記事における私の目的は以下の通りです。
- Reactが時間と共にどのように発展してきたかの概要を説明する
- Reactの開発を推進する力を説明する
- Reactの最近の開発の方向性がなぜ、どのようにして起こったのかを明確にし、その作業の背景にあるアーキテクチャ上の決定のいくつかを説明する
- Reactの開発の背後にある動機と意図に関するFUDと混乱を明確にし、払拭する
背景:私のReactコミュニティにおける役割と関与
(もしくは「私は何者で、なぜ私の説明を信頼すべきで、そしてなぜあなたはこの件に関する私の意見を気にかけるべきなのか? 😄」)
私は実際のReactチームの一員ではありませんし、これまでもそうであったことはありません。とはいえ、私は2015年からReactエコシステムに深く関わっており、MetaやVercelの外部の人間としては、誰よりも「Reactコミュニティのインナーサークル」の一員であると言って差し支えないでしょう。
要約すると、以下の通りです。
- 2015年からReactを使用
- Reduxライブラリファミリーのメンテナーであり、Reactにコントリビュートし、Reactエコシステムの議論に関与
- ReactとReduxに関する多数の詳細なチュートリアルを執筆し、ReactとReduxについて頻繁に講演
- そのほとんどの期間、主要なReactコミュニティセクションのモデレーターとして関与
もし詳細を知りたければ:
私の実績、関与、経歴
私は2015年半ばにReactを学び始めました。それ以前は、Backbone、jQuery、GWTを使って地理空間情報の可視化アプリをいくつか構築していました。それから1年の間に、私はいくつかのReactチュートリアルを読むところから、Reactifluxのチャットチャンネルを眺めているうちに、非常に多くの質問に答えるようになってモデレーターになり、ReduxのFAQを自ら執筆し、そして新しいReduxのメンテナーとしてその役割を引き継ぐことになりました。
私は2016年半ばからReduxをメンテナンスしています。現代的なReduxアプリの記述方法としてRedux Toolkitを作成しました。Reduxに取り組む中で、v5以降のReact-Reduxの全てのバージョンを設計し、リリースしてきました。Reactが外部の状態管理ライブラリとどのように連携すべきかについてReactチームと何度も話し合い、useSyncExternalStoreフックの開発においては、私が唯一のアルファテスターでした。
私は、「Redux Essentials」チュートリアルや、広く称賛されている「Reactのレンダリングビヘイビアへのガイド」の記事(この記事は、Reactが実際にどのように動作するかの最良の説明として、コミュニティで常に推奨されています)をはじめ、人々がReactとReduxをどのように使い、それらがどのように動作するかを教えるために、何十万語ものチュートリアルやブログ記事を執筆してきました。私は、Github、Reactiflux Discord、Reddit、Twitter、Hacker News、Stack Overflowにわたって、React、Redux、JSのあらゆることについて、何千ものコメントや質問に回答してきました。「Reactコミュニティのテクニカルサポート」、そして「Reactに関する全ての事柄のマスターアーカイバー兼インデクサー」と呼ばれてきました。
私は数多くのReact関連カンファレンスで、Reactの仕組みから広く使われているOSSライブラリをメンテナンスする上でのベストプラクティスや教訓に至るまで、さまざまなトピックについて登壇してきました。Reactiflux Discordが主催する現在も続くポッドキャスト『This Month in React』(このポッドキャストでは、Reactとコミュニティに関する最新のニュース、リリース、知見について話しています)をはじめ、数多くのポッドキャストでReactとReduxについて議論してきました。
私は、React Hooksの初期プライベートプレビューのフィードバックグループや、招待制でありながら公開されていたReact 18ワーキンググループの一員であり、両方のリリースについて、設計、ドキュメント、利用方法の側面でフィードバックを提供しました。
私はReactiflux Discordの管理者であり、数年間にわたりthe/r/reactjs subredditの主要な現役モデレーターを務めています。
私は、Reactのリポジトリや内部のコードを深く掘り下げてきました。例えば、Reactのプロダクションビルド用のソースマップを生成するPRを提出したり、タイムトラベルデバッグを用いてReact DevToolsをReplayのDevToolsに統合したりしました。
これらの実績を挙げたのは、私がReactの開発方法、Reactコミュニティで何が起こっているか、Reactチームの内部で何が起こっているか、そして人々がReactとReduxを学ぶのを助けることに関して、長い歴史と専門知識を持っていることを示すためです。
バイアスと注意点
ここはインターネットなので、私がこれを書くことに対して皆さんが抱くかもしれないいくつかの懸念を先取りしておこうと思います。
私は間違いなく常に正しいわけではありませんし、知識の限界、誤解、あるいは要約のしすぎによって、いくつかの事柄を誤って説明してしまうことは間違いありません。とはいえ、私は歴史、動機、行動をできる限り正直かつ正確に記述するための最善の努力としてこれを書いています。
さらに詳しくは:
より詳細なバイアスと注意点
私がReduxのメンテナーであることは、Reactの使われ方や、私が普段扱う問題の種類に対する私自身の見方に、偏りをもたらしています。
私は2015年から一貫して何らかの形でReactを使い続けてきましたが、私自身のReactを使った経験は、時間と共により限定的でニッチなものになってきました。私が携わったReactアプリのほとんどは、配布先が限定された社内ツールであり、その大半は「ブラウザ上のデスクトップ風アプリ」、つまりルーティングやCRUDのような挙動すらない、真のSPAでした。CRUD/ダッシュボード形式のアプリに1つ携わったことはありますが、その範囲は限定的でした。巨大なオーディエンスを持つアプリを構築したことはなく、SSRやRSCを実際に使ったこともなく、国際化(i18n)やその他の大規模なスケーリングに関する懸念に頭を悩ませる必要もありませんでした。私は時間の多くをライブラリや開発者ツールの作業に費やしており、「典型的な」Reactアプリの日々の開発に費やす時間ははるかに少ないのです。
私は、平均的なReactアプリ開発者が決して耳にしたり気にしたりすることのない、Reactコミュニティの専門的で内輪な議論を読んだり、参加したりしてきました。
私はReactチームとオンラインおよび対面で個人的なやり取りをしてきましたが、それらは非常にポジティブなものもあれば、非常にネガティブで不満のたまるものもありました。これらは私自身の視点を色づけています。しかし、コミュニティの他のメンバーとも十分に議論を重ねてきたので、他の多くの人々も私の懸念や意見を共有していると確信しています。
私の通常の執筆スタイルは、できるだけ多くの参照や情報源へリンクを張ることです。この記事ではそれを試みますが、これらの歴史的な記述や見解の多くは、特定の情報源を見つけるのが難しいでしょう。ですから、要約されているとしても、私がそれらを正確に記述するために最善を尽くしていることを信じてください。
さて、これらの注意点を全て述べたところで、本題に入りましょう。
Reactの簡単な歴史
初期の歴史は、Reactドキュメンタリーなど他の場所でより詳しく語られていますが、この記事の残りの部分の文脈を提供するために少し触れておきます。
Reactは2011年から12年頃にFacebook内部で開発され、2013年にオープンソース化されました。外部のコントリビューターも少数集まりましたが、最近まで実際の開発は全てFacebook/Meta内部のReactコアチームによって行われていました。
Reactの核となるコンセプト(コンポーネント、props、state、データフロー)は常に同じですが、実装の詳細、公開API、スコープの広さは時間と共に変化してきました。ReactはcreateClassでコンポーネントを作成する方式から、ES6のclass MyComponent extends React.Componentへ、そしてfunction MyComponent()へと移行しました。ReactはWeb専用からReact Nativeでモバイルをサポートするように分離し、その後、カスタマイズ可能なreact-reconcilerコアを介してWebGL(react-three-fiber)やCLI(ink)など他のプラットフォームにも対応可能になりました。内部は新しい「Fiber」アーキテクチャに完全に書き直され、さらなるアーキテクチャの変更が可能になりました。2018年のフックのリリースにより、関数コンポーネントはstateと副作用を持つ能力を得ました。
長年、ReactはUIに特化した最小限のレンダリングライブラリとして自らを位置づけていました(「MVCのV」、「ユーザーインタフェースを構築するためのJSライブラリ」)。AngularやEmberのような他のフレームワークは完全に「全部入り(batteries included)」で、アプリの構築方法や構造について強い意見を持っていましたが、Reactチームはそれら全てをコミュニティに委ねていました。これは、良くも悪くもエコシステムの大爆発につながりました。考えられるあらゆるライブラリカテゴリで、重複する問題を解決する何十もの競合ツールが存在しました。状態管理(Redux、Mobx、Zustand...)、CSSとスタイル(Styled-Components、Emotion、CSS Modules...)、データフェッチ(React Query、Apollo、SWR、RTK Query...)、ビルドツール(Babel、Webpack、ESBuild、Vite、Parcel...)、その他数百です。
Reactユーザーは常に、プロジェクトを開始する際に、アプリのさまざまなユースケースを解決するための一連のライブラリを選び出す必要がありました。さらに、Reactは多くの方法で使用できました。シングルページアプリ(SPA)でクライアントサイドで全ての要素をレンダリングする、サーバーレンダリングされたページに複数のサブツリーをアタッチする、マルチページアプリ(MPA)の一部としてサーバー上で使用するなど、多岐にわたります。エコシステムのオプションの柔軟性と多様性は、強みであると同時に弱みでもありました。プロジェクトに必要なツールの正確な組み合わせを選ぶことができる一方で、ツールの組み合わせを選ばなければならないのです。それは決定疲れ、プロジェクトのコードベースのばらつき、そして一般的に使用されるツールの絶え間ない変化につながります。
全体として、ReactライブラリとReactチームの両方が意図的に意見を持たない(unopinionated)姿勢を保っていました。彼らはエコシステム内の特定のツールをえこひいきしたくなく、彼らの時間と注意はReact自体の構築に集中しており、Reactのスコープをある程度狭いものと見なしていました。
そのエコシステムの多様性は柔軟性をもたらしましたが、同時に複雑さも生み出しました。これは特にビルドツールで顕著でした。初期のReactチュートリアルでは、最初のReactコンポーネントを書く前に、「WebpackとBabelの設定方法」を説明するために何ページも費やすことがよくありました。このためReactチームは、Create React App(CRA)と呼ばれるパッケージ化済みのビルドツール設定を構築することになりました。CRAは、テンプレートから新しいReactプロジェクトを生成できるCLIツールであり、非常に複雑でカスタマイズされたWebpack + Babel設定で構築されていました。これは、単一のコマンドで新しいプロジェクトを簡単に始められるように設計されていました。その設定は、複雑さを隠すためにブラックボックスとしてカプセル化されていました。
Reactにはデータフェッチの組み込みメソッドがなかったため、データをフェッチしてキャッシュするためにサードパーティのライブラリを使用するのが標準でした。Reactには早くからサーバーレンダリング(SSR)機能があり、ReactコンポーネントツリーをHTML文字列やストリームとしてレンダリングするメソッドがありましたが、これらはサーバーハンドラで手動で使用する必要がありました。時が経つにつれて、他のパッケージ済みのReactビルドシステムや「フレームワーク」が人気を博しました。Next.jsもWebpackをラップしましたが、ファイルシステムベースのルーティング規約による組み込みのサーバーレンダリングやページベースのデータフェッチなど、より多くの機能を追加しました。GatsbyはGraphQLベースのデータソースからサイトを生成しました。後に、Remixはサーバーの「データローダー」を追加し、よりHTML/プラットフォームベースの使用規約を推進しました。
2020年後半、Reactチームは「React Server Components」のプロトタイプを発表しました。これは、非同期Reactコンポーネントがサーバー上で実行されてデータをフェッチし、その後子コンポーネントをレンダリングして子とデータをクライアントで実行されているReactに渡すことを可能にするアーキテクチャ的アプローチでした。これはデータフェッチに対するReactらしい解決策として意図されており、Reactの当初の「クライアント上のビューだけ」という歴史的な売り文句からの大きな転換を示しました。RSCの開発中に、Reactコアチームのメンバーの一部がMetaを去り、Next.jsの開発元であるVercelに参加しました。彼らは初期のRSC実装の構築を続け、Next開発チームと協力して新しい「App Router」でNextを再設計しました。これはRSCの最初の本番実装でした。
Reactチームはまた、2020年から2023年にかけてReactのドキュメントサイトをゼロから完全に書き直しました。react.devにある新しいReactドキュメントには、Reactのコンセプトを段階的に解説する素晴らしいチュートリアルがあり、実行可能なサンドボックス内に多数のページ内サンプルが含まれているほか、APIリファレンスページも大幅に改善されています。
新しいドキュメントが公開されたとき、ReactチームはReactの推奨される使用方法を大きく転換しました。以前は、古いReactドキュメントは、学習中またはクライアントサイドのSPAを構築している場合にはCRAから始めることを推奨し、SSRや静的サイトが必要な場合にはNextやGatsbyのような他のいくつかのフレームワークを指し示していました。新しいドキュメントで、Reactチームはアプローチを変更し、「Reactアプリを書くためにはフレームワークを使うべきだ - それらにはルーティング、データフェッチ、ビルド機能が組み込まれている」と明確かつ強く推奨し始めました。これはRSCを構築する作業にも関連していました。この一環として、「新しいReactプロジェクトを始める」ページでは、フレームワークなしでReactを使用することに対して明確に警告していました。Nextはそのドキュメントページで目立つように記載されていました - 「フレームワーク」リストの最初に(Pagesルーターについて)順序付けられ、さらに下で唯一利用可能なRSC実装として言及されていました。Vercelで働くReactチームのメンバーは、「来るべきNext.jsのリリースを『本当の』React 18のリリースだと考えている」と述べたと引用されています。
これは、Create React Appが2022年頃に事実上非推奨になったことと関連していました。それ以前からしばらくメンテナンスされていませんでした。「CRAを非推奨としてマークし、Viteを推奨する」というPRが提出されたとき、Dan AbramovはCRAが作成された理由、CRAの問題点、フレームワークの台頭、そしてReactのビジョンの転換について詳細なコメントを書きました。これに応えて、Reactコミュニティは一斉にCRAから移行し、ドキュメントもそれを推奨するのをやめましたが、公式に「非推奨」とマークするための措置は何も取られませんでした。
Reactとそのオーナーとの関係
今日、Reactの開発作業は2つの企業によって後援され、所有されています。Meta(旧Facebook)とVercelです。
Facebook / Meta
当初から、ReactはFacebook/Metaが所有するプロジェクトでした。コードはオープンソース化され、誰でもPRを提出できましたが、本質的に開発作業は全てMetaのReactチームによって行われていました。
これはReactの開発方法に大きな影響を与えました。Reactコアチームの会議は通常内部で行われ、ロードマップも同様でした。Reactチームはしばしば問題領域に対して半ダースほどのアイデアをプロトタイプし、それをMetaのアプリチームに試してもらって検証しました。新しいReact機能が発表される頃には、それは多くの内部イテレーションを経て、実際の使用で検証されていました。同時に、ReactチームはMetaのアプリチームのバグ修正やその他のサポートにも責任を負ってきました。
それにもかかわらず、Reactチームはライブラリの開発方法においてかなり自由な裁量を持ってきました。ReactはFacebook内部でFacebookのために作られましたが、Reactチーム自身がライブラリの動作方法に関するロードマップと長期ビジョンを決定してきました。ほとんどの場合、Reactの実際の開発プロセスとロードマップは、Facebook/Meta内部の他の影響力によってではなく、彼ら自身によって推進されてきました。とはいえ、彼らは自分たちの業績とプロジェクトがMetaにどのように利益をもたらすかを正当化する必要もあります。
Meta自身のReactの使用は広範であり、コミュニティの使用方法とは異なります。Metaは独自の巨大なサーバーインフラを持っており、データフェッチ、ルーティング、セキュリティなどのための標準的な技術を含んでいます。MetaはGraphQLプロトコル、およびRelay GraphQLクライアントレイヤーを発明し、それらをReactコードで頻繁に使用しています。これは、MetaのReact使用が、ルーティング、状態管理、スタイリング、またはコミュニティの他の部分で一般的な他の問題に対して、サードパーティのライブラリをほとんど必要としないことを意味します。
Vercel, Next, and React
Vercelは主にWebアプリのホスティングプラットフォームです。彼らは主に、より多くの人々が彼らのプラットフォームでアプリをホストすることで収益を上げ、より簡単に使用できるという利便性をもたらすことで課金を促しています。彼らはNext.jsフレームワークの構築(および他のフレームワークのサポート)に膨大なエンジニアリング時間を費やし、Vercelインフラ上でNextアプリを簡単にセットアップしてデプロイできるようにしています。
VercelのCEOであるGuillermo Rauchは、Reactとその能力の長年の信奉者であり、それは彼の2015年のブログ投稿Pure UIがReactのレンダリングモデルの力について語っていることからも示されています。
2021年後半、ReactチームのリードであったSebastian MarkbageがMetaを去り、Vercelに参加しました。これは、フルタイムのReactコアチームメンバーがMeta以外のどこかで働く初めての事例でした。後に、コアチームメンバーのAndrew Clarkと元React組織リードのTom Occhinoが彼に加わりました。ReactチームはすでにReact内部でRSC機能に関する重要なプロトタイピングを行っており、Next.jsのApp Routerを設計していました。そしてVercelは追加のエンジニアをReactのコアとサーバーレンダリング機能に貢献させ始めました。
今日、ReactチームはMetaとVercelの間で分かれています(大多数はまだMetaにいます)、加えて外部に数人のチームメンバーまたは継続的なコントリビューターがいます。
Reactの利用パターン
標準的なReactのアーキテクチャ
