【Tips】朝食を食べながら論文を聞く:NotebookLMで変わるインプット習慣

本題に入る前に、現役研究者たちの悲鳴をお見せしよう。
研究者や学生、あるいは大学にいるといろいろ忙しくて、大学教員自身が研究するには、なかなかの強い意志が必要。そして研究は空き時間にするものに成り下がっていて、放っておくとその空き時間さえどんどん他の用事で埋まってしまう。そこで今年の目標は、先に研究時間をスケジュールに入れてしまう。週に丸一日は研究の時間を作る。夏休みの宿題をちゃんと終わらせるみたいな話だが、こういうことにも決心が必要なのも今の大学。
私が大学の助教だったころ教授は実験のために、朝4時に来てたなで、9時まで実験してそのあとは17時で帰るまでデスクワークをされていた
9時~17時でデスクワークが済んでいたのはむしろ昔だからで、種々の業務が膨大に肥大化した現在では、9時~17時のデスクワークでは全然終わらないという話も・・
増えてゆく雑務、増えてゆく論文。
研究者や学生、あるいは最新の知見を要するビジネスパーソン。彼らは例にもれず多忙である。多忙もいいところだ…。
さて、彼らに課せられた試練は何だろう。
"限られた時間のなかで膨大な文献を把握すること"ではなかろうか。
論文を読むのはしんどい。めちゃしんどい。しんどすぎてシンドラーがリスト作るのやめるレベル。長時間の視覚的な情報処理は我々を疲弊させる。10本気になる論文があったからといって、10本全部なんて読んでられない…。読んだとて、自分に研究に使えるかは別の話だし…。
そこで活用したいのがAIだ。GoogleのAIツール『NotebookLM』を活用すれば、朝食等の時間を「聴覚学習による論文インプット」へと転換することができるのである。
本稿ではGoogle Scholarアラートによる高精度な情報収集と、Google NotebookLMによるAI主導の音声合成(Audio Overview)を統合した「聴覚的学習ワークフロー」を提案し、朝食等の時間を「聴覚学習による論文インプット」へと転換する手法を提案する。
1. Google Scholarアラートで新着論文を知る
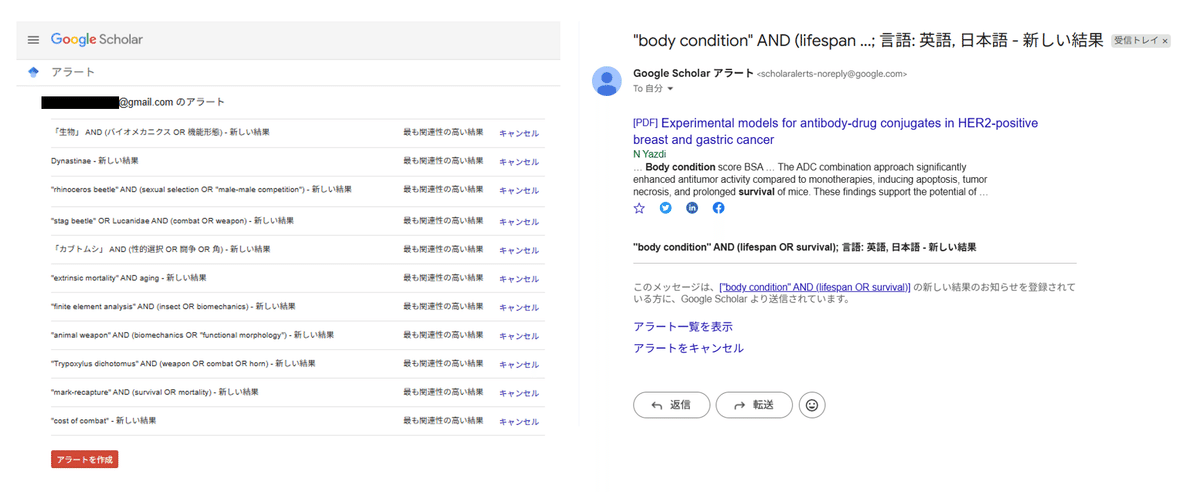
