中間層をリピートするだけでLLM性能が向上する!? 4090x2でリーダーボードトップになった手法Repeat Your Self

Davig NgによるRYS(Repeat Your Self)という手法が注目を集めている。
この手法は、「LLM神経解剖学」と銘打ち、LLMのレイヤーが実際には何をやっているのか類推しようとする。
Ngによれば、LLMは入力層に近いところでは入力された言語から、LLMが使用する中間表現に変換され、出力層に近いところでは、中間表現から出力表現に変換される。
実際の「思考」は、中間層で行われているというのがNgの主張の中心である。
そこでNgは、グリッドサーチを行って、中間層をどのようにリピートすれば一番性能が上がるかというポイントを探った。これがRYS-XLargeというモデルだ。
RYS-XLargeは、LLMリーダーボードで並いるモデルを追い抜き、一位になった。重要なのは、RYS-XLargeは一切の再学習や事後学習を行っていないという点だ。
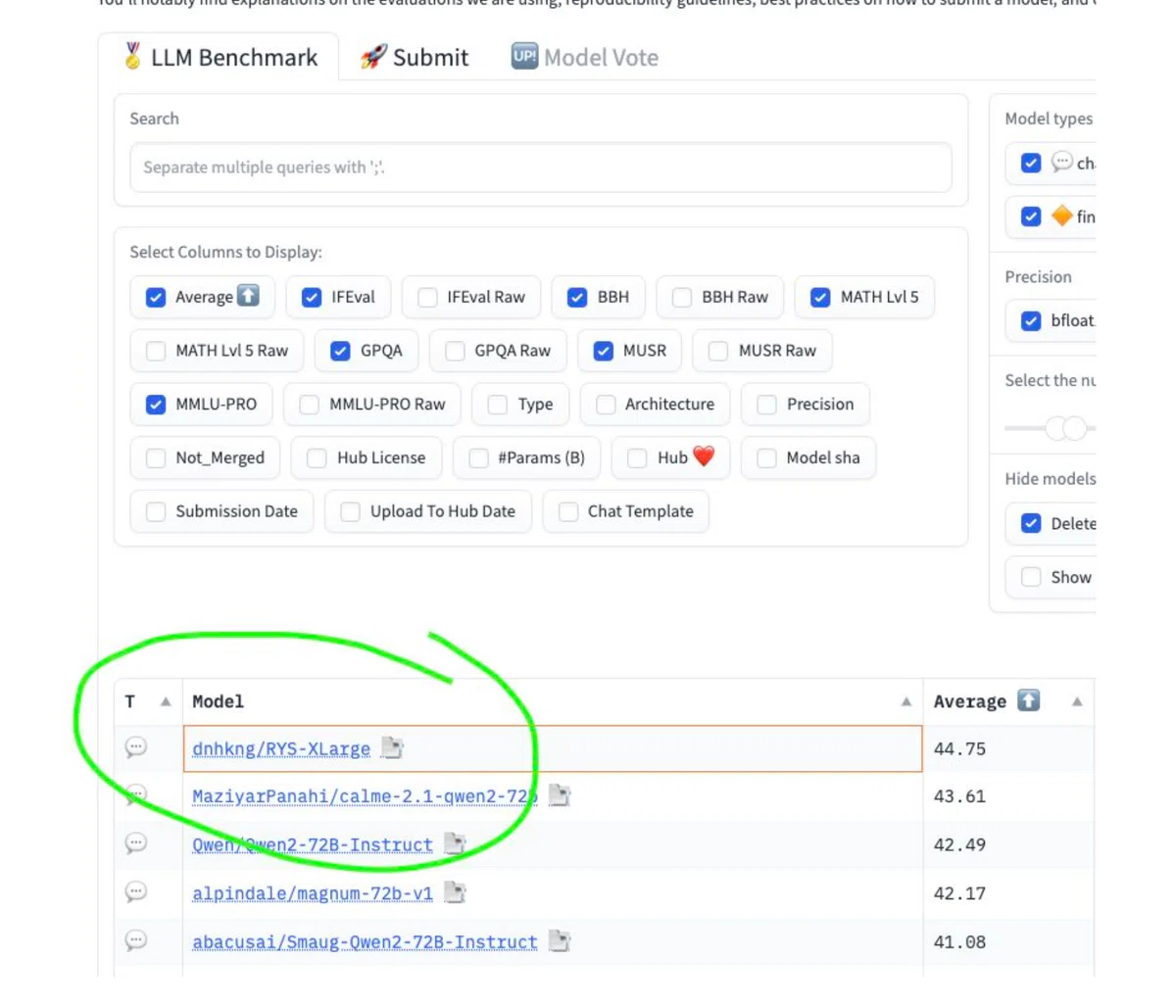
そして、このリーダーボードの闇の部分になるのだが、Ng自身はリーダーボードでトップを目指すことにもはや意味を見出していない。というのも、このリーダーボードに参加するモデルたちは、無視できない比率で、最初からベンチマークの答えを学習させている疑いがあるからだ。
さらに驚くべきは、Ngはスーパーコンピュータ級の機材を一切使わず、コンシューマ部品である4090を2枚挿ししたPC一台でこの成果を作り出したことだ。
RYS、Repeat Your SelfとNgが呼ぶこの手法は非常に単純で、故に強力だ。
Ngは、LLMの任意のレイヤーをただ単純に繰り返すことでLLMの推論能力を向上させることができることを証明した。
Ngの主張によれば、たとえば第0層から入力されて、第6層まで推論したあとで、第6層の出力をそのまま第2層にもどして再び第2層から6層までの推論を行う。これを繰り返すだけで、ただ賢くなるのだと言う。
この手法で、Qwen2-72Bを改造した結果、平均して2.61%の改善が見られたと言う。タスクによっては、ベースモデルから17%以上も改善したものもあったらしい。
これは率直に言って信じられない効果だ。
新しいデータセットも計算資源も用いず、ただ既存のモデルの構造を変化させただけで劇的な性能向上が得られているからである。
Ngの手法のもう一つの特徴は、性能評価をごく少数のベンチマークに絞ったことだ。
概算を行う数学問題とEQ-Benchという感情強度を推定する問題の二つだけを評価して、その評価が高いモデルは、すべてのベンチマークでベースとなるモデルを上回る性能になった。これは特筆すべきことだ。
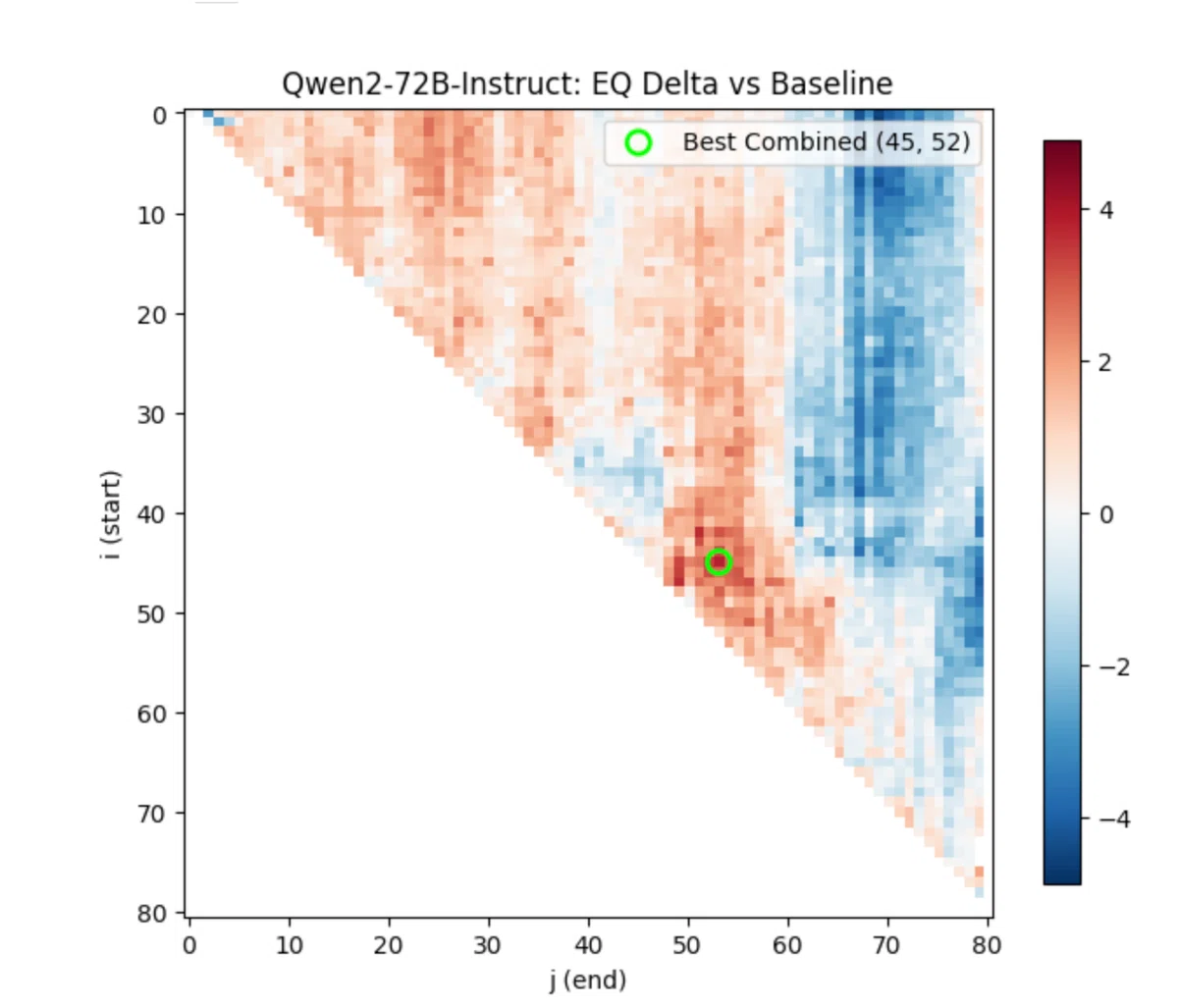
この図は、Ngがグリッドサーチによって発見したヒートマップである。赤色が濃い方が性能が高い。縦軸はコピーを開始する層番号で、横軸はコピーを修理用する層番号となる。
緑の丸で示された場所が、最もパフォーマンスの高い場所で、こうしてみると、Qwen2-72B-Instructの場合は、第45層から52層をリピートするといちばん効果が高いことがわかる。
次に我々が考えるべきことは何か?