React(特にReactDOM)ライブラリ自体は、ページ内でどのように使用されるかを気にしません。ほぼ空のHTMLプレースホルダーを提供し、クライアントサイドでページ全体のコンテンツを生成するReactツリーをレンダリングして、シングルページアプリ(「SPA」)として機能させることができます。サーバーが各リクエストに動的に応答するサーバーレンダリング(「SSR」)や、ビルド時に静的なHTMLページを事前に生成する静的サイトジェネレーション(「SSG」)にReactを使用することもできます。任意の言語やフレームワーク(Python + Django、Ruby + Rails、PHP + WordPress、.NETなど)を使用して静的またはサーバーレンダリングされたHTMLページを提供し、ページ全体にReactの断片を散りばめてインタラクティビティを追加することもできます。
とはいえ、2015年までにはReactはクライアントサイドのSPAアーキテクチャで最も一般的に使用されるようになっていました。何事にもトレードオフがあるように、これらにも長所と短所がありました。ページコンテンツの生成が容易になり(全てReactコンポーネント)、ユーザーのインタラクションが高速化し(ページ全体のリフレッシュの代わりにクリックやルート変更で別のコンポーネントを表示)、よりリッチなアプリ体験が可能になりました。バックエンドが何であれ(JS、Java、PHP、.NET、Python)、JSON APIを公開してデータをフェッチするだけでした。しかし、最初のページのバンドルをロードするのが遅く、クライアントサイドのルーティングがネイティブのブラウザの動作とは異なる不自然なインタラクションにつながる可能性もありました。
これらのクライアントでのデータフェッチは、当初はかなり手動であり、副作用における慎重なロジックを必要としました(例えば、コンポーネントが最初にレンダリングされたときにデータをリクエストするためにcomponentDidMountでフェッチをトリガーするなど)。これはしばしば、フェッチとキャッシングを処理するためにReduxベースのロジックで行われましたが、そのコードは通常、ボイラープレートと複雑さに満ちていました。後に、React Query、Apollo、SWR、RTK Queryのような専用のデータフェッチライブラリがクライアントでのデータフェッチを大幅に簡素化し、専用のuseQueryフックと事前構築されたキャッシングメカニズムを提供しました。
NextやRemixのようなフレームワークは、Reactをサーバーレンダリングするための標準化されたアプローチを提供し、組み込みのファイルシステムルーティング規約を備えていました。しかし、サーバーベースのデータフェッチに関する規約はありませんでした。Nextは、コンポーネントと並行してフェッチするための非同期関数を指定するgetServerSidePropsメカニズムを発明しました。Remixは後に同様のアーキテクチャで「ローダー」を発明しました。どちらもReactの思想に合っていない感じがしました。
これは、Reactエコシステムにおける一般的な考え方の転換につながりました。ページの読み込み体験を改善し、ページに必要なJSの量を最小限に抑えるために、SSRベースのアーキテクチャへの推進が強まっています。また、クライアントサイドでデータフェッチライブラリを使用する必要性をなくす動きもあります。Reactチームは、ページの読み込みパフォーマンスを改善するためにデータフェッチにおける「ウォーターフォール」に声高に反対しており、React RouterやTanStack Routerのようなクライアントサイドのルーターでさえ、コンポーネントツリーの奥深くでフェッチをトリガーするのではなく、ルート/ページレベルでデータをプリフェッチする方法を提供しています。
Reactビルドツールの利用状況
いくつかの主要なReact関連のビルドツールとフレームワークのダウンロード統計を見て、エコシステムにおける使用規模の経時的な変化と現状を把握する価値があります。 大まかに言うと、今日の主要な選択肢は、マインドシェアおよび/またはダウンロード数の観点から以下の通りです。
- Next.js (SSR / SSG / RSC / SPA)
- Remix / React-Router v7 (SSR / SSG / SPA)
- Vite (SPA)
- Create React App (SPA)
また、Vite自体はVueエコシステムから始まったものの、多くの異なるクライアントサイドフレームワークをサポートする標準化された広く使用されるビルドツールになったことにも注目する価値があります。また、Reactサポート用のプラグインを含むプラグインエコシステムもあり、さまざまなフレームワークのビルドツールとして選ばれるようになっています。これにはRemix / React-Routerも含まれており、最近、内部でESBuildを使用するのをやめ、SSRとSSGのサポートを有効にするためのViteプラグインを提供するように切り替えました。
以下は、過去数年間のこれらのツールのNPMダウンロード数のグラフです。ReactDOMをスケールとして示しています。
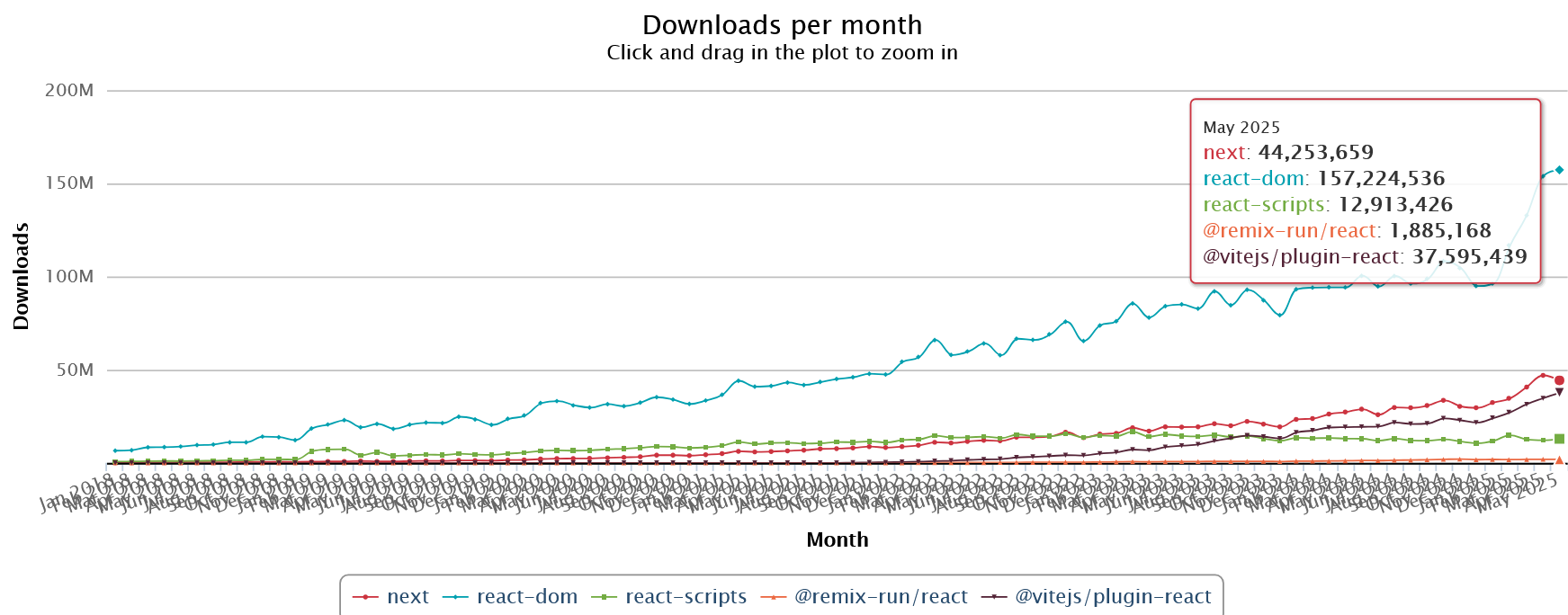
最近まで、ReactドキュメントはGatsbyをWeb向けの推奨フレームワークとして、ExpoをReact Native向けの唯一の推奨フレームワークとしてリストアップしていました。GatsbyはNetlifyに買収された後、事実上その役目を終えました。一方、AstroはReactを含む多くのフレームワークをサポートする、より汎用的な静的サイト指向のツールです。比較のために彼らのダウンロード統計を以下に示します。
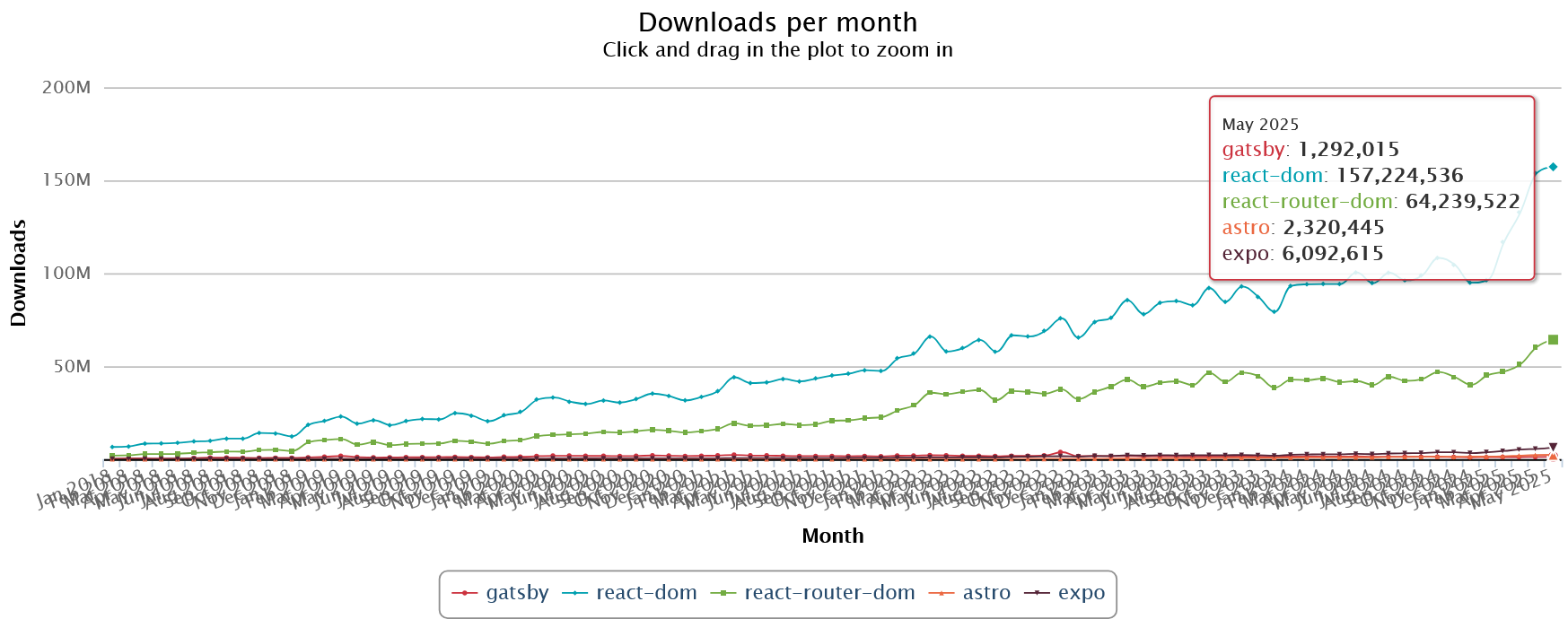
これらの統計からのいくつかの要点:
-
Next.jsが最も広く使用されている
-
ViteのReactプラグインは着実に成長しており、現在では2番目に広く使用されている
-
React関連のビルドツールである
-
CRAの使用は2023年半ばにピークに達し、それ以降減少しているが、依然としてかなりの使用量がある
-
Remixは現時点で口コミでの評価は高いものの、規模は比較的小さめです。React Routerは非常に広く使われていますが、「フレームワークモード」に対応した新しいバージョンは、まだそれほど普及していません。
-
GatsbyはNext、CRA、Viteほどの勢いはなく、最近Astroに追い越された
-
AstroはReact固有ではないが、Remixとほぼ同じダウンロード数がある
-
ViteとCRAを合わせるとNextの使用量に匹敵し、Reactエコシステムには依然としてプレーンなSPAプロジェクトに対する強い需要があることを示している
React Server Componentsの内側
React Server Componentの開発とVercel
Reactチームは、Metaのインフラストラクチャからのサーバーベースのデータフェッチや、JSバンドルの自動分割とコードの遅延読み込みの経験がありました。しかし、以前のReactの機能開発とは異なり、Meta内部でRSCをイテレーションして出荷するための選択肢は限られていました。Metaの既存のサーバーインフラと技術は、コミュニティの他の人々が実際に使用して恩恵を受けられるような方法でRSCを完全に設計することを困難にしていました。
注目すべきは、React Server Componentsは、将来Reactアプリを記述する方法に関するReactチームのビジョンであったことです。私の知る限り、これはMetaやVercelが考案したり、Reactチームに構築を強要したりしたものではありません。
長年にわたり、「Reactの開発は全てMetaの従業員によって行われている」という断続的な議論や不満があり、「『React財団』のようなものや、Metaの外部の人々が直接Reactに取り組んでいればいいのに」というコメントが時折ありました。関係する実際の議論は知りませんが、外部からの私の理解では、ReactチームがVercelにアプローチし、RSCのビジョンを提案し、VercelがRSCが開発される新しい実験場となることに同意した、ということです。これにより、Sebastian Markbage(そして後にAndrew Clark)がMetaからVercelに移り、NextチームはRSCの最初の実用的な実装としてNext App Routerを設計・構築するために膨大な時間、資金、エンジニアリングの労力を費やしました。 Dan Abramovが説明したように:
none
Vercelチームは、Reactチームが望んでいたことを実装するために、何人ものエンジニアを何年も稼働させてきました。また、Reactチームから技術的な方向性を直接受け入れたことも事実です。Next.jsは多かれ少なかれゼロから書き直されました。 現在Next.jsを設計している人物は、Reactフックを発明した人物です。ですから、どちらかと言えば、ReactチームがNext.jsの方向性を「引き継いだ」ケースであり、「ひいきにした」わけではありません。
そのプロセスに他のフレームワークや企業を関与させようとする努力はありました。ShopifyのHydrogenフレームワークはRSCの非常に初期のテストとフィードバックを行いましたが、最終的に彼らにとっては合わないと結論付けました。Remixチームは何度か関与を打診されましたが、当初は独自のアプローチに集中することを選択しました。
その結果、Nextは最初の(そして事実上今でも唯一の)「本番環境対応」のRSC実装となりました。今日、他のいくつかのフレームワーク(Parcel、React Router、Wakuを含む)がRSC統合に取り組んでいますが、NextのApp Routerが現在RSCを使用するための唯一の広範な選択肢です。
RSC、フレームワーク、バンドラ
「なぜRSCはバンドラやフレームワークを必要とするのですか?なぜReactに組み込むだけではだめなのですか?」といった質問をよく目にします。
Reactの既存のサーバーレンダリングメソッド、例えばrenderToStringやrenderToPipeableStreamは、Expressのルートハンドラなど、どこでも呼び出すことができました。しかし、アーキテクチャ的にRSCはずっと複雑です。RSCの機能は、'use client'と'use server'ディレクティブを探すためにコードを解析し、そのコードを変換してRSCのコア機能にクライアントコンポーネントとサーバー関数を登録するための適切な呼び出しを挿入する必要があります。これにはバンドラとの緊密な統合が必要で、それによってサーバーとクライアントの両方の全てのモジュールグラフを正しく決定し、適切にコンパイルすることができます。
さらに、Reactコアが実際のRSC機能を実装し、シリアライズされたコンポーネントとデータをクライアントとサーバー間で送信するためのプリミティブを提供しますが、それらのプリミティブを実際に呼び出し、適切な場所で使用するのはフレームワーク次第です。これは主にルーターとの統合に関わることで、クライアントアプリが適切な遅延読み込みされたクライアントコンポーネントを受け取り、アクションとデータを含む適切なエンドポイントを呼び出すようにするためです。
これはまた、各フレームワークのRSCの使用と実装が異なることを意味します。NextはApp Routerでレイアウトとルーティングを処理するために非常に具体的な実装決定を行いました。Waku、Parcel、React Routerのような他のフレームワークやビルドツールは、すでにいくつかの非常に異なる設計決定を行っています。
全体として、RSCは珍しいハイブリッド機能です。主要な機能はReactコアパッケージに直接組み込まれていますが、その機能はバンドラ/ルーター/フレームワークの何らかの組み合わせに統合されるまで使用できません。
コミュニティの懸念と混乱
これら全ての歴史と文脈を念頭に置いて、頻繁に繰り返されるいくつかの懸念事項(混乱しているか、FUDであるか、あるいは完全な陰謀論であるか)に答えていきましょう(そして、うまくいけば明確にし、払拭していきたいです)。
懸念:Vercel、Next、そしてReact
「VercelがReactの開発を主導しており、その目的はサイトをホスティングしてより多くの収益を上げることだ」という見解が、今や非常に一般的になっています。一例として、これは今年の初めにあったRedditのスレッドで最も多く支持されたコメントです:
none
"Vercelは事実上Reactを乗っ取り、ユーザーをNextJSに誘導し、Vercelでデプロイさせることで、Vercelの株主をより豊かにすることに主な関心を持っている。" https://www.reddit.com/r/react/comments/1iarj85/xbluesky_react_recently_feels_biased_against_vite/m9cb51h/
これは、他のいくつかの関連する懸念点と結びついています:
- NextはReactのドキュメントで最初に推奨されており、Next App Routerも「Reactチームのフルスタックアーキテクチャビジョンを構成する機能は何か?」の下で主な例として言及されている
- Nextは依然としてRSCの唯一の本番実装である
- Reactチームのメンバーは「このNextのリリースが本当のReact 18だ」と述べたと引用されている
人々がこの結論に至る理由は理解できます。VercelはReactチームのメンバーを何人か雇用し、彼らはReact自体とNextの両方に取り組んでいます。時系列的には、これは自然にRSCの開発と、ユーザーにフレームワークの使用を促すという新しいシフトと一致しました...そして見てください、その「明白な」フレームワークはまさにNextです!一方、VercelはNextをVercel上で簡単にデプロイしてホストするために、莫大な資金と労力を投入してきました。Nextを他の場所でホストすることは可能ですが、機能しなかったり、設定が難しかったりする機能が常にありました。
とはいえ、私が見てきた全てのことから、この見方は一般的に因果関係を逆転させており、ほとんどがFUDです。はい、もちろんVercelは最終的に自分たちに利益をもたらすと考える取り組みに投資してきました。しかし、前述の通り、SebとAndrewがVercelに移り、RSCの開発プロセスについて私が目にした全ての記述は、この一連の変更を推進したのはReactチームであったことを示しています。
RSCはReactチームのビジョンでした。Metaの内部では効果的にプロトタイプを作成してテストすることができなかったため、初めて、開発に投資し、設計を繰り返すための環境を提供する他のスポンサーが必要になりました。具体的な経緯は分かりませんが、私の理解では、ReactチームがVercelを説得してReactチームのビジョンに賛同させ、そしてそのビジョンに合致するApp Routerのアプローチを設計するためにNextを再設計することを彼らに任せた、ということです。
確かに、「Nextはこれを必要としている」といった類のReactへの変更はいくらかありました。あるNextConfsの前夜、重要なNextバージョンの発表があった際(おそらく13.4での安定版App Router?)、ReactリポジトリでいくつかのPRがマージされるのを見た記憶があります。しかし、その作業を行っていたのは依然としてReactチームのメンバーでした。
現時点で、Reactチームは分裂しています。大多数はまだMetaにいますが、Vercelのメンバーはコア実装の鍵を握っています。「Reactチームのミーティングは相変わらずだ」と読んだことがありますが、そのように分裂することから何らかの追加の複雑さが生じていても驚きません。
とはいえ、「VercelがReactを乗っ取った」というのは間違っており、「Reactコアの一部がVercelに移り、Vercelを説得してReactのビジョンに同調させた」という方が近いと私は考えています。また、「Vercel」がReactの設計を主導している、あるいはフレームワークとRSCへの重点化がVercelの収益を上げるという特定の意図を持っているという証拠も見当たりません。
懸念:ReactはNextでしか動かない
「Reactは今やNextでしか動かない」と、真剣に、あるいは不思議そうに言う人々のコメントをオンラインでいくつか見てきました。
これは簡単に反論できます。「新しいReactプロジェクトを始める」ページを見るだけでも、Nextではない他のフレームワークや、やや悪名高い「フレームワークなしでReactを使えますか?」セクションが表示されています。
明らかに、これはReactの仕組みに関する完全な誤解です。
しかし、これは同時に、React、「フレームワークを使え」というメッセージ、そしてVercelの影響力をめぐるメッセージングがいかに混乱しているかを物語っています。
これに非常に関連した「NextとReact、どちらを使うべきか?」という質問も付け加えておきます。これも頻繁に目にします。文字通りに読めば、「Next」と「React」は別物だということです。これも明らかに間違いです。NextはReactライブラリを使用するフレームワークです。それはスーパーセットであり、競合相手ではありません。ほとんどの人が意図しているのは、「Nextを使うべきか、それともCRAやViteのようなクライアントサイドSPAを使うべきか?」ということだと思いますが、それを明確に述べる語彙を持っていないのです。
これもまた、ここでの境界線についてどれほどの混乱があるかを示しています。
懸念:Reactがいつかクライアントアプリで動かなくなるかもしれない
この懸念もよく目にします。懸念は、「もしReactチームがサーバーを必要とする機能にこれほどの重点と労力を注いでいるなら、それはいつかクライアントサイドの機能が変わったりなくなったりする可能性があるということか?」というものです。
人々がこの恐怖を抱く理由は理解できます。それは、Reactチームからのトーンと重点の大きな変化、そして彼らがサーバーサイドの機能に注いできた労力の量によって引き起こされています。
しかし、これが決して起こりえないことも明らかです。Reactのクライアントレンダリング機能は、決してなくなりません! Meta自身が何百万行もの既存のReactコードを持っているという事実だけでも、それが分かります。その上、Reactチームは常にコードレベルの後方互換性に関して非常に優れてきました - 破壊的変更を記述し、非推奨の機能を最終的に削除するまで何年も保持し、移行ガイドやcodemodを提供してきました。
また、React 19と19.1の機能の多くはクライアント専用であることにも注目する価値があります。どちらかと言えば、コミュニティはサーバーサイドの機能に注がれた労力を過大評価し、クライアントサイドの機能に注がれた労力を見逃してきました。
懸念:なぜReactはフレームワークを推すのか
そして、次の議論につながります。なぜReactチームは、「そうしないと間違いだ」と言ってまで、全てのReactユーザーにフレームワークを使わせることにそれほど固執するのでしょうか?
これは、私がより多くの共感と同感を持つ懸念です。私は彼らが「Nextを使わせてVercelでホスティングさせよう」という目標で「フレームワークを使え」と言っているのではないと述べましたが、ではその理由は何なのでしょうか?
Reactチームのフレームワークに対する見解
Andrew Clarkの2023年1月のツイートは、その意図をかなり明確に述べています。
none
Reactを使うなら、Reactフレームワークを使うべきだ。既存のアプリがフレームワークを使っていなければ、段階的に移行すべきだ。新しいReactプロジェクトを作成するなら、最初からフレームワークを使うべきだ。
あなたが選ぶReactフレームワークには、データフェッチ、ルーティング、サーバーレンダリングのための組み込みソリューションがあるべきだ。フレームワークはこれらを独立した懸念として扱わない — 深く統合されたソリューションを提供し、使いやすく、箱から出してすぐに優れたパフォーマンスが得られる。
フレームワークを放棄することを選ぶなら、あなたが本当に選んでいるのは、自分専用のフレームワークを構築することであり、それはおそらく既製品よりもはるかに悪いものになるだろう。たとえあなたの特注フレームワークが今日の代替品より優れていると思っても、一年後もそうだろうか?
最新技術に追いつくには多くの時間とエネルギーがかかる。あなたはフレームワークのメンテナーになる準備ができているか?それとも、あなたの時間をもっと有効に使うべきことがあるのではないか?