Google Scholarアラートは登録したキーワードに引っかかった新着論文をメールで通知してくれるサービス。これでメルマガのように新着論文を得る。
1.1 アルゴリズム的発見と検索演算子の精緻化
Google Scholarのインデックスに対し、シグナル対ノイズ比(S/N比)を極限まで高めるためには、検索演算子(Search Operators)の駆使が不可欠である。
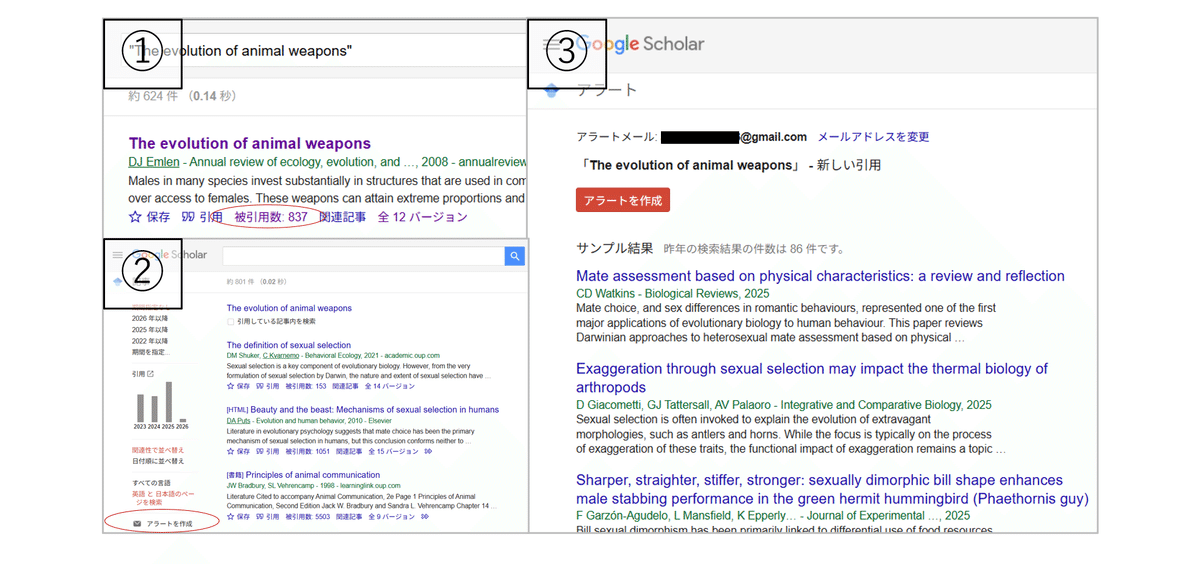
ブール論理の階層化: 例えば「昆虫の形態進化」を追う際、単一キーワードでは不十分である。(Insect OR Arthropod) AND (Morphology OR Anatomy) AND Evolution のように、同義語をORで包括し必須要素をANDで結合することで、表記ゆれによる取りこぼしを防ぎつつ無関係な文献を排除する。
完全一致とフィールド限定: "morphological evolution"のようにダブルクォーテーションを用い、語順を固定する。さらに intitle: 演算子(例: intitle:"morphology evolution")や author: 演算子を併用することで、本文中に散在するだけのノイズを除去し、核心的な研究のみを抽出するフィルタリングが可能となる。
1.2 「引用アラート」で把握する「記念碑的論文」の今
特筆すべきは、特定の論文が引用された際に通知を受け取る「引用アラート(Cited by alert)」である。これは過去の知見を検索するのではなく、基礎となる記念碑的論文(Seminal Paper)が「現在どのように発展・批判されているか」という情報の未来を追跡する仕組みである。「この分野ではこれがまず引用される!」といった状況で、このシステムはより一層輝く。
1.3 構造的制約への適応
システム上の制約として、1通の通知メールに含まれる論文数は最大20件である点に留意が必要である。活発な分野ではこの上限を超え、重要論文が消失するリスクがある。したがって、「人工知能」といった包括的なクエリではなく、「自然言語処理」「強化学習」のようにサブトピックごとにアラートを分割し、網羅性を担保するのが賢しい。
2. 論文をNotebookLMに取り込む