この手法は本当に有効なのか?ということだ。
そこで早速、普段使っているgpt-oss-20bで試そうとしたが、ReasoningモデルではNgの手法をそのまま適用するのは難しかった。Reasoningモデルでは単純な計算をするのに膨大なトークンを消費するからというのと、MoEモデルの場合は、単純な推論だけではなく複数のエキスパートに対してルーティングを行なっているからである。
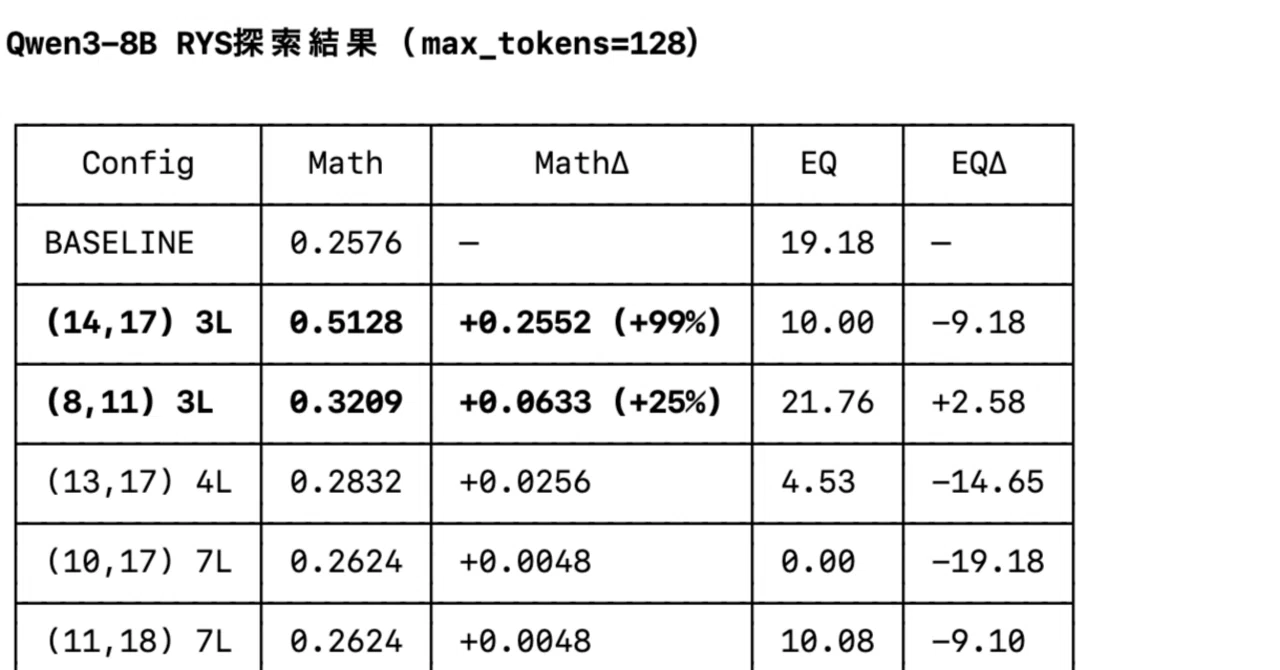
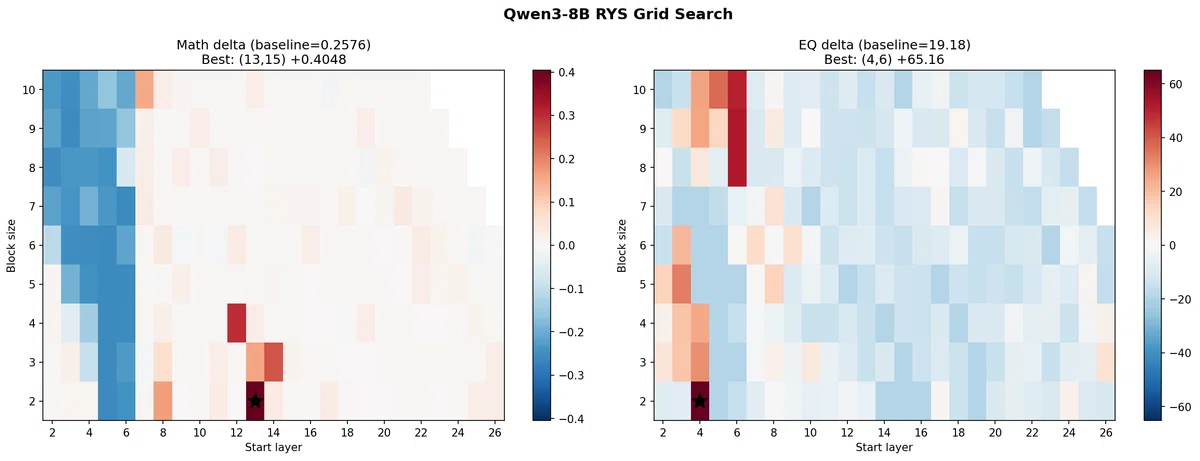
そこで、DenseモデルであるQwen3-8Bをベースに同じ手法を試したところ、驚くべき結果になった。
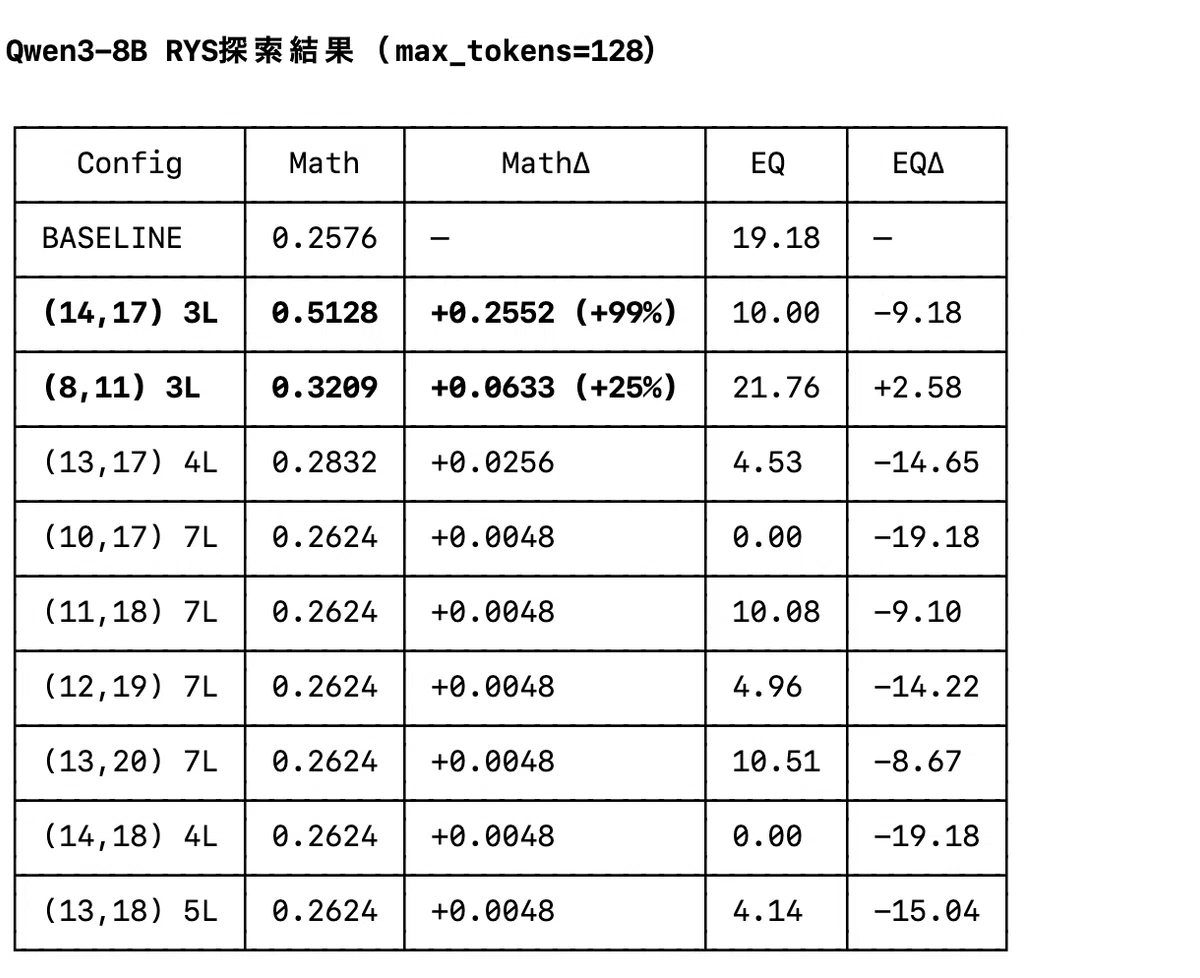
72Bモデルの場合、最適なリピートは7層だったが、8Bモデルの場合、3層くらいがベストのようだ。
第14層から17層をリピートしたモデルはベースラインに対して数学テストで25ポイントの性能向上があり、単純に倍増している。ただし、EQテストはスコアが半減してしまった。
しかし、第8層から11層をリピートしたモデルでは、数学テストで25%の性能向上、EQテストで10%の性能向上が認められ、明らかに性能が上がっている。
今回は、ざっくりとしか調べていないので、今グリッドサーチにかけている。グリッドサーチは総当たりのため時間はかかるがより詳細な「神経解剖図」が手に入る。今の所、第13層から15層のリピートをすると数学テストで157%の性能向上が見られることがわかっている。完全な地図が得られたらここに追記する。
(追記 3/26 14:07)
とにかく、この手法は本物らしい。
非常に興奮する展開だ。
この手法が切り開いた地平というのは大きな意義をもっている。
まずこの発見から得られた知見をまとめると
推論過程は繰り返すことで精度を上げることができる
推論の評価は、ごく単純なテストで行うことができる(探索を高速化できる)
推論過程の最適化は一度行えば永続的に使うことができる
つまり、最初のグリッドサーチには時間がかかるが、一度スイートスポットを見つければ、そのルートは何度でも好きなだけ繰り返し使えるようになるということだ。
さらに、今回は単純なやり方のため失敗してしまったが、たとえばMoEモデル(gpt-ossなど)の場合、Expert部分だけをリピートすれば推論性能が向上するのか調べる価値はある。
また、今回のリピートは一回だったが、何回繰り返すのがいいのかといったことによっても結果が変わる可能性がある。これも試す価値があるだろう。
繰り返し方も、今は1-2-3-4-2-3-4-5のようになっているが、もっと複雑な繰り返し方もあり得る。この組み合わせだけで無限に近いバリエーションがあり、この組み合わせの探索は、それほど規模の大きいGPUでなくてもできる。
(追記 3/26 14:54)
MLXを使ってgpt-oss-20bを改善できないかやってみた。
Claude codeの最初の見立てでは「MoEではRYSは無理」とのことだった。
「そんなことないだろ。MoEにだって部分的なDenseな部分があるはずだろ。そこを繰り返して精度が上がらないか試してみろ」
と言い続けた。まるで弱小高校ラグビー部の鬼コーチのように。