それ以来変わった主なことは、フレームワークが本当に、本当に良くなったことだ。かつてはプレーンなReact + Webpackが、オールインワンのフレームワークと同等かそれ以上だった。私の意見では、もはやそうではない。
問題は、フレームワークを使わずにReactアプリを構築することが可能かどうかではない。その選択肢は常に存在する。問題は、あなたの自家製のセットアップが、機能、パフォーマンス、DXにおいて業界のリーダーと競争できるかどうかだ。そのハードルは常に上がっている。
同様に、Dan AbramovがCRAを非推奨と見なす理由を説明した際にも:
none
Create React Appは問題の一側面しか解決しなかった。それは(当時としては!)良い開発体験を提供したが、Webの強みを活かして良いユーザー体験を得るための十分な構造を課さなかった。これらの問題を自分で解決しようとすることもできたが、そのためには「eject」してセットアップを大幅にカスタマイズする必要があり、それではCreate React Appの趣旨が損なわれてしまう。本当に効率的なReactのセットアップは全てカスタムで、異なり、Create React Appでは達成不可能だった。
これらのユーザー体験の問題はCreate React Appに特有のものではない。Reactに特有でさえない。例えば、Viteのホームページテンプレートから作成されたPreact、Vue、Lit、Svelteのアプリは全て同じ問題に苦しんでいる。これらの問題は、静的サイト生成(SSG)やサーバーサイドレンダリング(SSR)のない、純粋にクライアントサイドのアプリに固有のものである。
Reactでアプリ全体を構築する場合、SSG/SSRを使用できることは重要だ。Create React Appにそれらのサポートがないことは 目に余る欠点だ。しかし、Create React Appが遅れているのはそれだけではない。
React自体はただのライブラリだ。ルーティングやデータフェッチの方法を規定しない。Create React Appも同様だ。残念ながら、これはReact単体でも、元々設計されたCreate React Appでも、これらの問題を解決できないことを意味する。ご覧の通り、これは単一の欠落した機能に関する話ではない。これらの機能 — サーバーサイドレンダリングと静的生成、データフェッチ、バンドリング、そしてルーティング — は相互に関連している。
時代は変わった。今では、これらの機能を持たないことに固定されるソリューションを推奨することはますます困難になっている。たとえすぐに全てを使わなくても、必要なときには利用可能であるべきだ。それらを利用するために別のテンプレートに移行し、全てのコードを再構築する必要はないはずだ。同様に、全てのデータフェッチやコード分割がルートベースである必要はない。しかし、それはほとんどのReactアプリで利用可能であるべき良いデフォルトだ。
私はReactチームとの会話で、Reactアプリの読み込み時間が遅く、全体的なパフォーマンスが悪いという外部からの多くの不満を聞いていると直接言われたこともあります。ですから、フレームワークの重視はそれに対する直接的な反応であり、デフォルトでより多くのアプリがまともなパフォーマンスを持つようにするという目標があります。
それに基づくと、Reactチームのスタンスは次のように要約できます:
- フレームワークには、データフェッチ、ルーティング、サーバーレンダリングのための組み込みのアプローチがあり、それらは連携して動作するように設計されている
- それらは全て箱から出してすぐに提供されるため、部品を選んで組み合わせる(うまく連携しないかもしれない)時間を費やす必要がない
- フレームワークは、ビルド設定やより良いデータフェッチパターンにより、デフォルトでより良いパフォーマンスにつながる
- さらに、React Server Componentsは、正しく動作するためにフレームワークへの統合が必要である
これらの懸念は、Reactチームが今日Reactがどのように使用されるべきだと感じているかにとって極めて重要である
言い換えれば、それはイデオロギー的なスタンス、「これはあなたの時間と労力を節約する」という信念、そして「ほとんどのReactアプリは同様のパターンに従い、同様のソリューションを必要とする」という信念の組み合わせなのです。
フレームワーク、SSR、そしてSPA
また、「サーバーレンダリング」という特定の言及に注意してください。一般的に、Reactチームとエコシステムの他の主要メンバー(Remix / React RouterのRyan FlorenceとMichael Jacksonなど)の両方が、クライアントでのデータフェッチの「ウォーターフォール」(例えば、<List>がアイテムのセットをフェッチし、その子をレンダリングし、<ListItem>がマウント後に独自のフェッチを行うなど)を避けるためにサーバーレンダリングを行う必要性を強く強調してきました。NextやRemixのようなフレームワークは、箱から出してすぐにサーバーレンダリングをサポートするように特別に設計されています。
「より速い初期ページロード」、「クライアントのJSを少なくする」、「ウォーターフォールを避ける」といったSSRの正当化は、全て理にかなっています。私も、クライアントサイドのSPAがおそらく使われるべきでなかった多くの場所で使用されてきたこと(Reduxと本当に同じです)、そして、たとえすぐに全ての機能が必要でなくてもフレームワークから始めることが理にかなっていること、そうすれば後でそれらの機能が必要になったときに利用できるということに同意します。
NextとRemixには、静的なJS/HTMLアセットを出力するだけの「SPA / エクスポート」モードがあるので、それらを使ってNodeサーバープロセスを必要としない純粋なクライアントサイドアプリを作成することは可能です。しかし、それらはデフォルトではなく、コミュニティのほとんどがそれがオプションであることすら知らないだろうと私は推測します。
フレームワーク推奨にはニュアンスが欠けている
これら全てを踏まえて、私はReactチームがなぜデフォルトとしてフレームワークを推奨することに決めたのかを理解しています。それは合理的な意見であり、平均的なReactアプリを改善するための正当な意図だと思います。
しかし、私はまた、その「推奨」が、エコシステム全体でReactが実際に使用されている多様な方法を充分に評価しない、過度に広範な処方箋に変わってしまったと感じています。
フルスタックのReactフレームワークを使用する多くの正当な理由がありますが、使用しない理由もたくさんあります:
- フレームワークは多くの追加機能を追加しますが、それは学習する複雑さも追加し、Reactの使い方を把握しようとしている初心者にはあまり適していません。
- 追加された複雑さは、誤ってサーバーコンポーネントでContextやフックを使用してしまう(エラーをスローする)など、混乱につながる罠にもなり得ます。
- 多くの企業はJSバックエンドを運用していないかもしれず、それに対する規則や制限さえあるかもしれません。
- サーバー機能を持つフレームワークは実行に特定のホスティングを必要としますが、純粋なSPAは静的なHTMLとJSを提供する場所ならどこでも(Github PagesやAmazon S3を含む)簡単にホストできます。
- ライブラリを選び出す必要性は、しばしばReactユーザーにとって不満の源でしたが、それはプロジェクトを特定のニーズに合わせてカスタマイズすることを可能にします。意見の強いフレームワークは、それらの決定のほとんどを行う必要性をなくしますが、後で挙動をカスタマイズする能力を制限することもあります。
- 「サーバーレンダリング」への重点化は、一部の種類のアプリには明らかに役立ちますが、全てではありません - クライアントサイドだけで生きる必要があるアプリもたくさんあります。
ドキュメントの推奨事項は重要
Reactチームは「ドキュメントは初心者を対象としている」と述べており、そのため推奨されるツールやオプションのリストを混乱を避けるためにかなりシンプルに保ちたいと考えています。これは非常に合理的なスタンスです。
彼らはまた、「Viteを使うべきだと知っているほど経験豊富な人は、どのみちドキュメントにそれがリストされているのを見る必要はない」(意訳)とも述べています。それは技術的には真実です。
しかし、ドキュメントを読むのは初心者だけではありませんし、ドキュメントが推奨するものは公式の承認の印としての影響力を持ちます。それが、Reactチームが歴史的に特定のライブラリや技術を推奨することを避けてきた大きな理由の一部です。
フレームワーク/ビルドツールの使用統計を振り返ると、今日、Vite ReactとCRAの使用量はNextを上回っており、SPAの使用が依然としてReactエコシステムの少なくとも半分を占めていることは明らかです。ドキュメントの推奨事項はその使用状況を反映すべきです。
エコシステムの軽視
新しいReactドキュメントが公開されたとき、フレームワーク以外のオプションについての唯一の言及は、「フレームワークなしでReactを使えますか?」と題された展開可能な詳細セクションで、「はい、しかし私たちはそれが良い考えだとは思いません」と述べるいくつかの段落がありました。
そして、そのセクションの最後で語られていたのがこちらの声明でした:
none
それでも納得できない場合、またはあなたのアプリがこれらのフレームワークではうまく対応できない珍しい制約を持っている場合、そして独自のカスタムセットアップを構築したい場合は、私たちはあなたを止めることはできません—どうぞ!npmからreactとreact-domを入手し、ViteやParcelのようなバンドラでカスタムビルドプロセスを設定し、ルーティング、静的生成またはサーバーサイドレンダリングなどのために必要に応じて他のツールを追加してください。
つまり、新しいセットアップページはCreate React Appをリストアップしなかっただけでなく、最も近い同等のツール(Vite)はページの外部セクションで意味のあるオプションとしてさえリストされていませんでした。代わりに、それはこの展開可能な説明の最後に単なる言及として記されていました。
また、「珍しい制約」というフレーズはここでは非常に不適切だと言いたいです。SPAはReactコミュニティで当初から標準的なアーキテクチャでした。CRAとViteは一般的に使用されています。SPAを構築することが、どうして突然「珍しい制約」になるのでしょうか?アーキテクチャ的な理由からビジネス上の理由、学習の単純さまで、SPAを望む理由はたくさんあります。それらは「珍しい」ものではありません - それらは全て一般的なユースケースです。
そしてそれを超えて...「私たちはあなたを止めることはできません」というフレーズに注目してください。そのフレーズは、多くの人々の目に、コミュニティを軽視する不適切な表現として、そしてReactチームが一夜にしてSPAをサポートされていないアプローチとして格下げしていることのしるしとして映りました。
この例として、2023年半ばのドキュメントにおける「フレームワーク」重視に関する議論からの引用を以下に示します:
none
ある意味で、ReactはAngularJSの瞬間を迎えています。チームはこの不安定で不確実な時期を利用して、代替案を探しています。私たちは確かにそうです。 Reactは素晴らしいです。コミュニティにとって懸念なのは、サーバー&フレームワークへの強い同調というトーンの変化です。今日ある姿にしたサーバーニュートラルな側面が、突然二流に感じられます。(SPAのルーター&ローダーは混乱しており、十分なサービスが提供されていません!) それはReactやViteについてではありません。エコシステムについてです。Reactが伝統的な「非フレームワーク」を「新しい方法」ほど強く奨励しないことに気づくのは辛いです。「フレームワークなしのReact」セクションはドキュメントに隠されており、憂鬱です。 Node以外のバックエンドを持つ企業として、私たちはそれらのドキュメントを、もはやReactの主要な方向性と一致しないというサインと見ています。フレームワークの支持は、チームにスタック全体を再評価させるほどの大きな変化です。Reactは素晴らしいですが、その影響力はアーキテクチャに限界があります。Reactがこの方向に行くことが「間違っている」わけではありません。しかし、非フレームワークのReactの使用が今や二流の懸念事項であると偽ることはできません。それが実行不可能な選択肢になるまで、あとどれくらいでしょうか?それは不快です。だから、私たちはより安全な賭けを探します。Node以外のバックエンドを持つ企業に何を勧めますか? https://x.com/vyrotek/status/1649097699696992256
ドキュメントの推奨事項の修正
Reactチームが最終的に2025年初頭にCRAを非推奨と発表したとき(私がそれを修正し、その非推奨を公式にするように彼らを後押しした後)、最初のドキュメント更新には新しい「独自のフレームワークを構築する」ページが含まれていました。そのコンセプトは、独自のルーターとデータフェッチのアプローチを選ぶことは、「本物の」フレームワークほど良くない特注のフレームワークを寄せ集めることと同等である、というものでした。
ここでのメンタルモデルは理解できますが、これもまた、エコシステムがアプリを構築してきた方法と、人々が独自のオプションを選択する能力の両方をかなり軽視しています。
一例として、Viteの作者であるEvan Youは彼の見解を投稿しました:
none
ReactチームのVite(およびビルドツール全般)に対するためらいは、それが彼らのReactのビジョン(つまり、RSCが推奨されるパラダイムであること)とどのように一致するか、そして彼らが設計通りに統合が機能し、設計のイテレーションに適応できるようにするために、言及されたツールとどれだけの影響力/つながりを持っているか、という点にあるように感じます。...
これがReactチームが考えていることと違うのであれば謝罪しますが、これは私の正直な推測です。なぜなら、Viteが推奨ツールとしてより良く認識されるまでにこれほど時間がかかったことに、私も多くのReactユーザーと同じくらい戸惑っているからです。
私は最終的に、トーンを改善し、プロジェクトセットアップツールの推奨にニュアンスを加え、アプローチを選択する際のアーキテクチャ的なガイダンスを提供するために、セットアップページを刷新するドラフトPRを提出しました。そのPRはクローズされましたが、Reactチームはいくつかのアイデアと言い回しを新しいPRにチェリーピックしました。
最終的に、彼らはかなり合理的な「Reactアプリをゼロから構築する」セットアップページに落ち着きました。それはSPAと独自のツールを選ぶことを有効なアプローチとして認識し、Vite / Parcel / RSPackを推奨ビルドツールとしてリストアップし、いくつかのルーターとデータフェッチライブラリを指し示し、プロジェクトを設定しようとしているユーザーに実際に役立つガイダンスを提供しています。
ドキュメントがその点に達するまでに数年かかったのは残念です:( 新しいドキュメントがリリースされた直後に、Reactチームがコミュニティから推奨された表現の変更のいくつかを適用していれば、混乱と苦悩の多くは避けられたかもしれません。
懸念:サーバーコンポーネントのドキュメントと説明
React Server Componentsに関する大きな問題点と混乱の原因の1つは、公式のドキュメントと情報が散在しており、残念ながら不足していることです。
Reactチームは2020年12月に説明ビデオ付きでRSCを発表し、それに続いてRSCを説明する詳細なRFCドキュメントが公開しました。これらは背景と主な動機を説明する上で、まずまずの内容でした。
しかし、RSCの開発プロセスと、設計上の選択を実装するのはフレームワーク次第であるという事実が相まって、実際のReactドキュメントはRSCを有意義に文書化することはありませんでした。
新しいApp Routerの形でRSCの最初の公式ベータ版がNext 13.0で公開されるまでにほぼ2年かかり、さらに6ヶ月後、2023年5月にNext 13.4が公式にApp Routerを「安定版」であり本番環境対応であると宣言しました。VercelとNextには小規模ながら非常に活発なdevrelチームがあり、Next 13.4のリリースの頃には、当時新しかったApp RouterをカバーするためにNextのドキュメントを大幅に書き直していました(「ベータ版」ドキュメントとして利用可能)。それには、RSCの使用について語るいくつかのドキュメントページが、「データフェッチ」カテゴリの下に含まれていました。また、後には「React Server Componentsを理解する」のような詳細なブログ投稿もありました。これらは、アーキテクチャとコンセプトの非常に役立つ説明を含む、優れたリソースでした。
それにもかかわらず、RSCの機能はReact自体の一部であったにもかかわらず、ReactのドキュメントにはRSCに関する情報が一切ありませんでした。「RSCとは何か」もなく、「RSCをどう使うか」もなく、そして間違いなく「自分のライブラリをRSCと統合するにはどうすればよいか」もありませんでした。Vercelのチームは実際の製品とReactとの重複部分を文書化する良い仕事をしましたが、実際のReactドキュメント自体にRSCに関する情報や説明がないことは人々にとって非常に混乱を招きました(時系列的には、それは数ヶ月前に公式にローンチされたばかりでした)。
ソーシャルメディア上では、個々のReactチームメンバーによる多くの議論があり、質問に答えたり、概念としてのRSCを擁護したり、RSCのセールスポイントを具体化しようとしたりしてきました。しかし、現在、RSCに関する唯一の公式コアドキュメントページはAPIリファレンス:サーバーコンポーネントです。しかしこのページは正直なところ混乱を招くだけで特に役立つようには思えません。それは内容的に間違いなく「APIリファレンス」ではなく、その内容にはRSCを紹介したり、いつ、どのように使用するかを説明したりする実際の文脈がありません - それはランダムなトピックのごちゃまぜです。
RSCのさまざまな側面を説明する優れた外部ブログ投稿がいくつかありました:
- Dan AbramovはRSCのメンタルモデルとそれらが解決する問題を説明する数多くの素晴らしい投稿を書いています。
- Vercelは素晴らしい「React Server Componentsを理解する」紹介ブログ投稿を公開しました。
- Daniel Saewitzは「サーバーコンポーネントは選択肢を与える」を書き、それらがツールボックスへの追加であることを説明しました。
これこそが、Reactのコアドキュメントにあるべき情報です - RSCのコンセプトと、なぜそれらを使いたいかの説明であり、特定のフレームワークがRSCをどのように実装したかとは無関係です。
これに関連して、コミュニティは「RSCはReactの未来である」、「Reactチームは私たちにRSCを常にどこでも使ってほしいと思っている」という考えを持ち帰ってしまいました。実際には、Reactチームのメンバーがソーシャルメディアで「RSCはオプションであり、私たちはただ人々にそれを正しく理解してほしいだけだ」と明言しているのを見てきました。その混乱を考えると、その点を特にドキュメントで指摘することが重要だと思われます。
個人的には、ReactのコアドキュメントにRSCに関するセクション全体が追加されるのを見たいです。例えば、以下のようなページです:
- 「RSC入門」
- メンタルモデル
- ユースケース / RSCを選択するタイミング
- 技術的なデータフロー / アーキテクチャ
- 採用 / 移行
- FAQ
- フレームワーク実装者ガイド
これらのドキュメントページがあっても、全ての疑問がなくなるわけではありません。そもそもドキュメントを読まない人もたくさんいます:) しかし、これらのトピックが公式にカバーされることで可視化され、ソーシャルメディアでこれらの質問が持ち上がるたびに答えるために使用できるリソースとして機能するでしょう。
懸念からの教訓
私は、Reactチームがインターネット上のFUDを払拭するために彼らの時間の全てを費やすのが彼らの仕事だとは思いません。多くの人が意見を持つでしょうし、その多くは異なるか間違っているでしょう。
とはいえ、「フレームワークとサーバーへのこの全ての強調は、Vercelにお金を稼がせるために私たちに強制されている」という一貫した強いテーマがあることは驚くべきことです。それは間違っていますが、人々をその信念に導くのに十分な状況証拠があり、Reactチームの行動と声明はある程度、それを反証するのではなく、その信念を強化してしまいました。残念ながら、現時点ではそれはコミュニティに永久に埋め込まれたミームのようになっており、私たちはそれをなくすことはできないと思います。
また、ユーザーがReactが将来どのように変化したり動作しなくなったりする可能性があるかについて心配したり、想定したりしていることも、本当に懸念すべきことです。特に、それらの懸念が明らかに間違っており、簡単に反証可能である場合はなおさらです。あなたはこれまで通りにReactを使い続けることができ、RSC / サーバーの機能は全て、完全に付加的でオプションです。
インターネットがそういうものである以上、実際のReactブログにそれらの声明を明確に反論するブログ投稿があったとしても、多くの人々の心を変えることはないでしょう。しかし、React組織からのより良いデベロッパーリレーションズ活動 - 懸念を読み、それらが存在することを認め、どこから来ているのかを理解し、それらを明確にして答えようとすることにもっと時間を費やすこと - で、その最悪の事態の一部は避けられたかもしれないと感じます。
「フレームワーク」への推進は本当に善意から出たものだと感じますが、同時にあまりにも広範で、最終的にはエコシステムにおける多様な使用パターンを軽視しているとも思います。はい、ニュアンスを提供するドキュメントを書き、推奨事項を提供するのは難しいですし、初心者を対象とし、エコシステムをより良い方向に導くために物事をシンプルに保とうとすることは理解できます...しかし、メンテナーであることの一部は、コミュニティによってあなたのツールが使用される多様な方法を認識し、サポートすることです。
私たちは最終的に、プロジェクトを自分でセットアップするための有用な指示を持ち、それを有効なアプローチとして認識する、合理的なReactプロジェクトセットアップドキュメントのセットにたどり着きました。その時点に到達するまでに数年かかったこと、そしてReactチームがそのセクションを改善する方法に関するコミュニティからの非常に声高なフィードバックを本質的に無視したことは残念です。ドキュメントは、アプリに適したツールとアーキテクチャを選択する方法に関するアドバイスがもっとあれば、依然として大いに恩恵を受けるでしょう。
同様に、RSCのコンセプトとトレードオフに関する公式のコアドキュメント情報の欠如が混乱を助長してきました。これらのトピックをカバーすることが、人々のRSCに対する理解とそれに伴う言説を大きく改善すると強く感じています。
最後に
この記事が、Reactがどのように、そしてなぜこのように発展してきたのか、Reactの開発プロセスにどのような影響があるのか、Reactチームの主な目標は何か、そして今日のReactの使用パターンはどのような状況にあるのか、といった多くの疑問に答えるものであれば幸いです。