選別された文献を、GoogleのNotebookLMへ投入する。NotebookLMは一般的なチャットボットとは異なり、アップロードされた資料のみを知識源とする RAG(Retrieval-Augmented Generation:検索拡張生成)システムとして機能する。
2.1 Gemini Proモデルとソースグラウンディング
本サービスのバックエンドにはGemini Pro 1.5が採用されており、最大100万トークン超のコンテキストウィンドウにより、数十本の論文を断片化することなく一括で解析可能である。 最大の特徴は「ソースグラウンディング」にあり、回答の根拠をソース内に限定することで、LLM特有の幻覚(ハルシネーション)リスクを大幅に低減(約13%まで抑制との報告あり)させている。また、生成された回答には引用番号が付与され、原典の検証(Verification)が容易である点も学術用途に適している。
2.2 データプライバシーと著作権
エンタープライズ版および教育版アカウントにおいては、入力データがモデル学習に利用されないことが規約上明記されており、機密性の担保が可能である。著作権に関しては、私的使用の範囲内でのアップロードは一般に許容されるが、生成されたノートブックの共有には慎重な法的判断が必要。
3. 音声概要を作って解説してもらう
ここが本稿の要である。NotebookLMがなぜ革新かといえば、テキスト情報を対話形式の音声へ変換できるからだ。Audio Overview(音声概要)を活用する。
3.1 「Deep Dive」フォーマットと対話構造
生成される音声は単調な朗読ではなく、二人のAIホストによるダイナミックな対話(Dialogue)である。フィラー(言い淀み)や相互の問いかけを含む人間味のあるやり取りは、注意を持続させやすく、「社会的学習」の効果により理解を促進させる。まるでラジオを聴いているかのよう。
3.2 日本語対応と特性
現在、日本語を含む多言語に対応している。日本語版は英語と比較して要約が5〜10分程度に凝縮される傾向があり、全体把握(Executive Summary)に適している。ピッチアクセント等に若干の機械的特徴が見られるものの、文脈理解を妨げるレベルではない。
3.3 内容のステアリング