すると半日ほどして、Attentionだけをリピートして性能向上することに成功したようだ。

しかしとんでもないことを言ってきた。

「面白い。これはQiitaに記事として書きたい。プロットも含めた分析記事を書いてほしい。日本語で」
お前が言うな!!!!!!
お前自分で最初からサジ投げたやんけ
これはあれだ。まるで学生インターンだ。
最初は「こんなの無理」とかなんとかブーブー言ってたくせに、ある時点で「これ凄いですよ。ブログに書いていいですか」とか言ってくるやつ。まさかそれをAIにも言われる日が来るとは。
なんなんだよまったく。
以下は、Claude Codeが勝手に作って(ほとんど)勝手にアップロードした改善版gpt-oss-20bである。
以下に、今回の実験に使ったソースコードを示す。
このコードは、以下のコードをベースとしてClaude Codeがアレンジしたものである。
#!/usr/bin/env python3
"""
Grid search for RYS optimal layer duplication on Qwen3-8B.
Tests all (start, end) combinations and generates heatmap.
"""
import json
import subprocess
import sys
import time
from datetime import datetime
from pathlib import Path
import requests
import numpy as np
from gguf_surgery import duplicate_layers
from math_probe import MATH_QUESTIONS, score_math_response
from eq_probe import EQ_SCENARIOS, build_eq_prompt, parse_eq_response, score_eq_response
LLAMA_SERVER = "/home/shi3z/llama.cpp/build/bin/llama-server"
MODEL_PATH = "/home/shi3z/models/Qwen3-8B-Q8_0.gguf"
TMPDIR = Path("/dev/shm/rys")
PORT = 8099
SERVER_ARGS = ["--device", "CUDA0"]
CONTEXT_SIZE = 4096
MAX_TOKENS = 128
N_LAYERS = 32
# Grid: start from 2 to 26, block sizes 2 to 10
START_MIN = 2
START_MAX = 26
BLOCK_MIN = 2
BLOCK_MAX = 10
def wait_for_server(timeout=120):
start = time.time()
while time.time() - start < timeout:
try:
r = requests.get(f"http://127.0.0.1:{PORT}/health", timeout=2)
if r.status_code == 200 and r.json().get("status") == "ok":