また、Reactチームの動機や特定の方向に推進する理由に関する混乱やFUDの一部を払拭できたことを願っています。人々が技術的な方向性に同意しないこと、あるいはReact Server Componentsやより大きなフレームワークへの移行が必要ないと判断することは問題ありません。しかし、Reactチームの意図はここでも正当で純粋なものです。
広く使われているライブラリを維持し、コミュニティの多様なニーズや使用パターンを満たすことは、本当に難しいことです。私はReactチームが全体として良い仕事をしてきたと思います。残念ながら、コミュニケーションが不十分であった点やドキュメントの問題が、コミュニティにおける多くの不満や苦悩の大きな要因となってきました。
今後、私たちはそのコミュニケーションを改善する方法を見つけ、さらにはドキュメントの改善にもっと多くのコミュニティが関わってくれるようになることを期待しています。
]]>差分検出エンジン
以前投稿した記事(1、2)で、React.memoの仕組みと、コンポジションを通じてよりスマートにパフォーマンスを最適化する方法について説明しました。しかし、Reactのパフォーマンスを完全にマスターするには、すべてを動かすエンジンである、Reactの差分検出アルゴリズムを理解する必要があります。
差分検出は、ReactがDOMをアップデートし、コンポーネントツリーと一致させるプロセスです。Reactの宣言的プログラミングを可能にしているのが差分検出です。ユーザーが求めるものを説明すると、Reactがそれを効率的に実現する方法を探します。
コンポーネントの識別情報とstateの永続性
技術的な内容について話し始める前に、Reactがコンポーネントの識別情報(そのコンポーネントらしさを形成する独自性)についてどのように考えているかを示す驚くべき動作を見てみましょう。 以下の簡単なテキスト入力のトグル例をご覧ください。
const UserInfoForm = () => {
const [isEditing, setIsEditing] = useState(false);
return (
<div className="form-container">
<button onClick={() => setIsEditing(!isEditing)}>
{isEditing ? "Cancel" : "Edit"}
</button>
{isEditing ? (
<input
type="text"
placeholder="Enter your name"
className="edit-input"
/>
) : (
<input
type="text"
placeholder="Enter your name"
disabled
className="view-input"
/>
)}
</div>
);
};このフォームを操作すると、興味深い動作がみられます。編集画面で入力欄に任意のテキストを入力して「キャンセル」ボタンをクリックすると、再度「編集」ボタンをクリックしたとき、入力したテキストが残った状態になります。この現象は、2つのinput要素が異なるprops(1つは無効化され、クラスが異なります)を持っているにもかかわらず起こります。
ReactはDOM要素とそのstateを保持しますが、これはどちらの要素も同じタイプ(input)であり、要素ツリーの同じ位置にあるためです。Reactは要素を作り直すのではなく、単純に既存の要素のpropsを更新します。
しかし、実装を以下のように変更するとどうでしょうか。
{
isEditing ? (
<input type="text" placeholder="Enter your name" className="edit-input" />
) : (
<div className="view-only-display">Name will appear here</div>
);
}そうすると、編集モードを切り替えることで全く異なる要素がマウントおよびアンマウントされ、ユーザーの入力は失われます。
この動作は、Reactの差分検出の基本的側面に焦点を当てます。すなわち、要素タイプは識別情報を決める主要な要因であるということです。この概念を理解することが、Reactのパフォーマンスをマスターする上でカギとなります。
仮想DOMではなく要素ツリー
Reactがアップデートを最適化するために「仮想DOM」を使用するということはおそらくご存知でしょう。これは有益なメンタルモデルではありますが、Reactの内部を要素ツリー(画面上に表示される内容を簡単に表したもの)として考えた方が正確です。
以下のようなJSXを書くとします。
const Component = () => {
return (
<div>
<h1>Hello</h1>
<p>World</p>
</div>
);
};ReactはこれをJavaScriptのプレーンオブジェクトからなるツリー構造に変換します。
{
type: 'div',
props: {
children: [
{
type: 'h1',
props: {
children: 'Hello'
}
},
{
type: 'p',
props: {
children: 'World'
}
}
]
}
}divやinputのようなDOM要素では、「type」は文字列です。一方、カスタムReactコンポーネントでは、「タイプ」は実際の関数への参照です。
{
type: Input, // Reference to the Input function itself
props: {
id: "company-tax-id",
placeholder: "Enter company Tax ID"
}
}差分検出の仕組み
ReactがUIをアップデートする必要がある場合(stateの変更または再レンダリング後)以下のことを行います。
- コンポーネントを呼び出し、新しい要素ツリーを作成する
- 以前のツリーと新しいツリーを比較する
- 実際のDOMを新しいツリーと一致させるために必要なDOM操作を割り出す
- それらの操作を効率的に実行する 比較アルゴリズムは以下の基本原則に従います。
1. 要素タイプが識別情報を決める
Reactはまず要素の「タイプ」を確認します。タイプが変わる場合、Reactはサブツリー全体を再構築します。
// From this (first render)
<div>
<Counter />
</div>
// To this (second render)
<span>
<Counter />
</span>divがspanに変わったため、Reactは古いツリーの全体(Counterを含む)を破壊し、新しいツリーをゼロから構築します。
2. ツリー内の位置は重要
Reactの差分検出アルゴリズムは、ツリー構造内におけるコンポーネントの位置に大きく依存します。位置は、差分を比較する際に識別情報を示す主な要因となります。
// Let's pretend showDetails is true: Render UserProfile
<>
{showDetails ? <UserProfile userId={123} /> : <LoginPrompt />}
</>
// Let's pretend showDetails is false: Render LoginPrompt instead
<>
{showDetails ? <UserProfile userId={123} /> : <LoginPrompt />}
</>この条件式の例では、Reactはフラグメントの最初の子の位置を一つの「スロット」として扱います。showDetailsがtrueからfalseに変わると、Reactはそれぞれのレンダー結果の同じ位置にある情報を比較し、そこには異なるコンポーネントタイプ(UserProfile vs LoginPrompt)があります。ポジション1のコンポーネントタイプが変わったため、Reactは古いコンポーネントをすべて(stateも含めて)アンマウントし、新しいコンポーネントをマウントします。
このポジションベースの識別情報は、もっとシンプルなケースでコンポーネントがstateを保持する理由でもあります。
// Before
<>
{isPrimary ? (
<UserProfile userId={123} role="primary" />
) : (
<UserProfile userId={456} role="secondary" />
)}
</>この例では、isPrimaryの値にかかわらず、同じ位置に同じコンポーネントタイプ(UserProfile)があります。Reactはコンポーネントを再マウントするのではなく、シンプルにpropsを更新し、インスタンスを保持します。
このポジションベースのアプローチは、ほとんどのシナリオで有効ですが、以下の場合には問題が生じます。
- コンポーネントの位置が動的に移動する(リストのソート時など)
- コンポーネントの位置が変わる場合にstateを保持する必要がある
- コンポーネントを再マウントするタイミングを正確に制御したい
ここで活躍するのがReactのkeyシステムです。
3. keyはポジションベースの比較をオーバーライドする
デベロッパーは、key属性によりコンポーネントの識別情報を明確に制御し、Reactのデフォルト動作である位置に基づく識別をオーバーライドすることができます。
const TabContent = ({ activeTab, tabs }) => {
return (
<div className="tab-container">
{tabs.map((tab) => (
// Key overrides position-based comparison
<div key={tab.id} className="tab-content">
{activeTab === tab.id ? (
<UserProfile
key="active-profile"
userId={tab.userId}
role={tab.role}
/>
) : (
<div key="placeholder" className="placeholder">
Select this tab to view {tab.userId}'s profile
</div>
)}
</div>
))}
</div>
);
};条件式のレンダー結果としてUserProfileコンポーネントが異なる位置にくる場合でも、Reactは同じkeyを持つコンポーネントを同じコンポーネントとして扱います。タブが有効になると、「active-profile」keyが変わらないためReactはコンポーネントのstateを保持し、その結果、タブの切り替えをスムーズに行うことができます。
この例は、レンダーツリー構造上の位置にかかわらず、keyを用いることでコンポーネントの識別情報をいかにして維持できるかを示しています。keyは、Reactによるコンポーネント階層構造の差分検出を制御する強力な手段を与えてくれます。
keyの魔法
keyは主にリストにおける役割で知られていますが、Reactの差分検出プロセスに与える影響はそれだけにとどまりません。
keyがリストに必要である理由
リストをレンダリングする際、Reactはkeyを用いて項目の追加、削除、並べ替えを把握しています。
<ul>
{items.map((item) => (
<li key={item.id}>{item.text}</li>
))}
</ul>keyがなければ、Reactは配列上の要素の位置だけに頼らなくてはなりません。先頭に新しい項目を挿入した場合、Reactはすべての要素の位置が変わったとみなし、リスト全体を再レンダリングします。
keyがあれば、Reactは位置にかかわらずレンダー間の要素を照合することができます。
配列以外のkey?
Reactは、静的要素に対してkeyの追加を強要しません。
// No keys needed
<>
<Input />
<Input />
</>これは、Reactがこれらの要素が静的であることを知っているからです。つまり、ツリー上の要素の位置が予測可能だということです。
しかし、keyはリストの外でも強力なツールになり得ます。以下の例をご覧ください。
const Component = () => {
const [isReverse, setIsReverse] = useState(false);
return (
<>
<Input key={isReverse ? "some-key" : null} />
<Input key={!isReverse ? "some-key" : null} />
</>
);
};isReverseが切り替わると、2つの入力の間で'some-key'が移動するため、Reactはコンポーネントのstateを2つの位置の間で「移動」させることができます。
動的要素と静的要素を混在させる
動的リストに項目を追加することで、リストの後の静的要素の識別情報が変わるのではないかという懸念がよく聞かれます。
<>
{items.map((item) => (
<ListItem key={item.id} />
))}
<StaticElement /> {/* Will this re-mount if items change? */}
</>Reactはこの問題にスマートに対処します。動的リスト全体を最初の位置でひとまとまりとして扱うため、リストに変更があってもStaticElementは常に同じ位置と識別情報が保たれます。
React内部では以下のように表現されます。
[
// The entire dynamic array becomes a single child
[
{ type: ListItem, key: "1" },
{ type: ListItem, key: "2" },
],
{ type: StaticElement }, // Always maintains its second position
];リストに項目を追加または削除しても、StaticElementは親配列のポジション2のまま変わりません。つまり、リストに変更が加えられても再マウントされないということです。このスマートな仕組みにより、隣接する動的リストの変更によって静的要素が不必要に再マウントされることがなく、処理が最適化されます。
3. DOMを戦略的に制御するためのkey
keyの用途はリストに限りません。React上でコンポーネントやDOM要素の識別情報を制御するのに有益なツールです。Reactコンポーネントのstateを異なるビュー上で保持する際、keyとコンポーネントタイプが使われるということを覚えておきましょう。つまり、keyは同じでもタイプが異なれば、コンポーネントはアンマウントおよび再マウントされます。これらの場合、一般的にはstateのリフトアップの方が良い方法です。
// State lifting approach for preserving state across different views (keys are no good here...)
const TabContent = ({ activeTab }) => {
// State that needs to be preserved across tab changes
const [sharedState, setSharedState] = useState({
/* initial state */
});
return (
<div>
{activeTab === "profile" && (
<ProfileTab state={sharedState} onStateChange={setSharedState} />
)}
{activeTab === "settings" && (
<SettingsTab state={sharedState} onStateChange={setSharedState} />
)}
{/* Other tabs */}
</div>
);
};この場合、タブ間でタイプ(および参照先)が異なるため、keyを保持するだけでは不十分です。
しかし、keyと非制御コンポーネントを用いた以下の例をご覧ください。
const UserForm = ({ userId }) => {
// No React state here - using uncontrolled inputs
return (
<form>
<input
key={userId}
name="username"
// Uncontrolled input with defaultValue instead of value
defaultValue=""
/>
{/* Other form inputs */}
</form>
);
};userIdに基づくkeyを非制御入力に与えることで、ReactはuserIdが変わるたびに全く新しいDOM要素を作成するようになります。非制御入力のstateがReactのstateではなくDOM自体の中に存在するため、ユーザーを切り替える際に入力が効果的にリセットされます。この場合、必要なのはkeyだけです。
非常に秀逸です。
stateコロケーション:強力なパフォーマンスパターン
stateコロケーションは、stateを使用場所のできるだけ近くにとどめておくパターンです。このアプローチでは、state変更の影響を直接受けるコンポーネントだけがアップデートされるようにすることで、不要な再レンダリングを最小限にとどめます。
以下の例をご覧ください。
// Poor performance - entire app re-renders when filter changes
const App = () => {
const [filterText, setFilterText] = useState("");
const filteredUsers = users.filter((user) => user.name.includes(filterText));
return (
<>
<SearchBox filterText={filterText} onChange={setFilterText} />
<UserList users={filteredUsers} />
<ExpensiveComponent />
</>
);
};filterTextが変わると、フィルターの影響を受けないExpensiveComponentも含めてAppコンポーネント全体が再レンダリングされます。
では、フィルターのstateを、それを使用するコンポーネントとだけコロケーションしてみましょう。
const UserSection = () => {
const [filterText, setFilterText] = useState("");
const filteredUsers = users.filter((user) => user.name.includes(filterText));
return (
<>
<SearchBox filterText={filterText} onChange={setFilterText} />
<UserList users={filteredUsers} />
</>
);
};
const App = () => {
return (
<>
<UserSection />
<ExpensiveComponent />
</>
);
};そうすると、フィルターが変わっても、UserSectionだけが再レンダリングされます。このパターンは、パフォーマンスを改善するだけでなく、各コンポーネントが保持するstateだけを管理するようにすることで、より良いコンポーネント設計を可能にします。
コンポーネント設計:変更の最適化
パフォーマンスの最適化は、コンポーネント設計においてしばしば課題となります。コンポーネントの機能が多すぎると、不要な再レンダリングが行われる可能性が高くなります。
React.memoに頼る前に、以下の点を検討してみましょう。
- コンポーネントに複数の責任が与えられていないか。複数の関心事を処理するコンポーネントは、頻繁に再レンダリングする可能性が高くなります。
- stateをリフトアップしすぎていないか。stateをツリー上で必要以上にリフトアップすると、より多くのコンポーネントが再レンダリングされるようになります。
以下の例をご覧ください。
// Problematic design - mixed concerns
const ProductPage = ({ productId }) => {
const [selectedSize, setSelectedSize] = useState("medium");
const [quantity, setQuantity] = useState(1);
const [shipping, setShipping] = useState("express");
const [reviews, setReviews] = useState([]);
// Fetches both product details and reviews
useEffect(() => {
fetchProductDetails(productId);
fetchReviews(productId).then(setReviews);
}, [productId]);
return (
<div>
<ProductInfo
selectedSize={selectedSize}
onSizeChange={setSelectedSize}
quantity={quantity}
onQuantityChange={setQuantity}
/>
<ShippingOptions shipping={shipping} onShippingChange={setShipping} />
<Reviews reviews={reviews} />
</div>
);
};サイズ、数量、または配送オプションが変わるたびに、無関係なレビューセクションも含めてページ全体が再レンダリングされます。
より良い設計は、以下のようにこれらの関心事を分けます。
const ProductPage = ({ productId }) => {
return (
<div>
<ProductConfig productId={productId} />
<ReviewsSection productId={productId} />
</div>
);
};
const ProductConfig = ({ productId }) => {
const [selectedSize, setSelectedSize] = useState("medium");
const [quantity, setQuantity] = useState(1);
const [shipping, setShipping] = useState("express");
// Product-specific logic
return (
<>
<ProductInfo
selectedSize={selectedSize}
onSizeChange={setSelectedSize}
quantity={quantity}
onQuantityChange={setQuantity}
/>
<ShippingOptions shipping={shipping} onShippingChange={setShipping} />
</>
);
};
const ReviewsSection = ({ productId }) => {
const [reviews, setReviews] = useState([]);
useEffect(() => {
fetchReviews(productId).then(setReviews);