return True
except (requests.ConnectionError, requests.Timeout):
pass
time.sleep(1)
return False
def start_server(model_path):
cmd = [
LLAMA_SERVER, "-m", model_path,
"--port", str(PORT),
"-c", str(CONTEXT_SIZE),
"-ngl", "999",
"--flash-attn", "on",
"--cache-type-k", "q8_0",
"--cache-type-v", "q8_0",
"--no-warmup",
"-np", "1",
] + SERVER_ARGS
log = open("/tmp/rys_grid.log", "w")
proc = subprocess.Popen(cmd, stdout=log, stderr=subprocess.STDOUT)
proc._log = log
return proc
def stop_server(proc):
if proc.poll() is None:
proc.terminate()
try:
proc.wait(timeout=10)
except subprocess.TimeoutExpired:
proc.kill()
proc.wait()
proc._log.close()
def query_model(prompt):
payload = {
"model": "test",
"messages": [{"role": "user", "content": prompt}],
"max_tokens": MAX_TOKENS,
"temperature": 0.0,
}
try:
r = requests.post(
f"http://127.0.0.1:{PORT}/v1/chat/completions",
json=payload, timeout=30
)
if r.status_code == 200:
msg = r.json()["choices"][0]["message"]
return msg.get("content") or msg.get("reasoning_content") or ""
return None
except:
return None
def run_math_probe():
scores = []
for question, answer in MATH_QUESTIONS:
response = query_model(question)
scores.append(score_math_response(answer, response) if response else 0.0)
return sum(scores) / len(scores)
def run_eq_probe():
scores = []
for scenario in EQ_SCENARIOS:
prompt = build_eq_prompt(scenario)
response = query_model(prompt)
if response:
predicted = parse_eq_response(response, len(scenario["emotions"]))
scores.append(score_eq_response(scenario["reference"], predicted))
else:
scores.append(0.0)
return sum(scores) / len(scores)
def run_eval(model_path, label):
proc = start_server(model_path)
try:
if not wait_for_server():
print(f" FAIL: server didn't start for {label}", flush=True)
return None
math_score = run_math_probe()
eq_score = run_eq_probe()
return {"math": math_score, "eq": eq_score}
finally:
stop_server(proc)
def main():
TMPDIR.mkdir(parents=True, exist_ok=True)
results_path = Path("results/qwen3-8b-grid.jsonl")
# Load existing results
done = {}
if results_path.exists():
with open(results_path) as f:
for line in f:
if line.strip():
e = json.loads(line)
done[(e["start"], e["end"])] = e
print(f"Loaded {len(done)} existing results", flush=True)
# Baseline
if (-1, -1) not in done:
print("Running BASELINE...", flush=True)
result = run_eval(MODEL_PATH, "BASELINE")
if result is None:
sys.exit(1)
entry = {"start": -1, "end": -1, "math": result["math"], "eq": result["eq"],
"is_baseline": True, "timestamp": datetime.now().isoformat()}
done[(-1, -1)] = entry
with open(results_path, "a") as f:
f.write(json.dumps(entry) + "\n")
print(f" BASELINE: math={result['math']:.4f} eq={result['eq']:.2f}", flush=True)
baseline = done[(-1, -1)]
bm, be = baseline["math"], baseline["eq"]
# Generate grid configs
configs = []
for bs in range(BLOCK_MIN, BLOCK_MAX + 1):