}, [productId]);
return <Reviews reviews={reviews} />;
};この構造では、製品サイズを変えてもレビューが再レンダリングされることはありません。メモ化も不要です。コンポーネントの境界を明確にするだけです。
差分検出とクリーンアーキテクチャ
差分検出に関するこうした理解は、クリーンアーキテクチャの原則とも完全に一致します。
- 単一責任の原則:コンポーネントを変更する理由は1つに限定します。各コンポーネントが1つの責任に徹することで、不要な再レンダリングがトリガーされる可能性が低くなります。
- 依存関係逆転:コンポーネントは具体的な実装ではなく、抽象化に依存するべきです。そうすることで、コンポジションを通じてパフォーマンスを最適化しやすくなります。
- インターフェース分離:コンポーネントには、最低限の特化したインターフェースを与えます。そうすることで、propsの変更が不要な再レンダリングをトリガーする可能性が低くなります。
実践的ガイドライン
差分検出に関する深掘りに基づく実践的なアドバイスをいくつか紹介します。
- コンポーネントの定義は親コンポーネントの外に置き、再マウントを回避する。
- stateをリフトダウンし、再レンダリングの境界を分離する。
- 同じ位置のコンポーネントタイプの一貫性を保ち、アンマウントを回避する。
- keyを戦略的に利用する。リストに限らず、コンポーネントの識別情報を制御したい場合に使用する。
- 再レンダリング問題をデバッグする際、要素ツリーとコンポーネントの識別情報の観点で考える。
- React.memoは差分検出の制約の範囲内で有効なツールにすぎないことを念頭に置く。基本的なアルゴリズムは変わらない。
おわりに
Reactの差分検出アルゴリズムを理解すると、Reactのパフォーマンスに関するさまざまなパターンの仕組みが見えてきます。コンポジションがなぜこれほどまでに有効なのかや、リストにkeyが必要である理由、他のコンポーネント内でコンポーネントを定義するのがなぜ問題なのかがわかります。
この知識を身につけることで、アーキテクチャに関してより良い判断ができるようになり、Reactアプリケーションのパフォーマンスも自然と向上します。Reactの差分検出アルゴリズムに過剰なメモ化で対抗するのではなく、Reactがコンポーネントを識別し、更新する方法に合わせたコンポーネント構造を設計することで、うまくReactを使いこなせるようになるはずです。
次にReactアプリケーションを最適化する際には、コンポーネント構造が差分検出プロセスにどのような影響を及ぼしているのかを考えてみてください。Reactがコンポーネントを識別し、更新する方法を踏まえた、よりシンプルで特化したコンポーネントツリーが最も効果的な最適化である場合もあります。
]]>今から2年前の2023年3月に“The End of Front-End Development”(フロントエンド開発の終焉)という記事を投稿しました。ちょうどOpenAIがGPT-4を発表した後で、多くの人が近い将来、ソフトウェアはすべて機械が作るようになり、人間のソフトウェア開発者は不要になるだろうという考えに傾いていました。
筆者はこうした論調には懐疑的で、当面の間、ソフトウェア開発は依然として人間の助けを必要とするだろうと前述の記事の中で主張し、その理由を論じました。筆者が立てた仮説は、大規模言語モデル(LLM)は人間の開発者を置き換えるのではなく、補強するというものです。
当時、Twitter上ではAIの登場により数カ月、長くても1、2年で人間のフロントエンド開発者の需要は無くなるとの意見が大勢を占めていました。あれから2年以上が経ちますが、現実はどうでしょうか。当時言われていたような「ポストデベロッパー」時代は到来しているでしょうか。
この記事では、現在の状況を新たな視点から捉え直し、何がどう変わったのか、今後どのような進化の過程を辿るのかを検討してみたいと思います。この記事が、開発者を志しながらも今後のキャリアに不安を覚えている読者の参考になれば幸いです。❤️
企業によるAIの利用状況
ここ数年、AIツールを導入する企業がますます増えています。最近、フォーブス誌に“AI Writes Over 25% Of Code At Google”(Google社では25%以上のコードをAIが書いている)という記事が掲載されました。
この記事のタイトルは、AIが25%、人間が残りの75%の仕事を行っているように読めますが、実際はそうではありません。これは誤解を招くタイトルだと思います。
Google社でコミットされるコードの25%をAIが生成していたとしても、AIが単独で作業を行っているわけではありません。熟練した人間の開発者が運転席に座り、知識と経験をもとにAIを操り、生成物を編集したり形成したりした上で、自分が書いたコードに組み込んでいるのです。筆者の知る限り、Google社では今もコードは100%「開発者」が作成しています。AIは彼らが仕事で使う多くのツールの一つに過ぎないのです。
つまり、Google社は製品チームの開発者の25%を解雇し、疑似知性を持つAIロボットがその代わりを務め、プロダクトマネージャー直属の部下として自律的に作業を行っているわけではないということです。大手ハイテク企業でそのようなことが起きているという話は聞いたことがありません。
一方で、自社のAIが人間の開発者を完全に置き換えることができると主張しているスタートアップ企業はあります。中でも最もよく知られているのは、1年前の2024年3月にCognition社が発表したDevinという製品です。しかし、実際に企業が使おうとすると、さまざまな問題に直面します。例えば、あるチームの報告によると、Devinは割り当てられた20件のタスクのうち3件しか完了できず、結局は手間がかかり導入する価値はないと判断されたようです。このチームは1カ月で使うのをやめました。
一部のメンバーの声を紹介します。
none
AIは十分に定義された小さなタスクはこなせますが、自分でやった方が早く、好きなやり方でできるので、その方がいいです。時間を節約できそうな大きなタスクは失敗する可能性が高いと思います。結局、使いたい場面があまりないという印象です。
-- ジョノ・ウィテカー
none
自分で手を加えられるので、最初はすごく身近に感じられて感動したのですが、使っているうちに変更が必要な点がどんどん出てきて、次第に不満が溜まるようになりました。最終的には一から順番にやり直した方がいいという結論に達しました。
-- アイザック・フラス
これらの意見はAI懐疑論者のものではなく、AI関連のスタートアップ企業に在籍し、熱意と善意を持って製品を使ってみた技術者のものです。また、彼らの体験は例外的ではありません。他にもいくつか実際にAIを使用した人の体験談・ブログなどを読みましたが、どれもあまり役に立たないという結論で一致していました。
筆者の知る限り、AI導入の成功事例には必ず熟練した人間の開発者が関わっています。したがって、ポストデベロッパー時代は到来していないと言えるでしょう。
逸脱するAI
筆者自身、数年前から多数のAIツールを試してみています。数カ月前、AI駆動の統合開発環境(IDE)であるCursorに乗り換えました。Claude SonnetでCursorの「エージェント」モードを使っていますが、率直に言ってかなり素晴らしいです。特定の種類のタスクでは、コンテキスト情報を与えて正しい方向を示せば、実行可能なソリューションを一発で生成してくれます。
TypeScriptの型のエラーやリンターエラーを検出し、多くの場合、修正することもできます。新たな発見や学びが得られたことも何度かありました。筆者が知らないAPIを使ったソリューションをAIが提案してくれたおかげで、当初検討していたものよりも良いコードが書けました。
しかし、AIは完璧ではありません。誘導する必要があります。
感覚的には、”クルーズコントロール”を使って高速道路を走るのに近いかもしれません。車は概ね進行方向に沿って走りますが、フラフラしないようハンドルを握る必要があります。そうしないと、車が徐々に車線からはみ出してしまいます。時折車線内に戻してあげないと、側溝に落ちてしまいます。
開発者不要論の問題点はまさにそこにあります。コードの書き方を知らなければ、モデルが生成したコードに重大な問題が潜んでいたとしても、気づくことができません。軌道修正の図り方も、軌道修正が必要であることも分からないでしょう。
LLMを使ってノーコードでプロジェクトを構築した人の話を聞くと、みな同様の経験をしています。出だしは好調でも、やがてどうAIを促してもこれ以上は進めないという局面に行き着きます。コードはちぐはぐで混沌とし、ある一定の線を越えるといくら応急処置を施しても維持できなくなります。そうなると、プログラム全体が破綻してしまいます。
また、LLMが不得意なタスクもたくさんあります。10分かけてClaudeに意図を理解させようとするもできず、諦めて自分で実装したら5分でできたというようなストレスの溜まる経験をしたことも何度かあります。次第にどのタスクをAIに任せ、どのタスクは昔ながらの方法で処理するのがいいか直感で分かるようになってきました。
総合すると、LLMはかなりの時間を節約してくれます。自分でやると30分かかる作業をLLMが30秒で終わらせてくれたこともあります。そういう時は本当に爽快です。しかし、実際のところ、自らコードを書いている時間の方がまだ圧倒的に多いです。
プロレスのタッグマッチのように、Claudeが得意なタスクではタッチして交代し、処理してもらいます。しかし、まだ自分でやるほうが速く簡単なので、ほとんどのコードは自分が書いています。
現在の就職市場
何年か前にこの記事を書いたとき、就職市場はかなり厳しい状況にありました。残念ながら、現在もまだ厳しい状況は変わっていません。
求職中の読者は、以前ほど質の高い求人がなく、良い求人には応募が殺到することをご存知でしょう。面接の機会を得るのも非常に難しく、内定をもらうのがいかに難しいかは言うまでもありません。
しかし、この状況は企業が開発者を自律型AIエージェントに置き換えているからではないと思います。すでに述べたとおり、筆者がこれまで読んできた実際の体験談はその仮説を裏付けるものではありません。では何が起きているのでしょうか。なぜこれほど厳しい状況が続いているのでしょうか。
これにはいくつかの要因が絡んでいると思います。
- マクロ経済的要因。金利がまだ比較的高く、スタートアップ企業は事業を拡大し開発者を雇うのに必要な資金を調達するのが難しい状況にあります。ここ数年、景気後退が間近に迫っているという景況感が続いています。
- レイオフ。大手ハイテク企業は、ここ数年の間に数十万人の労働者をさまざまな理由で一時的に解雇しています。これはつまり、多くの有能な開発者が仕事を探しているということです。
- AI神話。一部の企業は、いまだにAIが近い将来開発者を不要にすると考えており、積極的な雇用を行っていません。
3つ目に挙げた点については特にもどかしい思いがします。AGI* が実用化直近であり、実用化されれば人間の開発者は一切不要になると信じて企業は必要な開発者の雇用を控えているのです。「じきにそうなります」と言い始めてもう数年が経ちます。
*汎用人工知能: 人間のように学習・推論したり、まだ学んでいないこともこなすことができるAI。
今後の展望
2023年に“The End of Front-End Development”を執筆した当時、筆者は開発者を目指しキャリアをスタートさせたばかりで、コーディングを勉強中の読者にメッセージを届けたいと考えていました。世間の見通しがあまりに暗かったため、ネット上に渦巻く FUD* を少しでも解消したいと思っていました。
*不安や懸念、不透明感
過去2年間でさまざまな変化がありましたが、変わっていないことが2つあります。
- 企業は製品を作るためにまだ人間の開発者を必要としています。
- AIエバンジェリストは、もうじき企業は製品を作るのに人間の開発者が不要になるといまだに主張しています。
開発者を目指し大学やブートキャンプ、または独学で勉強中の読者もいると思いますが、皆さんが就職するチャンスはあると確信しています。ソフトウェア開発が完全に自動化されるのはまだかなり先の話だというのは明らかです。開発者の代わりではなく、開発者の生産性を高めるツールとしてAIを活用した方が遥かに効果的であることに企業が気づけば、自らの成長を妨げるような行為をやめ、より積極的に雇うようになると思います。
AIモデルは間違いなく改善し続けるでしょう。毎週のように新しいモデルがリリースされてはベンチマークの記録を更新しています。最近では、Google社がGemini 2.0 Flashと2.5 Proモデルを発表しました。
 出典:
出典:テクノロジーは進化の曲線がより緩やかになるポイントに達したように筆者は感じています。ゲームチェンジャーと呼べるような発表はしばらく出ていません。新たに出てくるモデルは少しずつ改良されてはいますが、全く新しい課題を解決するというより、すでに優れている点をさらに向上させるものです。
現在の就職市場は見通しが厳しいと感じますが、少なくとも米国では正しい方向に進んでいます。
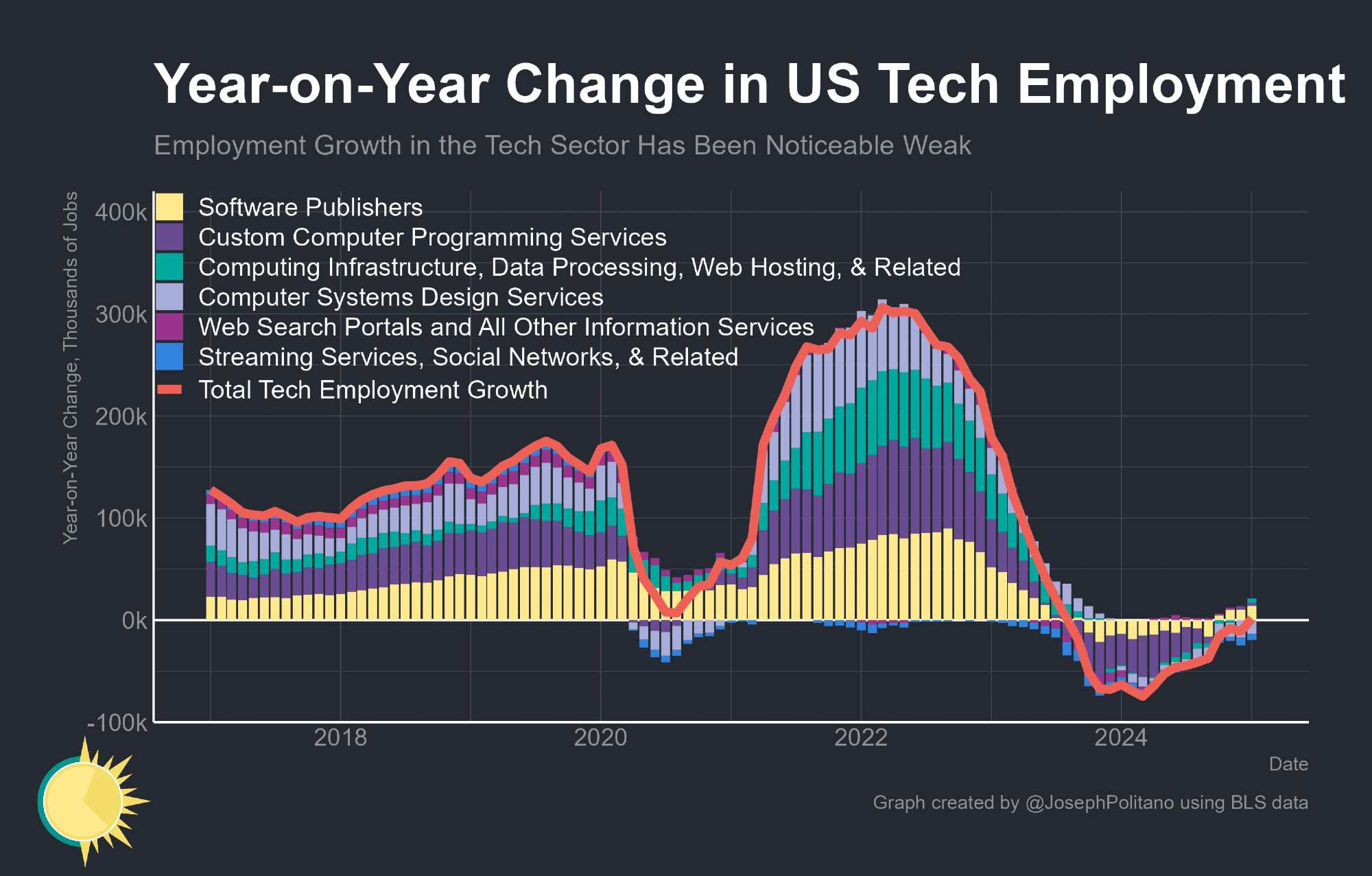 出典:Joey Politanoのラブリーなグラフ!
出典:Joey Politanoのラブリーなグラフ!
AIによって本当にソフトウェア開発者が不要になっているのであれば、ハイテク系の雇用数は急速に減少しているはずだと思いますが、この1年の雇用数は増えています。この傾向が続けば、近い将来市場の見通しはかなり明るくなるでしょう。
懸念点
2023年の時点で、AIがすぐにソフトウェア開発者の仕事を奪うことにはならないという自信がそれなりにありました。それから2年が経ち、その自信は一層深まりました。コーディングは依然として極めて貴重なスキルであり、それがすぐに変わるとは思えません。
とは言え、何もかも順調で誰も心配する必要はないと言っているわけでもありません。
昨今の世界情勢は、経済をはじめ、あらゆる面で広範な影響と不確実性をもたらしているように思います。これらがハイテク業界に与える影響については予測が難しいものの、私としては挑戦的な時期となるのではないかと考えています。
次の世代の開発者について少し心配しています。LLMエージェントを使っているとトランス状態に陥り、生成されるコードを理解しないまま、あるいは見ることさえしないまま、機械的に変更を受け入れるようになりがちです。1筆者も、新しいコースのランディングページをビルドしている際にその罠にはまりそうになっていることに気づきました。ハンドルから長く手を離し過ぎてしまったため、奇妙なジャンクコードのリファクタリングに多くの時間を費やすはめになりました。
最も楽な道は、何もせず機械に任せることですが、そうすると機械が行き詰まったときにコードを修正したり、デバッグしたりするのに必要なスキルが身につきません。
一方で、LLMを積極的に利用するのであれば、今がコーディングを学ぶ絶好の機会です。筆者の場合、よく分からないTypeScriptエラーが出たときに、AIが理解を助けてくれたり、適切な資料を見つけるために必要なキーワードを示してくれたりすることが多々あります。まるで自分だけの個人講師が不明点を理解する手助けをしてくれているような感覚です。2
今後数年間がどうなるかは誰にも分かりませんが、1、2年後に企業がようやく人間の開発者がまだ必要であることを受け入れ、熟練した人間が強力なLLMを使うことで驚くべきことを成し遂げられることに気づき、ちょっとした「開発者ルネサンス」が起きても驚きません。✨
ソフトウェア開発に情熱を持ち、この仕事が高い給料を稼いでアッパーミドルクラスの暮らしを手に入れられる見込みが最もありそうだと考えているのであれば、AIの誇大宣伝に惑わされ、自信を失わないでいただきたいと思います。企業は今も雇用し続けていますし、それは当分変わらないと思います。💖
none
就職活動のヒント
現在の就職市場で仕事を勝ち取るチャンスを最大限に高める方法について話したいと思います。
最初に理解しておくべきことは、AIの登場により企業の雇用プロセスが悲惨なものになっているということです。求人を出すと、AIが生成した質の低い応募書類が何千通も届く場合があり、採用担当者にとってもすべての書類に目を通すのは困難です。求人に応募しても、他の応募書類の山に埋もれてしまう可能性が高いでしょう。
この状況に対する解決策は2つあります。
- 求人が出てから数日以内の早い段階で応募する。
- コネを頼る。
ハイテク業界に入ってまだ日が浅い場合、おそらく人脈と呼べるようなものはないでしょう。でも大丈夫。今日から築き始めればいいのです。 😄
方法はいくつもあります。一番手っ取り早いのが、地元で開催されているオフ会を探すことです。こうしたイベントに参加すれば、自分が就職したいと思っている会社で働いている開発者に会える可能性があります。あなたの応募書類が埋もれてしまわないよう手助けしてくれるかもしれません。
しかし正直なところ、これは筆者のように内向的な読者にとっては最適な方法ではないかもしれません。筆者が駆け出しの頃は、地元のオフ会に参加しても気後れして初対面の人に話しかける勇気がありませんでした。結局コネを作ることはできず、何の役にも立ちませんでした。 😅
幸い、他にも多くの選択肢があります。筆者の場合は、自分がビルドしたプログラムをネット上に公開することでネットワークを築きました。オープンソースプロジェクトに貢献したり、Discordコミュニティで交流したりしてもいいでしょう。筆者のブログ記事“Becoming a Software Developer Without a CS Degree”(CSの学位がなくてもソフトウェア開発者になれる方法)に書いたように、自分の強みを生かすことが成功への近道になります。
また、コミュニティもチャンスを見つける上で助けになる場合があります。腹立たしいことに、ネット上には単にデータを集めることだけを目的とした、架空の会社の求人が無数にあります。自分のLinkedInの連絡先に登録されているユーザーの勤務先をチェックし、注目すべき実在する企業のリストを作成するのも良いでしょう。
厳しい世の中ですが、これらのヒントが時間と労力の節約になれば幸いです。❤️
React Server Componentsを理解する
React Server Components(RSC)の登場により、Reactエコシステムにおけるサーバーレンダリングの重要性が高まりました。RSCを使用することで、デベロッパーは一部のコンポーネントをサーバー側でレンダリングしつつ、抽象化によりクライアントとサーバーの隔たりを感じさせないユーザビリティを実現することができます。Client ComponentsとServer Componentsをコード内に混在させることで、すべてのコードが1カ所で実行されているように見せることができます。
しかし、抽象化には常にコストが伴います。そのコストとはどのようなものでしょうか。RSCはいつ「使える」のでしょうか。バンドルサイズが小さくなると、帯域幅も狭まるのでしょうか。RSCを「使うべき」ときはいつでしょうか。RSCを適切に使う上でデベロッパーが従うべきルールは何でしょうか。そのルールが存在する理由は何でしょうか。
これらの問いに答えるため、RSCの仕組みを詳しく見ていきましょう。React本体と、ReactのメタフレームワークというRSCの2つの側面について考察します。特に、RSCに関する正確なメンタルモデルを構築できるよう、ReactとNext.jsの内部構造について説明します。
none
この記事は、Reactを使い慣れたデベロッパーを対象としています。読者には、コンポーネントやフックに関する予備知識が前提条件として求められます。
また、JavaScriptのPromise、async、awaitについても熟知していることを想定しています。これらに関する知識がない方は、Promise、async、awaitの仕組みに関する筆者のYouTube動画をご覧ください。
Reactのあらゆる側面についてゼロから詳しく知りたい方は、筆者の「Understanding React(Reactを理解する)」コースをぜひチェックしてみてください。このコースでは、Reactのソースコードを掘り下げることで、JSX、Fiber、コンポーネント、フック、フォームなどの仕組みを理解していただくことができます。
まずは、RSCの仕組みを理解するために必要な基本を見ていきましょう
DOMとクライアントレンダリング
Reactでは「レンダリング」という表現を固有の意味で使っています。一般的にはブラウザがページを「レンダリング」するという場合、DOMを画面に描画する処理をいいます。ブラウザは、DOM(要素のツリー構造)とCSSOM(計算済みスタイルのツリー構造)をもとに、各要素の配置を計算し、適切なピクセルを画面に描画します。
一方、Reactでは「DOMの見た目を計算すること」を「レンダリング」といいます。関数コンポーネントが返す値はReactに対し、DOMの見た目に関する情報を伝えます。
したがって、React(およびReactに追随する形で登場した他のフレームワーク)の世界では、「クライアントレンダリング」という場合、ブラウザ上で関数コンポーネントを実行することをいいます。
Reactでいう「レンダリング」は、必ずしもブラウザによる実際のレンダリングを伴いません。なぜなら、DOMの見た目がすでにReactがこうあるべきと考える見た目になっている場合があるからです。
実際、Reactのコアアーキテクチャ(および他のすべてのJSフレームワーク)における重要な点は、内部コードが更新するDOMの量を制限することにあります。
ツリーの差分検出処理
Reactのソースコードの中には、appendChildなどのブラウザDOM APIを呼び出し、クライアント上のDOMを更新するコールがあります。Reactは、ツリーの差分検出処理(reconciliation)や差分計算(diff)によって、ブラウザDOM APIを実行するタイミングを決めます。
React Compilerに関する記事に書いたように、ReactはDOMの現在の見た目と、見た目がどうあるべきかをJavaScriptオブジェクトツリーで管理しており、各ノードはFiberと呼ばれます。
Reactは、JavaScriptオブジェクトツリーの2つの枝でDOMの見た目がどうあるべきか(「WORK-IN-PROGRESS」)を計算し、DOMの現在の見た目(「CURRENT」)と比較します。
次に、2つのツリーの差分を検出し、currentツリーをworkInProgressツリーに変換するために必要なステップを計算します。そのステップは「diff」と「patch」(パッチ処理)です。
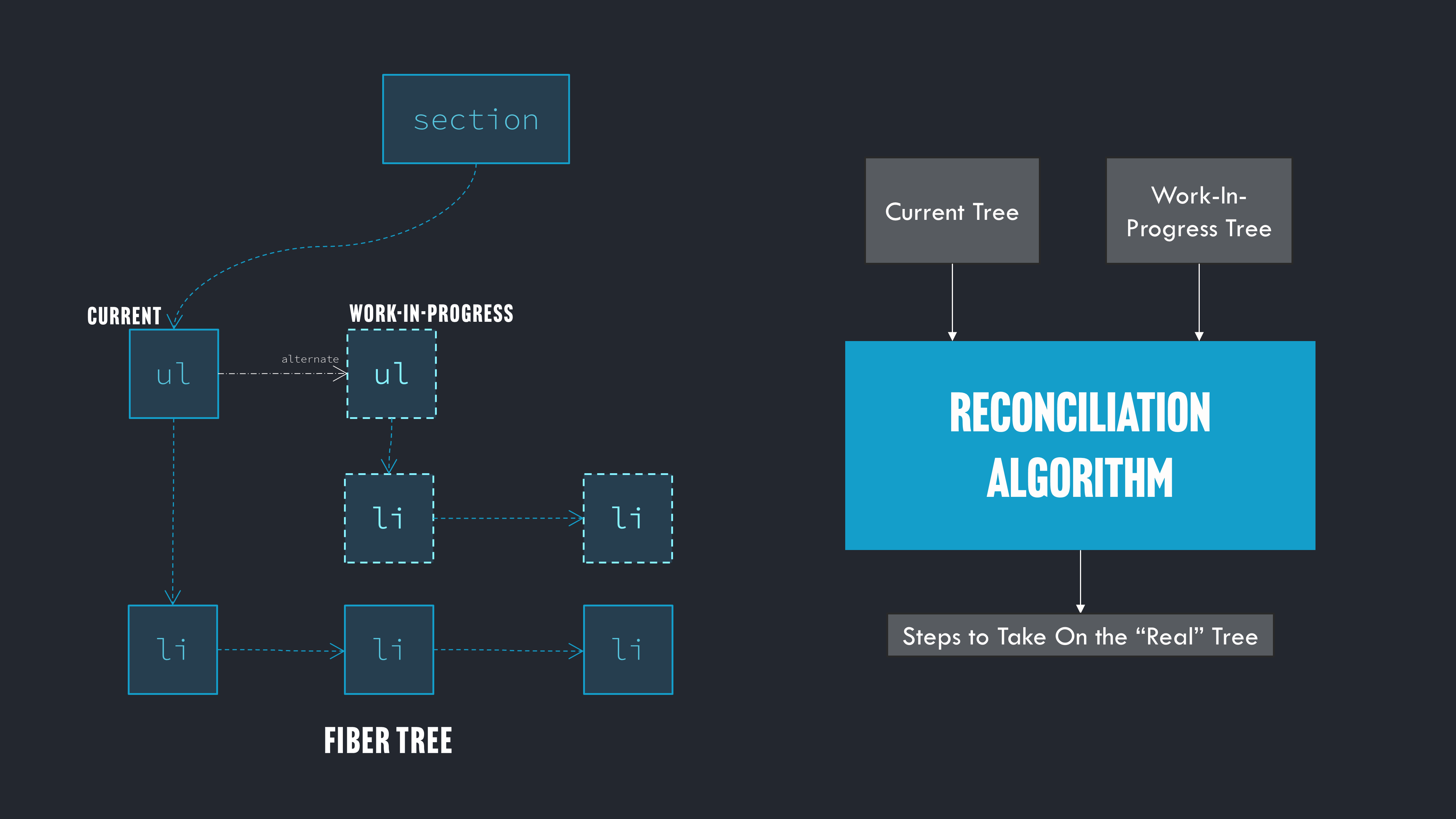
単純なJavaScriptオブジェクトとの比較計算が終わると、実際のDOMにおいて取るべきステップが明らかになります。DOMの更新はコストがかかり、ブラウザの再レンダリング(要素の配置とピクセルの描画)を伴うため、最低限取るべきステップの数を特定することで、DOMに対して必要な更新を最小限にとどめることができます。
クライアント上でDOMを更新すれば、UIを更新する際にstateを保持できるメリットがあります。例えば、ユーザーがフォームに情報を入力し、Reactが何らかのイベントをもとにUIを更新しても、入力したテキストはフォーム上に保持されます(ページが再読み込みされた場合は保持されません)。
したがって、Reactではクライアント上でDOMを更新することを重視しており、最初に偽のDOMに対して処理を行うことで可能な限り効率的に更新しようと努めています。このようなJavaScriptのDOM構造の偽コピーを一般的に「仮想DOM」と呼びます。
none
「仮想DOM」は適切な表現か?