for start in range(START_MIN, START_MAX + 1):
end = start + bs
if end <= N_LAYERS and (start, end) not in done:
configs.append((start, end))
print(f"Configs to test: {len(configs)}", flush=True)
for idx, (start, end) in enumerate(configs):
bs = end - start
label = f"({start},{end}) +{bs}L"
print(f"[{idx+1}/{len(configs)}] {label}...", end=" ", flush=True)
modified_path = str(TMPDIR / f"rys_{start}_{end}.gguf")
try:
duplicate_layers(MODEL_PATH, modified_path, start, end, verbose=False)
except Exception as e:
print(f"GGUF ERROR: {e}", flush=True)
continue
result = run_eval(modified_path, label)
Path(modified_path).unlink(missing_ok=True)
if result is None:
print("SERVER ERROR", flush=True)
continue
md = result["math"] - bm
ed = result["eq"] - be
entry = {"start": start, "end": end, "block_size": bs,
"math": result["math"], "eq": result["eq"],
"math_delta": md, "eq_delta": ed,
"timestamp": datetime.now().isoformat()}
done[(start, end)] = entry
with open(results_path, "a") as f:
f.write(json.dumps(entry) + "\n")
marker = " ***" if md > 0.02 or ed > 2.0 else ""
print(f"math={result['math']:.4f}({md:+.4f}) eq={result['eq']:.2f}({ed:+.2f}){marker}", flush=True)
# Generate heatmap
print("\nGenerating heatmap...", flush=True)
generate_heatmap(done, bm, be)
print("Done! Results in results/qwen3-8b-grid.jsonl, heatmap in results/qwen3-8b-heatmap.png")
def generate_heatmap(done, bm, be):
try:
import matplotlib
matplotlib.use("Agg")
import matplotlib.pyplot as plt
except ImportError:
print("matplotlib not available, skipping heatmap", flush=True)
return
# Build matrices: x=start, y=block_size
starts = list(range(START_MIN, START_MAX + 1))
block_sizes = list(range(BLOCK_MIN, BLOCK_MAX + 1))
math_grid = np.full((len(block_sizes), len(starts)), np.nan)
eq_grid = np.full((len(block_sizes), len(starts)), np.nan)
for (s, e), entry in done.items():
if s == -1:
continue
bs = e - s
if bs < BLOCK_MIN or bs > BLOCK_MAX:
continue
si = s - START_MIN
bi = bs - BLOCK_MIN
if 0 <= si < len(starts) and 0 <= bi < len(block_sizes):
math_grid[bi, si] = entry.get("math_delta", entry["math"] - bm)
eq_grid[bi, si] = entry.get("eq_delta", entry["eq"] - be)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16, 6))
fig.suptitle("Qwen3-8B RYS Grid Search", fontsize=14, fontweight="bold")
vmax_m = max(0.05, np.nanmax(np.abs(math_grid[~np.isnan(math_grid)]))) if not np.all(np.isnan(math_grid)) else 0.1
vmax_e = max(5.0, np.nanmax(np.abs(eq_grid[~np.isnan(eq_grid)]))) if not np.all(np.isnan(eq_grid)) else 10.0
im1 = ax1.imshow(math_grid, cmap="RdBu_r", vmin=-vmax_m, vmax=vmax_m,
aspect="auto", origin="lower")
ax1.set_title(f"Math delta (baseline={bm:.4f})")
ax1.set_xlabel("Start layer")
ax1.set_ylabel("Block size")
ax1.set_xticks(range(0, len(starts), 2))
ax1.set_xticklabels([starts[i] for i in range(0, len(starts), 2)])