ReactにおけるDOMと似た構造のJavaScriptオブジェクトの集まりを以前は「仮想DOM」と呼んでいました。しかし、実際はiOSやAndroidのネイティブアプリ(React Native)などへのレンダリングが可能なため、Reactは今ではこの呼称を好んでいません。
実際、Reactは複数のツリーを扱います。関数コンポーネントが返すReact要素(JSオブジェクト)のツリーや、React要素を変換したもので、stateなどを格納するために使用される Fiber(同じくJSオブジェクト)のツリーなどです。
普段はより具体的な名前でこれらのツリーを呼びますが、この記事では、RSCの仕組みを理解するうえで便利なので、昔から日常会話でよく使われている「仮想DOM」という呼称を使いたいと思います。
Reactが「レンダリング」と呼ぶのは、仮想DOMの計算処理です。具体的には、関数コンポーネントを実行し、リアルDOMの見た目がどうあるべきかを決めることをいいます。この処理はすべて関数を実行するJavaScriptエンジンの中で、リアルDOMに反映される差分が全く検出されなくなるまで行われます。
Reactが「レンダリング」という表現を使う理由を理解すると、RSCを正確に説明するうえで非常に役立ちます。
RSCを理解するためには、Web開発におけるクライアントレンダリングおよびサーバーレンダリングと、Reactが重点を置く仮想DOMの生成の違いを明確に理解する必要があります。
Reactでいう「レンダリング」では、実際には必ずしも何かが目に見える形で起こるわけではありません。

「レンダリング」という言葉のさまざまな意味については、確認しながら説明を進めたいと思います。一般的な(React以外での)定義を「古典的」と呼び、Web開発の用語として定義してみましょう。
none
レンダー【render】 【動詞】 /réndər/
- (古典的クライアントサイド)DOMとCSSOMをもとにレイアウトを計算し、画面にピクセルを描画すること。
- (Reactクライアントサイド)仮想DOMを構築して更新するために関数コンポーネントを実行すること。
DOMとサーバーレンダリング
RSCについて説明を進めるには、時間を遡る必要があります。長年、インターネットの中心概念の一つとして、サーバーからHTMLを配信するという考え方があります。
サーバー上にHTMLファイルを(NodeJSやPHPなどのサーバー技術を使って)作成することを、古典的な「サーバーサイドレンダリング」や「サーバーレンダリング」と呼びます。これは、先ほど説明した古典的なクライアントレンダリングの意味とも違います。従来、サーバーレンダリングとはサーバー上で「HTMLの文字列を生成する」ことを意味しました。
これにはいくつかの利点があります。ブラウザはHTMLを素早くDOMに変換することができます。そのため、HTMLは「ブラウザ上で素早くレンダリング」されます。JavaScriptでDOMを更新すると、もっと時間がかかります。また、サーバーの方がデータベースやファイルストレージに近いため、これらの処理をより効率的に行うことができます。
デメリットとしては、クライアントは再度HTMLを要求することができますが、stateが失われてしまいます(ページが再読み込みされる)。
Web開発においては、そのバランスをどう取るかが長年課題となっていました。サーバー側でレンダリングされたHTMLは素早く表示されますが、クライアント側のJavaScriptを通じてDOMを更新すると、ページのstateを維持したまま変更を加えることができます。
Reactでは両方行えますが、それは何も新しいことではありません。Reactはクライアント側のJavaScriptを使ってDOMを更新しますが、デベロッパーはかなり前からReactのコンポーネントをサーバー側でレンダリング(SSR)することができていました。
サーバー(NodeJSなどを通じて独自のJavaScriptエンジンを実行)は、コンポーネントを実行し、クライアントに送信するHTML文字列を生成します。ただし、大きな注意点があります。同じコンポーネントのJavaScriptコードもすべてクライアントに送信して実行する必要があったのです。
それはなぜでしょうか。関数コンポーネントが返す値をもとに仮想DOMを構築できるようにするためです。仮想DOMはリアルDOMを「ハイドレート」するために使用します。これは例えば、ボタンがクリックされたときに、どの関数コンポーネントの中のどのクリックイベントを実行するべきかがわかるということです。覚えておかなくてはならないのは、Reactが機能するためには、クライアント上に両方のツリー(DOMと仮想DOM)が存在する必要があるということです。したがって、ReactにおけるSSRでは、関数を2回実行する必要があります(1回はサーバー上でHTMLを生成するため、もう1回はクライアント上で仮想DOMを作成するため)。
参考までに、SSR/ハイドレーションプロセスを以下に可視化しています。
ここでReact Server Componentsの登場です。RSCは、サーバー上で実行されるReactコンポーネントとクライアント上で実行されるReactコンポーネントを、サーバーコンポーネントのJavaScriptコードの送信と再実行を行うことなく混在させることができます。さらに、ブラウザ上でDOMの更新を始める前に、最初にサーバー上でHTMLをレンダリングすることも可能です。
なぜ可能なのでしょうか。
まずは用語の定義を更新しましょう。
none
レンダー【render】 【動詞】 /réndər/レンダリング
- (古典的クライアントサイド)DOMとCSSOMをもとにレイアウトを計算し、画面にピクセルを描画すること。
- (Reactクライアントサイド)仮想DOMを構築して更新するために関数コンポーネントを実行すること。
- (古典的サーバーサイド)DOMを構築するためにクライアントに送信するHTMLを生成すること。
- (ReactサーバーサイドSSR)DOMを構築するためにクライアントに送信するHTMLを生成するために関数コンポーネントを実行すること。
none
サーバーサイド生成はどうか?
ここで取り上げていないものの一つがSSG(サーバーサイド生成)です。これは、アプリをビルドする(デプロイ可能にする)際に、HTMLをあらかじめ生成することを意味します。これは、Client ComponentsとServer Componentsの両方に対して行えます。
SSGの定義は、作成中の辞書収録項目におけるSSRの定義と同じです。この記事では、SSGとSSRの違いを明らかにしてもあまり役に立たないので詳しくは述べませんが、SSGもサポートされています。
先ほど、Reactが機能するためには、DOMと仮想DOMの両方のツリー全体がブラウザのメモリ上に存在しなくてはならないとお話ししました。では、React Server Componentsがサーバー上でのみ実行されればよく、クライアントがJavaScriptコードをダウンロードして実行する必要がないのはなぜでしょうか。
つまり、Reactは「サーバー」上で実行された関数によってレンダリングされた部分について、どのようにして「ブラウザ」上に仮想DOMを構築するのでしょうか。
Flight
サーバー上で関数コンポーネントを実行し、その結果をもとにクライアント上に仮想DOMを構築できるようにするために、Reactはサーバー上で実行された関数が返したReact要素ツリーを「シリアライズ」する機能を追加しました。
多くの場合、シリアライズは「コンピューターのメモリ上のオブジェクトを文字列に変換する」こと、デシリアライズは「文字列をコンピューターのメモリ上のオブジェクトに復元する」ことを意味します。
この場合、関数コンポーネントの結果はシリアライズしてクライアントに送信する必要があります。
筆者のReactコースに登録した生徒の数を把握するための簡単なアプリを作成するとします。まずはNext.jsで基本的なRSCを作成します。これはサーバー上で実行されます。
export default function Home() {
return (
<main>
<h1>understandingreact.com</h1>
</main>
);
}none
同型コンポーネント
サーバーとクライアントの両方で実行可能なコンポーネントを「同型(isomorphic)」と呼びます。上の関数はサーバーに特化したこと(データベースに直接接続する、サーバー上のファイルを読むなど)を何も行わないため、クライアント上で実行することも可能であり、Reactは通常どおり直接その結果をもとに仮想DOMを構築することができます。
関数が同型である場合、共有することができます。Server ComponentsとClient Componentsのどちらもそれをインポートして使用することができます。
この関数を実行するためにクライアントに送信しなくてもいいように、その結果をシリアライズする必要があります。Reactのコードベースの中では、このシリアライズ形式を「Flight」と呼び、送信したデータの総和を「RSC Payload」と呼びます。
筆者の簡単な関数の結果をシリアライズしたものが以下です。
"[\"$\",\"main\",null,{\"children\":[\"$\",\"h1\",null,{\"children\":\"understandingreact.com\"},\"$c\"]},\"$c\"]"分析しやすいようにフォーマットしてみましょう(Alvar Lagerlöf氏が作成したRSCパーサーを使用)。
{
"type": "main",
"key": null,
"props": {
"children": {
"type": "h1",
"key": null,
"props": {
"children": "understandingreact.com"
}
}仮想DOMの構造が見えるでしょうか。main要素とh1要素、プレーンテキストノードもあります。props、特にReact特有の標準のchildren propsとして渡されているものも確認できます。
ここでは単純化した例を用いて説明していますが、フォーマットの要素はこれだけではありません。また、メタフレームワークを使用するとさらに多くの要素が追加されます。例えば、「Flight」を表す「f:」など、ツリーに追加するものを表す識別子などです。しかし、ここで必要な理解を得るためには単純化した例で十分です。
シリアライズのフォーマットはReactが提供していますが、Payloadを作成し、クライアントに送信する作業はメタフレームワーク(この場合はNext.js)が行う必要があります。
例えば、Next.jsはコードベースにgenerateDynamicRSCPayloadという関数があります。
メタフレームワークは、Payloadが確実に生成され、クライアントに送信されるようにします。Payloadのおかげで、Reactはクライアント上で正確な仮想DOMを構築し、差分検出処理を行うことができます。
メタフレームワークとサーバーレンダリング
先ほど、RSCからHTMLのレンダリングを行うことは「可能」だと話しました。そのように言ったのは、それが任意だからです。つまり、RSCからHTMLをレンダリングするかどうかはメタフレームワーク次第です。とは言え、そうすることは理にかなっています。
後で話すように、「体感パフォーマンス」は重要な指標です。すでにサーバー上でコードを実行していて、HTMLをストリーミングにより返せる場合、そうするべきです。なぜなら、ブラウザがそのHTMLを素早くレンダリングし、ユーザーの体感パフォーマンスが向上するからです。
メタフレームワークが遅いと感じられれば、誰も使いません。したがって、RSCを実装するReactのメタフレームワークは、古典的サーバーレンダリングとReactサーバーレンダリングの両方を行う必要があります。
古典的なサーバーレンダリング(HTMLを生成)ではページのレンダリング(ブラウザによる描画)が速く、Reactスタイルのサーバーレンダリング(RSC Payload)では後で行われるステートフルな更新のための仮想DOMが得られます。
したがって、実際にはRSCは「二重データ問題」を引き起こします。サーバーから同じ情報をHTMLとPayloadという2つの異なる形式で同時に送ることになります。これらはDOM(HTML)と仮想DOM(Payload)を即座に構築するために必要な情報です。
以下の図をご覧ください。
例では、Next.jsがHTMLを返し、ブラウザはそれをもとにDOMを構築します。
<main>
<h1>understandingreact.com</h1>
</main>さらにPayloadも返し、Reactはそれをもとに仮想DOMを構築します。
{
"type": "main",
"key": null,
"props": {
"children": {
"type": "h1",
"key": null,
"props": {
"children": "understandingreact.com"
}
}HTMLを送ることで、ブラウザがページを素早くレンダリングすることができます。ユーザーの画面には、ページが直ちに表示されます。また、Payloadを送ることで、Reactがページをインタラクティブにするために必要な作業を完了することができます。
このデータの重複に伴うコストは、サーバーがレスポンスを送る前に使う圧縮アルゴリズム(gzipなど)によって相殺できるという意見もあります。しかし、HTMLとJSONのようなPayloadは形式が異なるため、繰り返しの部分はあいまいになってしまい、帯域幅には二重データによる明らかな影響が生じます。
抽象化にはコストが伴います。ここでのコストは同じ情報を2回送る必要があることです。
これらのことを踏まえると、「レンダリング」の定義は全部で5つになります。
none
レンダー【render】 【動詞】 /réndər/レンダリング
- (古典的クライアントサイド)DOMとCSSOMをもとにレイアウトを計算し、画面にピクセルを描画すること。
- (Reactクライアントサイド)仮想DOMを構築して更新するために関数コンポーネントを実行すること。
- (古典的サーバーサイド)DOMを構築するためにクライアントに送信するHTMLを生成すること。
- (ReactサーバーサイドSSR)DOMを構築するためにクライアントに送信するHTMLを生成するために関数コンポーネントを実行すること。
- (ReactサーバーサイドRSC)仮想DOMを構築し、更新するためにクライアントに送るFlight(Payload)データを生成するために関数コンポーネントを実行すること。
Reactの定義に共通する類似点にお気づきでしょうか。Reactでは、レンダリングは常に「関数コンポーネントの実行」を意味し、Client ComponentsとServer Componentsはいずれも仮想DOMの構築と更新に必要なものを提供します。
Streams、Suspense、RSC
アプリケーションを構築する際にはパフォーマンスが常に懸念点となります。しかし、パフォーマンスには2種類あります。実際のパフォーマンスと体感パフォーマンスです。
HTTPとブラウザは、両方のパフォーマンスを改善する方法として、長年ストリーミングをサポートしてきました。NodeJSのStream APIや、ブラウザのStreams API(特に、ブラウザのReadableStreamオブジェクト)などです。
React(およびRSCをサポートしたいメタフレームワーク)は、これらのコアテクノロジーを利用してHTMLとPayload両方のデータをストリーミングします。ストリーミングとは、「チャンク」と呼ばれる少量のデータに分けて送信することを意味します。クライアントは、その少量のデータを受け取ったものから順に処理することができます。 したがって、ストリーミングの場合は「何を送ったか」ではなく、「一定時間内に何を送ったか」が問題となります。
ブラウザは、ネットワークを介したHTMLのストリーミングに対応できるよう設計されています。ストリーミングで送られてくるHTMLを受け取りながらページのレンダリング(配置と描画)を行います。
同様に、Reactは後に解決してRSC PayloadデータになるPromiseを受け入れます。例えば、Next.jsはクライアント上にReadableStreamを設定し、サーバーからのストリームを読み込み、受け取ったものからReactに渡します。サーバーレンダリングに対するReactの全体的なアプローチとしては、必要な場所にコンテンツをストリーミングで送る方式が中心となっています。
実際、Flight形式自体に未完了の処理を示すマーカーが含まれています。Promiseや遅延読み込みなどです。
例えば、サーバーコンポーネントをasync関数として設定し、タイマーを待つとします。
// components/Delayed.js
async function delay(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
export default async function DelayedMessage() {
await delay(5000); // 2 second delay
return (
<p>This message was loaded after a 5 second delay!</p>
);
}
// page.js
import DelayedMessage from "./components/DelayedMessage";
export default function Home() {
return (
<main>
<h1>understandingreact.com</h1>
<DelayedMessage />
</main>
);
}async関数はPromiseを返します。その結果、Payloadは以下のようになります。
{
"type": "main",
"key": null,
"props": {
"children": [
{
"type": "h1",
"key": null,
"props": {
"children": "understandingreact.com"
}
},
{
"$$type": "reference",
"id": "d",
"identifier": "L",
"type": "Lazy node"
}
]
}
}DelayedMessageコンポーネントがあるべき場所が、特別な識別子”L”でマーキングされている点に注目してください。これは、後でコンテンツが挿入される場所を示しているのです。
このコードを実行すると、遅延メッセージだけでなく、ページ全体が読み込まれるのに5秒かかります。
これは、Reactがクライアント向けに設計された特別なSuspense機能を使用してPromiseや遅延読み込みに対処するためです。コンポーネントを更新してSuspenseを使うようにすると、以下のようになります。
import DelayedMessage from "./components/DelayedMessage";
import { Suspense } from "react";
export default function Home() {
return (
<main>
<h1>understandingreact.com</h1>
<Suspense fallback={<p>Loading...</p>}>
<DelayedMessage />
</Suspense>
</main>
);
}この状態でページを実行すると、最初にフォールバックが表示され、遅れているメッセージが5秒後に表示されます。しかし、このコンポーネントがまだサーバー上で実行されていることに注目してください。どうすればサーバー上でSuspenseを使えるのでしょうか。使えません。関数から返されたPayloadをクライアント上で処理すると、境界を含む仮想DOMが構築されます。
Payloadは以下のようになります。
{
"type": "main",
"key": null,
"props": {
"children": [
{
"type": "h1",
"key": null,
"props": {
"children": "understandingreact.com"
}
},
{
"type": {
"$$type": "reference",
"id": "d",
"identifier": "",
"type": "Reference"
},
"key": null,
"props": {
"fallback": {
"type": "p",
"key": null,
"props": {
"children": "Loading..."
}
},
"children": {
"$$type": "reference",
"id": "e",
"identifier": "L",
"type": "Lazy node"
}
}
}
}
}フォールバック(props)と、Promiseが解決した後で読み込まれるもの(「遅延ノード(Lazy node)」、この場合はDelayedMessage)がいずれも含まれていることに注目してください。
Payloadは、チャンク化してストリーミングするとともに、Promiseが後で解決される仮想DOMの場所を参照します。そうすることで、Reactと、RSCをサポートするメタフレームワークは、最短時間でUIを表示し、実際のパフォーマンスとユーザーの体感パフォーマンスのいずれも改善しようとしています。
しかし、ストリーミングされたFlightデータはどこに送られるのでしょうか。Reactコードベース内のどこかであるはずです。
ReactにPayloadを渡す
RSCをサポートするために、ReactはFlight形式(文字列)を受け取り、parseModelStringなどの関数でReact要素に変換する機能をコードベースに追加しました。
適切なデータを送信し、これらのReact APIを実行するかどうかはRSCをサポートするメタフレームワーク次第です。
例えば、Next.jsの場合は、アプリにラッピングコンポーネントを追加し、そこにPayloadデータをストリーミングにより送信します。
これは以下のようになります。
<ServerRoot>
<AppRouter
actionQueue={actionQueue}
globalErrorComponentAndStyles={initialRSCPayload.G}
assetPrefix={initialRSCPayload.p}
/>
</ServerRoot>Next.jsは、コンポーネントツリーのAppRouterの上に、ServerRootというコンポーネントを追加します。そこからAppRouterにRSC Payloadデータをストリーミングします。
そのデータは、最終的にReactのPromiseベースのAPI(Flight形式を受け取るためのAPI)にストリーミングされます。
このように、ReactはPayloadをもとに仮想DOMを構築するためのAPIを提供し、Next.js(またはRSCをサポートするメタフレームワーク)には、サーバー上でコンポーネントが実行された後、そのデータをReactに渡す独自の仕組みが備わっています。
順不同ストリーミング
ストリーミングについて話すべき点は他にもあります。異なるコンポーネントの実行が異なるタイミングで完了する場合があります。チャンク化されたPayloadがストリーミングされてきたとき、Reactは仮想DOM(およびDOM)のどこにデータを置くべきかをどのようにして判断しているのでしょうか。
DelayedMessageコンポーネントを使用したDOMを再び見てみると、最初は以下のようになっています。
<main>
<h1>understandingreact.com</h1>
<!--$?-->
<template id="B:0"></template>
<p>Loading...</p>
<!--/$-->
</main>Reactは、特殊なIDが設定されたtemplateのようなプレースホルダーと、Suspenseが待っているPromiseが解決した時点でのコンテンツの挿入先を記載したHTMLコメントを残します。
フォールバックはDOMの中にありますが、Promiseが解決すると新しいJavaScriptがページにストリーミングされてきます。
$RC = function(b, c, e) {
c = document.getElementById(c);
c.parentNode.removeChild(c);
var a = document.getElementById(b);
if (a) {
b = a.previousSibling;
if (e)
b.data = "$!",
a.setAttribute("data-dgst", e);
else {
e = b.parentNode;
a = b.nextSibling;
var f = 0;
do {
if (a && 8 === a.nodeType) {
var d = a.data;
if ("/$" === d)
if (0 === f)
break;
else
f--;
else
"$" !== d && "$?" !== d && "$!" !== d || f++
}
d = a.nextSibling;
e.removeChild(a);
a = d
} while (a);
for (; c.firstChild; )
e.insertBefore(c.firstChild, a);
b.data = "$"
}
b._reactRetry && b._reactRetry()
}
}
;
$RC("B:0", "S:0")このコードは、Promiseの解決後に新たに作成されたDOMのコンテンツを、プレースホルダーが残されていた適切な場所に挿入し、プレースホルダーとフォールバックを削除します。
このDOM操作コードが実行された後、DOMは以下のようになります。
<main>
<h1>understandingreact.com</h1>
<!--$-->
<p>This message was loaded after a 5 second delay!</p>
<!--/$-->
</main>これを順不同ストリーミングといいます。これは単に、ストリーミングされてきたコンテンツを、先に完了する他のコンポーネントより前の場所であっても、仮想DOM/DOMツリーの所定の場所に挿入することを意味します。
そうすることで、特定のコンポーネントの実行に時間がかかったとしても、その完了を待たずにUIを更新し、他のコンポーネントの結果を反映することができます。
しかし、ここまではServer Components についてしか見ていません。デベロッパーが何年も前から書いてきたコンポーネントについてはどうでしょうか。ブラウザ上で実行される関数であるClient Componentsはどうでしょうか。
それについて語るうえで欠かせないのが、RSCを支える縁の下の力持ちとも言えるバンドラです。
バンドラとインターリービング
昔から、Reactの基本的な考え方の一つとしてコンポーネントコンポジションが挙げられていました。DOMの構造を決める作業はさまざまな関数に分けて行い、各コンポーネントを親子関係によって組み合わせることができます。
RSCがこの基本的な考え方から大きく離れないようにするためには、Server ComponentsとClient Componentsをインターリーブ(混在させる)できなくてはいけません。Client Componentsは、Server Componentsの子になれる必要があります。これには、props(関数の引数)を渡せることも含みます。
実際これが何を意味するかというと、コンポーネント階層の中には、サーバー上で実行される関数と、クライアント上で実行される関数があるということです。しかし最終的には、どの関数も自らが生成するDOMコンテンツの構造と中身を計算します。
これを実現する役割を担うのがメタフレームワークとバンドラです。しかし、抽象化はコストを伴うことを忘れてはいけません。抽象化を利用するために特別なルールを学ばなくてはいけないことがコストであることも少なくありません。この場合、サーバーとクライアントの隔たりをある程度抽象化し、気にならないようにするには、抽象化の制限を破らないようルールに従う必要があるということです。
RSCのケースでは、考慮すべきインターリービングのシナリオが3つあります。ルールは、コンポーネントが実行される場所に応じて何を「インポート」できるかに関わるもので、指示やインポートを分析してまとめるバンドラとRSCがどのように連携するかに基づいています。
Client Components を Server Components にインポート
このインポートは可能です。それが可能であるのは理にかなっています。バンドラはインポートステートメントを見て、どのコードをバンドルに含め、どのコードがクライアントによってダウンロードされるかを判断します。
RSCも仮想DOMの構築に参加します。Client Componentコードがバンドルに含まれブラウザに渡されるため、ツリーに含まれるClient Componentsを参照することができます。
Reactコースへの登録ページにステートフルなCounterを追加してみましょう。
// components/Counter.js
'use client';
import { useState } from 'react';
export default function Counter() {
const [count, setCount] = useState(0);
return (
<section>
<p>{count}</p>
<button onClick={() => setCount(count + 1)}>
Enroll
</button>
</section>
);
}
// page.js
import Counter from "./components/Counter";
import DelayedMessage from "./components/DelayedMessage";
import { Suspense } from "react";
export default function Home() {
return (
<main>
<h1>understandingreact.com</h1>
<Counter />
<Suspense fallback={<p>Loading...</p>}>
<DelayedMessage />
</Suspense>
</main>
);
}ファイル上部にuse clientという指示があります。これはReactの機能ではありません。コンポーネントツリーの一部をクライアント上で実行する場合は、マーキングすることがデベロッパーの間では暗黙の了解になっています。
そのコンポーネントと、それにインポートされるコンポーネントが、Client Componentsとしてバンドルされます。
バンドラはuse clientの指示を確認し、そのコンポーネント(およびインポートされるコンポーネント)のコードをブラウザがダウンロードするバンドルに含めます。
Home RSCおよびDelayedMessage RSCはサーバー上で実行されるため、これらのコードはバンドルに含まれません。サーバーから送られるPayloadは以下のようになります。
{
"type": "main",
"key": null,
"props": {
"children": [
{
"type": "h1",
"key": null,
"props": {
"children": "understandingreact.com"
}
},
{
"type": {
"$$type": "reference",
"id": "d",
"identifier": "L",
"type": "Lazy node"
},
"key": null,
"props": {}
},
{
"type": {
"$$type": "reference",
"id": "e",
"identifier": "",
"type": "Reference"
},
"key": null,
"props": {
"fallback": {
"type": "p",
"key": null,
"props": {
"children": "Loading..."
}
},
"children": {
"$$type": "reference",
"id": "f",
"identifier": "L",
"type": "Lazy node"
}
}
}
]
}
}Client Componentが挿入される場所に「遅延読み込み(Lazy node)」のリファレンスが新たに追加されていることに注目してください。仮想DOMの当該部分は、そのClient Componentが実行されるときに分かります。つまり、Client Componentがサーバー上でレンダリング(フレームワークが対応している場合)されるか、ブラウザ上で実行されるときです。
もう一つ述べておきたいのが、Server ComponentからClient Componentにpropsを渡す場合、そのpropsはReactによってシリアライズする必要があるということです。
すでに見てきたように、propsはネットワークを介して送信されるPayloadに含まれます。つまり、データは全て文字列として渡し、クライアントのメモリ上でオブジェクトに復元する必要があるということです。
Client ComponentsへのServer Componentsのインポート
このインポートは認められません。サーバー上で実行されるコンポーネントを、ブラウザ上で実行されるコンポーネントにインポートすることはできません。
なぜかと言うと、バンドラがクライアントに送信するのはPayloadのみであり、RSC関数は送信するべきではないからです。したがって、インポートするコードはありません。バンドラはクライアントがダウンロードできるようにコードを含めることはないため、使用できるRSCコードはありません。
サーバーとクライアントの両方で実行可能な共有コンポーネントをインポートすることは可能です。しかし、Client Componentに共有コンポーネントをインポートする場合、そのコードはクライアントがダウンロードできるようバンドルされます。Server Componentに共有コンポーネントをインポートする場合はバンドルされません。
「間違ってServer Componentをインポートした場合、バンドラはそれが間違いだと分かるのか」と疑問に思うかもしれません。
これは妥当な疑問です。これはセキュリティ上の問題でもあります。ダウンロードされて他人の目に触れることを想定していないコードがServer Componentに含まれる場合、間違ってClient Componentにインポートし、バンドルされてしまうことがあるかもしれません。サーバー固有の機能(データベースへの接続など)が含まれる場合、ブラウザ上で実行することはできませんが、そのまま本番環境にリリースされてしまうと、データベースのアドレスなどの機密情報が漏洩する可能性があります。
Next.jsは対策として、コンポーネントに「サーバーのみ(server-only)」とマーキングできるようにしています。しかし、これは何かを忘れないように指に紐を結びつけておくようなものです。紐を結ぶのを忘れてしまうこともありえます。
他のメタフレームワークは、サーバーのコードがバンドルされ、クライアントに送信されないようにするより確実な方法を検討しています。
しかし、一度サーバーとクライアントの境界を抽象化してしまうと、その境界が存在すること自体忘れてしまう一定のリスクを受け入れることになります。
Server Componentsを子としてClient Componentsに渡す
これは可能です。これは興味深い、特殊なケースです。Server Componentsをchildren propsとしてClient Componentに渡すことはできます。これはインポートとは異なります。
Counter関数にchildrenを渡した場合、以下のようになります。
// components/Counter.js
'use client';
import { useState } from 'react';
export default function Counter({ children }) {
const [count, setCount] = useState(0);
return (
<section>
<p>{count}</p>
<button onClick={() => setCount(count + 1)}>
Enroll
</button>
{ children }
</section>
);
}
// page.js
import Counter from "./components/Counter";
import DelayedMessage from "./components/DelayedMessage";
import { Suspense } from "react";
export default function Home() {
return (
<main>
<h1>understandingreact.com</h1>
<Counter>
<p>Server Text</p>
</Counter>
<Suspense fallback={<p>Loading...</p>}>
<DelayedMessage />
</Suspense>
</main>
);
}Counter関数はクライアント上で実行され、このコンポーネントに渡された子(<p>Server Text</p>)はサーバー上で処理されますが、問題なく機能します。
なぜ機能するのかと言うと、実行するServer Componentコードではなく、仮想DOMツリーの一部(コードを実行した結果)を渡しているからです。
Payloadは以下のようになります。
{
"children": [
{
"type": "h1",
"key": null,
"props": {
"children": "understandingreact.com"
}
},
{
"type": {
"$$type": "reference",
"id": "d",
"identifier": "L",
"type": "Lazy node"
},
"key": null,
"props": {
"children": {
"type": "p",
"key": null,
"props": {
"children": "Server Text"
}
}
}
},
{
"type": {
"$$type": "reference",
"id": "e",
"identifier": "",
"type": "Reference"
},
"key": null,
"props": {
"fallback": {
"type": "p",
"key": null,
"props": {
"children": "Loading..."
}
},
"children": {
"$$type": "reference",
"id": "f",
"identifier": "L",
"type": "Lazy node"
}
}
}
]
}
}Payloadの"Server Text"の部分に注目してください。すでにpropsとしてClient Componentに渡されています。Client Componentで直接PayloadにJSXを書いたのと変わりません。
バンドラ:縁の下の力持ち
これらは全てある重要な点を示しています。React Server Componentsは、多くの点においてバンドラ機能だということです。
バンドラはコードを分析し、Client Componentsがバンドルに含まれていることを確認し、Client ComponentsへのリファレンスがPayloadに適切に含まれるようにします。
バンドラはReactに欠かせない存在です。Reactのコードベースを見ると、以下のようなフォルダがあります。
/react-server-dom-parcel
/react-server-dom-turbopack
/react-server-dom-webpack
//...and moreこれらのフォルダの中にはFlight関連のコードが含まれており、バンドルされたコードが適切に実行されるようにします。
バンドラがRSCにおいて脇役的な存在であるということは、他の方法も可能だということです。メタフレームワークは、Next.jsが使用するuse clientのアプローチを受け入れる必要はありません。例えば、TanStack Startは単に「JSXを返す」(Flight形式)関数としてRSCを実装しています。
Reactは、FlightデータのストリーミングというAPIを提供しています。メタフレームワークはバージョンアップを行い、そのAPIを工夫して使うことができます。
フックとRSC
サーバー上で実行することにはメリットもありますが、制約もあります。 Reactは、各要素の構造を仮想DOMに格納するだけではなく、stateを格納します。コンポーネントに以下のように書くとします。
const [counter, setCounter] = useState(0);そうすると、仮想DOMにおけるコンポーネントの場所に紐づけられた連結リスト上のノードにデータが置かれます。実際には、そのstateはクライアントのブラウザのメモリ上にあるJavaScriptオブジェクトの中にあります。
したがって、React Server Componentsは、その性質上これらのフックを利用できません。フックを利用できる環境で実行されていないのです。
つまり、RSCは「非インタラクティブ」だということです。Reactにおけるインタラクティビティとは、一般的にはクライアント側のReactによる再レンダリングを、stateの更新によってトリガーすることを意味します。
そのため、アプリのインタラクティブ機能が増えるにつれ、Server ComponentsをClient ComponentとServer Componentのコンポジションに組み替えるようになります。
useReducerやuseStateなどが必要な場合は、Client Componentが必要になります。
コンポーネントがどこで実行されるのかを念頭に置いておくと、フックを適切に使用する(または使用しない)ことができます。
ハイドレートするか否か
よく誤解される点について少しお話ししたいと思います。RSCはハイドレートするのか、という点についてです。
答えは否です。ハイドレーションとは、イベントをハンドラにフックできるよう仮想DOMを構築するために、実際の関数をクライアント上で再実行することです。
Reactでは、ボタンをクリックすると、そのイベントはDOMツリーの最上部にあるReactのルートまで送られ、どのコンポーネントがクリックを処理するかをReactが判断します(答えは、ボタンの作成に関わったコンポーネントです)。
したがって、Reactがイベントに適切に対応できるよう、仮想DOMと、クリックを処理するコードがなくてはいけません。 RSCは非インタラクティブです。少なくともReactの通常のアプローチでは、stateの設定も、クリックの処理も行いません。実行するためにコードをクライアントに送ることもないので、当然ながらハイドレートしません。
しかし、仮想DOMの構築には関わっています。ツリーの差分検出処理にも関わっています。ハイドレートしないからと言って、ハイドレーション時にツリー上に存在しないわけではありません。存在します。
再フェッチと差分検出
実際のアプリでは、ページの初回ローディングだけでなく、サーバーコンポーネントの再フェッチについても考える必要があるでしょう。
つまり、サーバーにコンポーネント(場合によっては新しいpropsを含む)を再実行するよう指示し、仮想DOMを更新するために新しいPayloadデータを送ってもらうということです。
例えば、RSCが生成したデータリストにページ番号を付けていく場合、ルートが/page/1か/page/2であるかによって、異なるデータセットを取得することが望まれます。
これはRSCの利点であり、おそらくメタフレームワークのルーターに組み込まれています。UIはサーバー上で計算されますが、メタフレームワークはページ全体を再度読み込む必要がありません。
RSCはその性質上、仮想DOMの定義をクライアントにストリーミングすることができ、Reactは通常どおりクライアント側で差分検出処理を行うことができます。つまり、ページを再度読み込む必要がなく、ページ上の他のstateも失われません。
この点において、RSCはサーバーレンダリングとクライアントレンダリングの両方の長所を提供できます。サーバー上で実行しながら、クライアント上で実行された場合と同じように更新することができます 。 RSCの仕組みについて説明しましたので、より直感的にご理解いただけるのではないかと思います。Reactはすでに仮想DOMの差分計算によってDOMを更新していますので、仮想DOMのデータをサーバーから取得できれば、Reactは通常の動作を行うことが可能です。
バンドルサイズに関する誤解
10年以上前から、使用するツールの仕組みを深く理解することの重要性を説いてきました。筆者のコースでは、一貫してこのテーマについて扱ってきました。
多くの生徒がこのアプローチの重要性を理解してくれていますが、「理論が多すぎる。実践から学べばいい」と不満を漏らす生徒もたまにいます。
しかし、使用するツールやライブラリ、フレームワークの仕組みを理解することの主な価値の一つが、正確な情報に基づき、アーキテクチャに関する効果的な判断ができることです。
例えば、Next.jsの世界ではRSCのメリットについて以前から誤解がありました。__next_f()関数について、Next.jsコードのリポジトリでは素晴らしい議論が繰り広げられています。
RSCを使い始めたデベロッパーは、ページ下部のscriptタグでこの関数に重複データが渡されていることに気づきました。なぜそこにこの関数があるのか疑問に感じ、無効にできないか尋ねるデベロッパーもいました。
この重複データは何でしょうか。そう、Payloadです。ストリーミングされてきた関数コールは、仮想DOMを作成するため、最終的にそのPayloadデータをReactに渡します。仕組みを理解していなければ、これはかなりショッキングなことでしょう。
問題は帯域幅の使用量が増えることであり、多くのデベロッパーがその点について不満を述べていました。ネットワークを介して送るデータ量が増えているのです。
なぜデベロッパー達は驚いたのでしょうか。当初、VercelはNext.jsのドキュメンテーションサイトでRSCについて次のように説明していました。

バンドルサイズ:Server Componentsでは、以前ならクライアントJavaScriptのバンドルサイズに影響するような大きな依存関係をサーバー上に残すことができます。クライアントはServer ComponentsのJavaScriptをダウンロードして解析し、実行する必要が一切ないため、これはインターネットの通信速度が遅い、あるいはデバイスの処理能力が低いユーザーにとって有益です。
「クライアントはServer ComponentsのJavaScriptをダウンロードして解析し、実行する必要が一切ない」という文言が誤解を招いたようです。これは実際には正しくありません。VercelはServer Componentsの実際のJavaScriptコードについて言っていたのですが、「一切」という言葉を使ってしまいました。
筆者はこれに関連し、VercelとSNS上で興味深い会話をしました。この会話が、後日文言が変更されるきっかけになったのかもしれません(文言を変更したVercelに感謝)。

パフォーマンス:Server Componentsは、パフォーマンスをベースラインから最適化する手段を提供します。例えば、Client Componentだけで構成されるアプリから始めた場合、UIの非インタラクティブ要素をServer Componentsに移動することで、クライアント側が必要なJavaScriptの量を減らすことができます。ブラウザがダウンロードして解析し、実行するクライアント側JavaScriptの量が減るため、これはインターネットの通信速度が遅い、あるいはデバイスの処理能力が低いユーザーにとって有益です。
新しい説明には、Server Componentsが「クライアント側が必要なJavaScriptの量を減らすことができる」と書いてあります。それは事実です。しかし、Payloadはある意味JavaScript、少なくとも、JavaScriptの関数に渡されるデータなので、JavaScriptの量を増やすこともあります。
デベロッパーたちが誤解していた重要な点は、バンドルサイズと帯域幅の使用量は同じではないということです。
Server Componentのコードはバンドルに含まれていないので、バンドルサイズは小さくなります。しかし、Payloadのデータは倍増しますので、データが大きいと(この記事のような長編のブログ記事など)節約できるバイト数以上のデータを送信することになります。
RSCはいつ使うべきか
では、RSCはいつ使うべきなのでしょうか。大抵の場合そうであるように、「状況次第」というのが正しい答えです。RSCの仕組みに関する正確なメンタルモデルが構築できていれば、適切なアーキテクチャを選択できるはずです。
筆者の場合、このような長編のブログ記事にはRSCを使用しません。帯域幅の使用量が多くなり、理にかなわないからです。コンテンツの多いサイトやアプリには、Astroなどを使用します。
一方、データベースへのアクセスが多く、ロジックが複雑な場合、Server Componentを使ってサーバーに処理させるかもしれません。大容量のJavaScriptライブラリを使用して比較的少量のコンテンツを作成する必要がある場合も同様です。バンドルとPayloadのトレードオフが価値に見合うようなら、RSCは理にかなっていると思います。
高度にインタラクティブなアプリを開発していて、頻繁にバージョンアップを行って機能を追加しているような場合も、Client Componentsを中心に運用し、クライアントとサーバー両方を使用するようなリファクタリングは極力控えると思います。
明確な使い方を推奨するには不確定要素があまりにも多すぎます。この記事を通じて試みたように、読者が正確な情報をもとに判断できるよう、理解を深める手助けをするのが筆者にできる精一杯のことです。
今後の展望
React Server Componentsの未来はどのようなものになるでしょうか。それは必ずしも明らかではありません。ReactはAPIを作り、メタフレームワークがそれを利用しています。
筆者の考えでは、TanStack Startが採用した、完全なServer Componentsではなく、仮想DOMを返す関数を用いるアプローチが普及すると思います。しかし、用途によってはNext.jsのアプローチも有効だと思います。
セキュリティとパフォーマンスも徐々に改善して欲しいと思います。例えば、仮想DOMのある枝が全てServer Componentsの場合、差分検出処理やハイドレーションを最適化することでその枝をスキップするようにできると思います。
もっと詳しく学びたい方へ
この記事がReact Server Componentsの理解を深める一助になれば幸いです。Reactの全てについて、このようにゼロから詳しく学びたい方は、筆者の完全版「Understanding React(Reactを理解する)」コースにぜひご登録ください。
27個のモジュールと、16.5時間の動画コンテンツを通じてReactのソースコードを詳しく学び、デベロッパーにとって最も有益なツールである正確なメンタルモデルを構築することができます。
それではまた!