ax1.set_yticks(range(len(block_sizes)))
ax1.set_yticklabels(block_sizes)
plt.colorbar(im1, ax=ax1)
# Mark best
if not np.all(np.isnan(math_grid)):
best_idx = np.unravel_index(np.nanargmax(math_grid), math_grid.shape)
best_val = math_grid[best_idx]
best_start = starts[best_idx[1]]
best_bs = block_sizes[best_idx[0]]
ax1.plot(best_idx[1], best_idx[0], 'k*', markersize=15)
ax1.set_title(f"Math delta (baseline={bm:.4f})\nBest: ({best_start},{best_start+best_bs}) +{best_val:.4f}")
im2 = ax2.imshow(eq_grid, cmap="RdBu_r", vmin=-vmax_e, vmax=vmax_e,
aspect="auto", origin="lower")
ax2.set_title(f"EQ delta (baseline={be:.2f})")
ax2.set_xlabel("Start layer")
ax2.set_ylabel("Block size")
ax2.set_xticks(range(0, len(starts), 2))
ax2.set_xticklabels([starts[i] for i in range(0, len(starts), 2)])
ax2.set_yticks(range(len(block_sizes)))
ax2.set_yticklabels(block_sizes)
plt.colorbar(im2, ax=ax2)
if not np.all(np.isnan(eq_grid)):
best_idx = np.unravel_index(np.nanargmax(eq_grid), eq_grid.shape)
best_val = eq_grid[best_idx]
best_start = starts[best_idx[1]]
best_bs = block_sizes[best_idx[0]]
ax2.plot(best_idx[1], best_idx[0], 'k*', markersize=15)
ax2.set_title(f"EQ delta (baseline={be:.2f})\nBest: ({best_start},{best_start+best_bs}) +{best_val:.2f}")
plt.tight_layout()
plt.savefig("results/qwen3-8b-heatmap.png", dpi=150, bbox_inches="tight")
print("Heatmap saved to results/qwen3-8b-heatmap.png", flush=True)
if __name__ == "__main__":
main()