]]>Next.jsプロジェクトをアップグレードする
Next.jsの従来のPages Routerから新しいApp Routerに移行しましょう。ここの移行により、アプリケーションのルーティング効率と柔軟性が向上します。App Routerは、ファイルシステムベースのルーティング機能が改善されたほか、React Server Componentsが導入されたことなどにより、開発体験を向上させます。
依存関係をチェックする
package.jsonファイルのバージョンが最新であることが重要です。依存関係をすべてチェックし、新しいApp Routerと互換性があることを確認しましょう。必要であればアップグレードしてください。この準備を行うことで、移行時に互換性の問題が発生するのを避けることができます。
依存関係はnpmを使用することで簡単にチェックできます。以下のコマンドを実行してください。
$ npm outdated
/appディレクトリを作成する
まずは、Next.jsプロジェクトのルートに新しい/appディレクトリを作成しましょう。App Routerのファイルやコンポーネントはすべてここに格納されます。
PagesフォルダからAppフォルダにファイルを移動する
サーバー上でレンダリングされるHTMLドキュメントは、/pages/_document.tsxファイルを使用してカスタマイズします。App Routerでは、/app/layout.tsxファイルがこの機能を担います。
-
/pages/_document.tsxの内容を/app/layout.tsxという新しいファイルにコピーします。 -
next/documentのインポートを削除し、<Html>、<Head>、<Main />の各コンポーネントを対応するHTMLコンポーネント(<html>、<head>、{children})に置き換えます。 -
<NextScript />コンポーネントを削除します。
ページをApp Routerに移行する
/pagesディレクトリにある各ページについて、対応するフォルダ構造を/appディレクトリに作成する必要があります。
-
ページのURLパスと一致するフォルダ構造を
/appに作成します。例えば、/pages/about.tsxにページがある場合、/app/about/page.tsxファイルを作成します。 -
page.tsxファイルに元のページコンポーネントの内容をコピーします。 -
ページコンポーネントがクライアントサイドの機能(Hooks、Browser APIなど)を使用する場合、ファイルの先頭に
use clientディレクティブを記述してラップする必要があります。
データフェッチをアップデートする
App Routerでは、Next.jsの従来のデータフェッチ方法(getStaticProps、getServerSideProps、getStaticPaths)は使用されません。その代わり、ページコンポーネント内で直接データをフェッチできます。
-
ページコンポーネント内に
getStaticProps、getServerSideProps、getStaticPathsのいずれかの関数がある場合は削除します。 -
JavaScript/TypeScriptの標準の非同期関数を使用し、ページコンポーネント内で直接データをフェッチします。
例1:データフェッチ
移行前(Pages Router)
// /pages/about.tsx
import { GetStaticProps } from 'next';
export const getStaticProps: GetStaticProps = async () => {
const data = await fetchSomeData();
return {
props: { data },
};
};
const AboutPage = ({ data }: { data: any }) => {
return (
<div>
<h1>About Page</h1>
<p>{data.message}</p>
</div>
);
};
export default AboutPage;移行後(App Router)
import { fetchSomeData } from '@/lib/data';
const AboutPage = async () => {
const data = await fetchSomeData();
return (
<div>
<h1>About Page</h1>
<p>{data.message}</p>
</div>
);
};
export default AboutPage;ルーティングのHooksを移行する
App Routerでは、Pages Routerで使用されていたものに代わる新しいルーティングのHooksが導入されます。
-
next/routerからuseRouter()を使用する代わりに、next/navigationからuseRouter()、usePathname()、useSearchParams()を使用します。 -
新しいHooksの
useRouter()は、pathnameとqueryのプロパティを返しません。代わりに、usePathname()とuseSearchParams()を使用します。
例2:ルーティングのHooksの移行
移行前(Pages Router)
// /pages/users/[id].tsx
import { useRouter } from 'next/router';
const UserPage = () => {
const { query } = useRouter();
const userId = query.id as string;
return (
<div>
<h1>User Page</h1>
<p>User ID: {userId}</p>
</div>
);
};
export default UserPage;移行後(App Router)
// /app/users/[id]/page.tsx
'use client';
import { usePathname, useSearchParams } from 'next/navigation';
const UserPage = () => {
const pathname = usePathname();
const searchParams = useSearchParams();
const userId = searchParams.get('id');
return (
<div>
<h1>User Page</h1>
<p>User ID: {userId}</p>
</div>
);
}
export default UserPage;エラーハンドリングをアップデートする
App Routerでは、Pages Routerとはエラーハンドリングのアプローチが異なります。
-
グローバルエラーのハンドリングについては、
pages/_error.jsファイルをapp/error.tsxに置き換えます。 -
特定のルートに関連するエラーの処理のためにページフォルダ内に個別の
error.tsxファイルを作成します。
例3:エラーハンドリングの移行
移行前(Pages Router)
// /pages/_error.js
import { NextPageContext } from 'next';
const ErrorPage = ({ statusCode }: { statusCode: number }) => {
return (
<div>
<h1>Error {statusCode}</h1>
<p>An error occurred on the server</p>
</div>
);
};
ErrorPage.getInitialProps = ({ res, err }: NextPageContext) => {
const statusCode = res ? res.statusCode : err ? err.statusCode : 404;
return { statusCode };
};
export default ErrorPage;移行後(App Router)
// /app/error.tsx
// エラーコンポーネントはClient Componentである必要があります!
'use client';
interface ErrorPageProps {
error: Error & { digest?: string }
reset: () => void;
}
const ErrorPage = ({ error, reset }: ErrorPageProps) => {
return (
<div>
<h1>Error</h1>
<p>{error.message}</p>
<button onClick={
// セグメントの再レンダリングにより復旧を試みます。
() => reset()
}>
Try again
</button>
</div>
);
};
export default ErrorPage;他の機能の移行
アプリケーションによっては、APIルートやミドルウェア、カスタムdocument/appコンポーネントなど他の機能も移行する必要があるかもしれません。これらの機能をApp Routerに移行する方法については、Next.jsのドキュメントをご覧ください。
テストと検証
移行が完了したら、アプリケーションのテストを行い、すべての機能が正常に動作することを確認しましょう。Pages RouterとApp Routerで挙動に違いが見られないか注意してみてください。
App RouterとPages Routerは同じNext.jsアプリケーション上に共存できるため、段階的な移行が可能です。App Routerがまだ対応していない特定のレガシー機能を残す必要がある場合などには、そうするとよいでしょう。

まとめ
Next.jsのPages Routerから新しいApp Routerに移行することで、アプリケーションのルーティング機能を強化し、柔軟性を高めることができます。依存関係をアップデートし、ファイル構造を再構築し、新しいデータフェッチとエラーハンドリングの方法に適応することで、App Routerの機能を最大限活用することができます。少し手間はかかりますが、アプリケーションの効率性と拡張性が向上することで明確なメリットが得られます。
]]>この記事では、Next.jsのプロジェクトにおける国際化対応(i18n)の設定方法について説明します。Next.jsが直接サポートしていない部分の課題を克服しながら、Pages Routerを使用してi18nを実装する方法と、output: exportを使用する方法について検討したいと思います。
none
国際化ルーティングは、Next.jsのルーティングレイヤーを使用しないためoutput: 'export'では実装できません。output: 'export'を使用しないHybrid Next.jsのアプリケーションは完全にサポートされています。
まず初めに、TypeScriptを使用してNext.js v14のプロジェクトを初期化しましょう。TypeScriptの代わりにJavaScriptを使用することもできます。どちらも問題なく使用できます。
NextJSプロジェクトの初期化
次のコマンドを実行してプロジェクトをセットアップしてください。。
`npx create-next-app@latest`設定中いくつか質問をされますが、好みで回答してください。筆者の場合はPages Routerを選択し、TypeScriptでsrcディレクトリを指定しました。
次に、next.config.jsファイルにoutput: "export"を追加します。

さらに、output: "export"の構成とは互換性がないためpagesディレクトリからapiフォルダを削除します。
i18nのインストールと設定
国際化対応では、next-translateパッケージを使用します。本来はoutput: exportに対応していませんが、ご心配なく。その点については後ほどサポートします。
まずはnext-translateパッケージをインストールしてください。
`npm i next-translate`プロジェクトのルートレベルにi18n.tsまたは.jsという名前のファイルを作成し、次のコードを挿入します。
import { I18nConfig } from "next-translate";
export const i18nConfig = {
locales: ["en", "es"],
defaultLocale: "en",
loader: false,
pages: {
"*": ["common"],
},
defaultNS: "common",
} satisfies I18nConfig;これがi18nのための基本構成になります。必要に応じて自由にカスタマイズしていただいて構いません。
次に、プロジェクトのルートレベルにlocalesフォルダを作成します。このフォルダには、各言語の翻訳ファイルが格納されます。

pagesディレクトリ内の_app.tsファイルに移動し、I18nProviderでComponentをラップします。
import "@/styles/globals.css";
import type { AppProps } from "next/app";
import I18nProvider from "next-translate/I18nProvider";
import { i18nConfig } from "../../i18n";
import commonES from "../../locales/es/common.json";
import commonEN from "../../locales/en/common.json";
const App = ({ Component, pageProps, router }: AppProps) => {
const lang = i18nConfig.locales.includes(router.query.locale as string)
? String(router.query.locale)
: i18nConfig.defaultLocale;
return (
<I18nProvider
lang={lang}
namespaces={{ common: lang === "es" ? commonES : commonEN }}
>
<Component {...pageProps} />
</I18nProvider>
);
};
export default App;この手順では以下を行いました。
I18nProviderでComponentをラップする。- localeというクエリパラメタに指定された文字列から言語を検出し、propsとして
I18nProviderに渡す。 - その言語を基に名前空間ファイルを定義する。
次に、src/hooksディレクトリにuseI18n.tsという名前のカスタムフックを作成し、そこに次のコードを挿入します。
import useTranslation from "next-translate/useTranslation";
import { i18nConfig } from "../../i18n";
interface IUseI18n {
namespace?: string;
}
export const useI18n = ({ namespace }: IUseI18n = {}) => {
const { t } = useTranslation(namespace ? namespace : i18nConfig.defaultNS);
return { t };
};このフックは、設定された名前空間またはデフォルトの名前空間をもとに翻訳を可能にします。
次に、pagesディレクトリ内のindex.tsxファイルを開き、次のコードを挿入します。
import { useI18n } from "@/hooks/useI18n";
export default function Home() {
const { t } = useI18n();
return (
<div>
<p>{t("greeting")}</p>
</div>
);
}そうすると、次のような文字が表示されます。

「Hurrah(やった!)」無事プロジェクトにi18nを設定できました。しかし、言語検出がまだ残っています。次はその部分を実装しましょう。
言語検出
先ほど見たように、ロケール値はrouter.queryから取得していました。
次に進むために、pagesディレクトリ内に[locale]という名前のフォルダを作成します。
ルートファイルは全てこのフォルダの中に格納されます。
[locale]フォルダの中にindex.tsxファイルを作成し、次のコードを挿入します。
import { useI18n } from "@/hooks/useI18n";
const Home = () => {
const { t } = useI18n();
return (
<div>
<p>{t("greeting")}</p>
</div>
);
};
export default Home;localhost:3000/enにアクセスするとコンテンツが英語で表示され、localhost:3000/esに変えるとスペイン語で表示されます。この機能はダイナミックルートともシームレスに統合します。
pagesフォルダは次のような構造になります。

では、next-language-detectorを使用して言語検出機能を実装し、選択した言語をキャッシュしましょう。 まずはnext-language-detectorをインストールします。
npm i next-language-detectorsrcディレクトリにlibという名前のフォルダを作成し、その中にlanguageDetector.tsという名前のファイルを作成します。ファイルを開き、次のコードを挿入します。
import nextLanguageDetector from "next-language-detector";
import { i18nConfig } from "../../i18n";
export const languageDetector = nextLanguageDetector({
supportedLngs: i18nConfig.locales,
fallbackLng: i18nConfig.defaultLocale,
});同じlibフォルダの中にredirect.tsxという名前のファイルを作成し、次のコードを挿入します。
import { useRouter } from "next/router";
import { useEffect } from "react";
import { languageDetector } from "./languageDetector";
export const useRedirect = (to?: string) => {
const router = useRouter();
const redirectPath = to || router.asPath;
// language detection
useEffect(() => {
const detectedLng = languageDetector.detect();
if (redirectPath.startsWith("/" + detectedLng) && router.route === "/404") {
// prevent endless loop
router.replace("/" + detectedLng + router.route);
return;
}
if (detectedLng && languageDetector.cache) {
languageDetector.cache(detectedLng);
}
router.replace("/" + detectedLng + redirectPath);
});
return <></>;
};次に、pagesディレクトリの中([locale]フォルダの外)にあるindex.tsxファイルを開き、既存のコードを次のコードに置き換えます。
import { useRedirect } from "@/lib/redirect";
const Redirect = () => {
useRedirect();
return <></>;
};
export default Redirect;これで、ロケールを指定せずにホームページにアクセスを試みたユーザーは、ロケールページにリダイレクトされるようになります。
しかし、[locale]フォルダ内の全てのルートについてリダイレクトページを作成するのはあまり効率的ではありません。したがって、ユーザーが言語を指定せずにページにアクセスしようとした場合に特定言語のルートにリダイレクトするLanguageWrapperを作成します。
まずはsrcディレクトリの中にwrappersという名前のフォルダを作成します。このフォルダの中にLanguageWrapper.tsxという名前のファイルを作成し、次のコードを挿入します。
import { ReactNode, useEffect } from "react";
import { useRouter } from "next/router";
import { languageDetector } from "@/lib/languageDetector";
import { i18nConfig } from "../../i18n";
interface LanguageWrapperProps {
children: ReactNode;
}
export const LanguageWrapper = ({ children }: LanguageWrapperProps) => {
const router = useRouter();
const detectedLng = languageDetector.detect();
useEffect(() => {
const {
query: { locale },
asPath,
isReady,
} = router;
// Check if the current route has accurate locale
if (isReady && !i18nConfig.locales.includes(String(locale))) {
if (asPath.startsWith("/" + detectedLng) && router.route === "/404") {
return;
}
if (detectedLng && languageDetector.cache) {
languageDetector.cache(detectedLng);
}
router.replace("/" + detectedLng + asPath);
}
}, [router, detectedLng]);
return (router.query.locale &&
i18nConfig.locales.includes(String(router.query.locale))) ||
router.asPath.includes(detectedLng ?? i18nConfig.defaultLocale) ? (
<>{children}</>
) : (
<p>Loading...</p>
);
};次に、_app.tsxファイルにLanguageWrapperを追加します。

あともう一息です。src/components/_sharedディレクトリにLink.tsxという名前のコンポーネントを作成し、次のコードを挿入します。
import { ReactNode } from "react";
import NextLink from "next/link";
import { useRouter } from "next/router";
interface LinkProps {
children: ReactNode;
skipLocaleHandling?: boolean;
locale?: string;
href: string;
target?: string;
}
export const Link = ({
children,
skipLocaleHandling,
target,
...rest
}: LinkProps) => {
const router = useRouter();
const locale = rest.locale || (router.query.locale as string) || "";
let href = rest.href || router.asPath;
if (href.indexOf("http") === 0) skipLocaleHandling = true;
if (locale && !skipLocaleHandling) {
href = href
? `/${locale}${href}`
: router.pathname.replace("[locale]", locale);
}
return (
<NextLink href={href} target={target}>
{children}
</NextLink>
);
};このプロジェクトでは、next/linkコンポーネントの代わりにこのLinkコンポーネントを使用します。
次に、hooksフォルダの中にuseRouteRedirect.tsという名前のファイルを作成し、次のコードを挿入します。
import { useRouter } from "next/router";
import { i18nConfig } from "../../i18n";
import { languageDetector } from "@/lib/languageDetector";
export const useRouteRedirect = () => {
const router = useRouter();
const redirect = (to: string, replace?: boolean) => {
const detectedLng = i18nConfig.locales.includes(String(router.query.locale))
? String(router.query.locale)
: languageDetector.detect();
if (to.startsWith("/" + detectedLng) && router.route === "/404") {
// prevent endless loop
router.replace("/" + detectedLng + router.route);
return;
}
if (detectedLng && languageDetector.cache) {
languageDetector.cache(detectedLng);
}
if (replace) {
router.replace("/" + detectedLng + to);
} else {
router.push("/" + detectedLng + to);
}
};
return { redirect };
};以下に示すとおり、router.pushとrouter.replaceの代わりにこのカスタムフックを使用します。

次に、src/componentsディレクトリの中にLanguageSwitcher.tsxコンポーネントを作成し、次のコードで特定の言語に切り替えられるようにします。
import { languageDetector } from "@/lib/languageDetector";
import { useRouter } from "next/router";
import Link from "next/link";
interface LanguageSwitcherProps {
locale: string;
href?: string;
asPath?: string;
}
export const LanguageSwitcher = ({
locale,
...rest
}: LanguageSwitcherProps) => {
const router = useRouter();
let href = rest.href || router.asPath;
let pName = router.pathname;
Object.keys(router.query).forEach((k) => {
if (k === "locale") {
pName = pName.replace(`[${k}]`, locale);
return;
}
pName = pName.replace(`[${k}]`, String(router.query[k]));
});
if (locale) {
href = rest.href ? `/${locale}${rest.href}` : pName;
}
return (
<Link
href={href}
onClick={() =>
languageDetector.cache ? languageDetector.cache(locale) : {}
}
>
<button style={{ fontSize: "small" }}>{locale}</button>
</Link>
);
};お疲れ様です!output: exportを使用してNext.jsのプロジェクトにi18nを無事実装できました。動的に名前空間を切り替える場合など、異なる名前空間から翻訳を読み込みたい場合は、I18nProviderコンポーネントの中の_app.tsxで各名前空間とそれぞれに対応する翻訳ファイルを定義する必要があるということを覚えておいてください。

ビルドを作成してからテストを行う前に、pagesディレクトリに404.tsxファイルを作成し、次のコードを挿入してください。
import { FC, useEffect, useState } from "react";
import { NextRouter, useRouter } from "next/router";
import { getRouteRegex } from "next/dist/shared/lib/router/utils/route-regex";
import { getClientBuildManifest } from "next/dist/client/route-loader";
import { parseRelativeUrl } from "next/dist/shared/lib/router/utils/parse-relative-url";
import { isDynamicRoute } from "next/dist/shared/lib/router/utils/is-dynamic";
import { removeTrailingSlash } from "next/dist/shared/lib/router/utils/remove-trailing-slash";
import { Link } from "@/components/_shared/Link";
async function getPageList() {
if (process.env.NODE_ENV === "production") {
const { sortedPages } = await getClientBuildManifest();
return sortedPages;
} else {
if (typeof window !== "undefined" && window.__BUILD_MANIFEST?.sortedPages) {
console.log(window.__BUILD_MANIFEST.sortedPages);
return window.__BUILD_MANIFEST.sortedPages;
}
}
return [];
}
async function getDoesLocationMatchPage(location: string) {
const pages = await getPageList();
let parsed = parseRelativeUrl(location);
let { pathname } = parsed;
return pathMatchesPage(pathname, pages);
}
function pathMatchesPage(pathname: string, pages: string[]) {
const cleanPathname = removeTrailingSlash(pathname);
if (pages.includes(cleanPathname)) {
return true;
}
const page = pages.find(
(page) => isDynamicRoute(page) && getRouteRegex(page).re.test(cleanPathname)
);
if (page) {
return true;
}
return false;
}
/**
* If both asPath and pathname are equal then it means that we
* are on the correct route it still doesnt exist
*/
function doesNeedsProcessing(router: NextRouter) {
const status = router.pathname !== router.asPath;
console.log("Does Needs Processing", router.asPath, status);
return status;
}
const Custom404 = () => {
const router = useRouter();
const [isNotFound, setIsNotFound] = useState(false);
const processLocationAndRedirect = async (router: NextRouter) => {
if (doesNeedsProcessing(router)) {
const targetIsValidPage = await getDoesLocationMatchPage(router.asPath);
if (targetIsValidPage) {
await router.replace(router.asPath);
return;
}
}
setIsNotFound(true);
};
useEffect(() => {
if (router.isReady) {
processLocationAndRedirect(router);
}
// eslint-disable-next-line react-hooks/exhaustive-deps
}, [router.isReady]);
if (!isNotFound) return null;
return (
<div className="fixed inset-0 flex justify-center items-center">
<div className="flex flex-col gap-10">
<h1>Custom 404 - Page Not Found</h1>
<Link href="/">
<button>Go to Home Page</button>
</Link>
</div>
</div>
);
};
export default Custom404;ダイナミックルートでページが見つからないエラーを解決するために、pagesディレクトリに404.tsxファイルを入れておく必要があります。
また、ビルド作成後にコードを実行するために、package.jsonファイルに次のコマンドを追加してください。
"preview": "serve out/ -p 3000"serveパッケージがない場合はインストールしてください。
npm i -D servenpm run buildとnpm run previewを実行した後、ポート3000でプロジェクトにアクセスできます。
コード全体はGitHubにあります。一部微調整を加えていますので、よろしければご覧ください。
何かお気づきの点やエラーなどがあればぜひコメントをください。喜んでサポートいたします。よろしくお願いします!