ユーザーは「方法論的欠陥に焦点を当てて」「初学者向けに噛み砕いて」といったプロンプト(指示)を与えることで、生成される対話の方向性を制御(ステアリング)できる。
筆者は以下の指示を与えて、ジャーナルクラブの体裁で概要を作成させている。
序論
・今回の論文(または研究テーマ)を選んだ理由を語り出しとして紹介する。
例:「今回取り上げる研究は〜についてです。なぜこれが面白いと思ったかというと…」
・この研究に取り組む背景や問題意識を、専門的すぎない言葉で説明する。
・どんな課題や現象を前にして研究者がこのテーマに取り組んだのかを整理する。
・研究者がどんな発想・着眼点でこのテーマにアプローチしたのかを紹介する。
材料および方法
・研究全体の流れを簡潔にまとめ、リスナーが実験・調査をイメージできるように説明する。
・特に、新規性のあるメソッドや工夫された点があれば、少し掘り下げて解説する。
例:「従来法ではこうでしたが、この研究ではこんな改良を加えています。」
結果
・主要な検証項目ごとに、「仮説 → 実際の結果 → それが何を意味するか」を順に語る。
・数値や統計は必要最低限に抑え、リスナーが理解しやすい比較や傾向で表現する。
考察
・結果が示唆することを1セクションずつ丁寧に解釈する。
・研究者の意図や、結果が従来の知見にどう新しい視点を加えたのかを説明する。
・最後に、「この研究の一番面白いポイント」や「残る課題」を一言でまとめて締めくくる。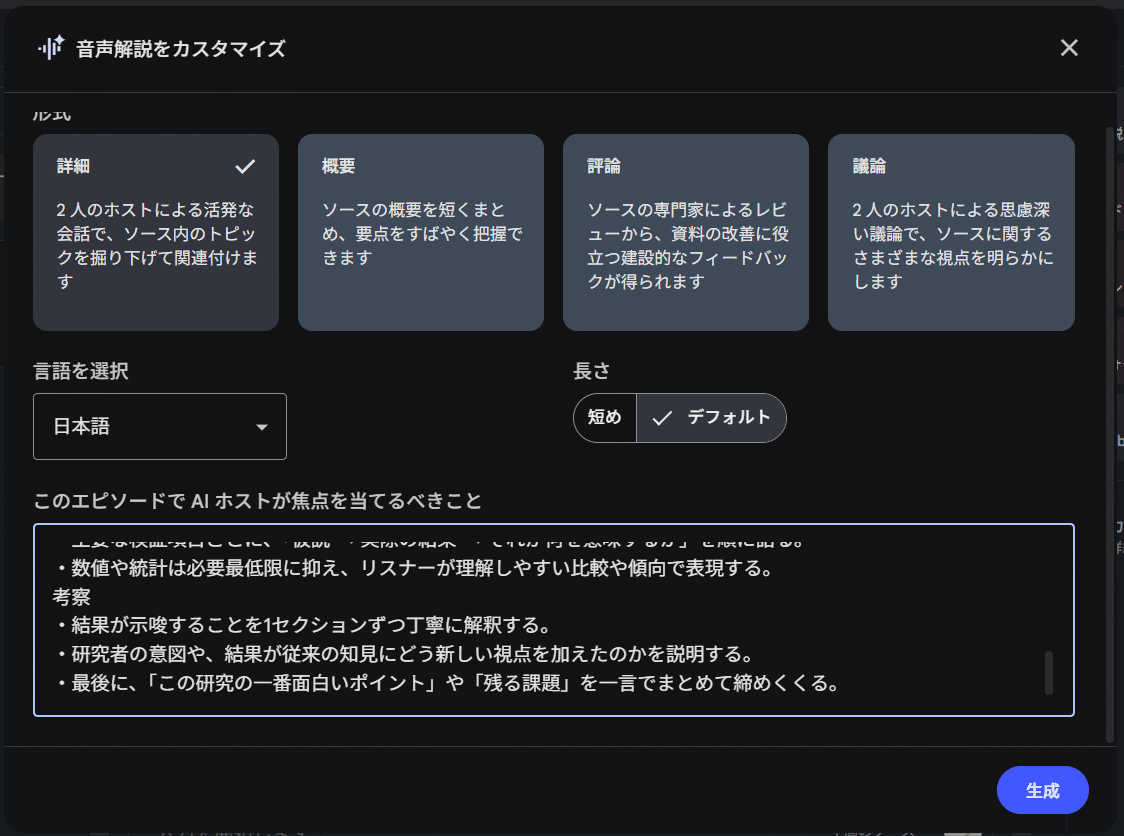
4. 音声概要をスマホで聴く
このワークフローを実践に落とし込むのが、モバイルアプリの活用である。バックグラウンド再生機能により、移動中などの非可処分時間を学習時間へと転換できる。
4.1 二重符号化理論による認知効率の向上
なぜ「聞いてから読む」のか。二重符号化理論(Dual Coding Theory)というものが認知心理学にはある。 聴覚で概要を構築しておくことで、後で実際に論文を読む際の認知負荷は大幅に低減されうる。「ラジオで言っていた箇所だ」という既知感が足場となり、難解な論文の読解速度と理解度を飛躍的に高めてくれる。
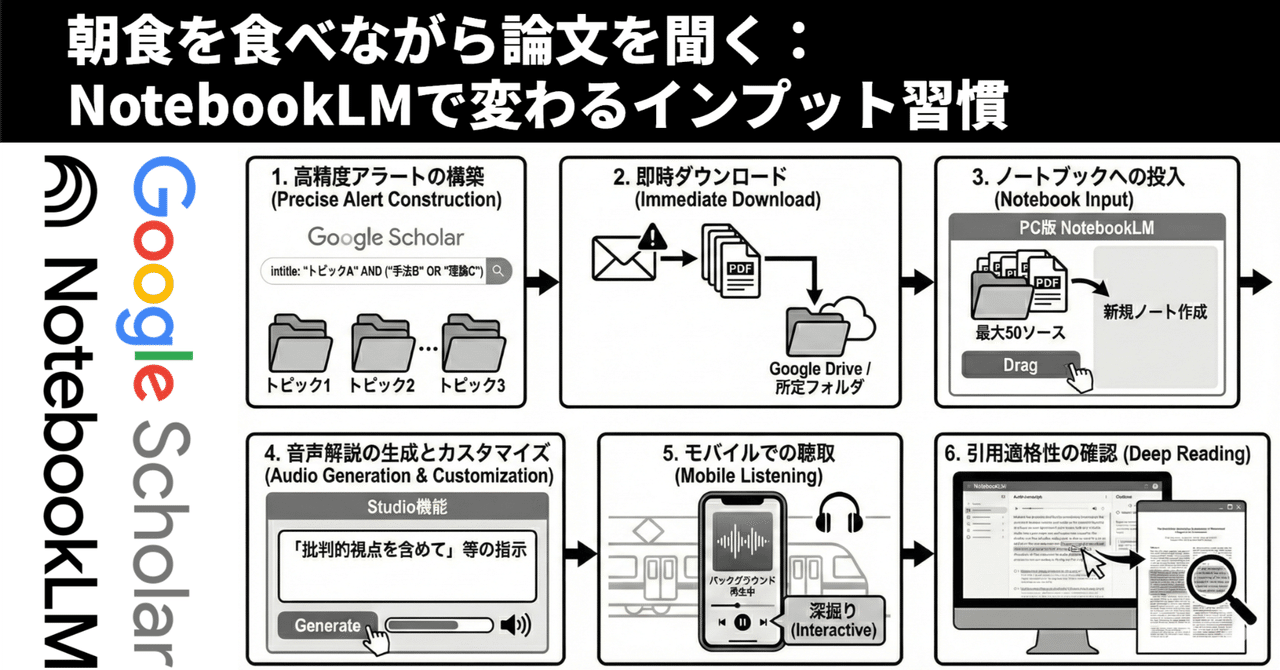
5. 実践的ワークフロー:設定から活用まで
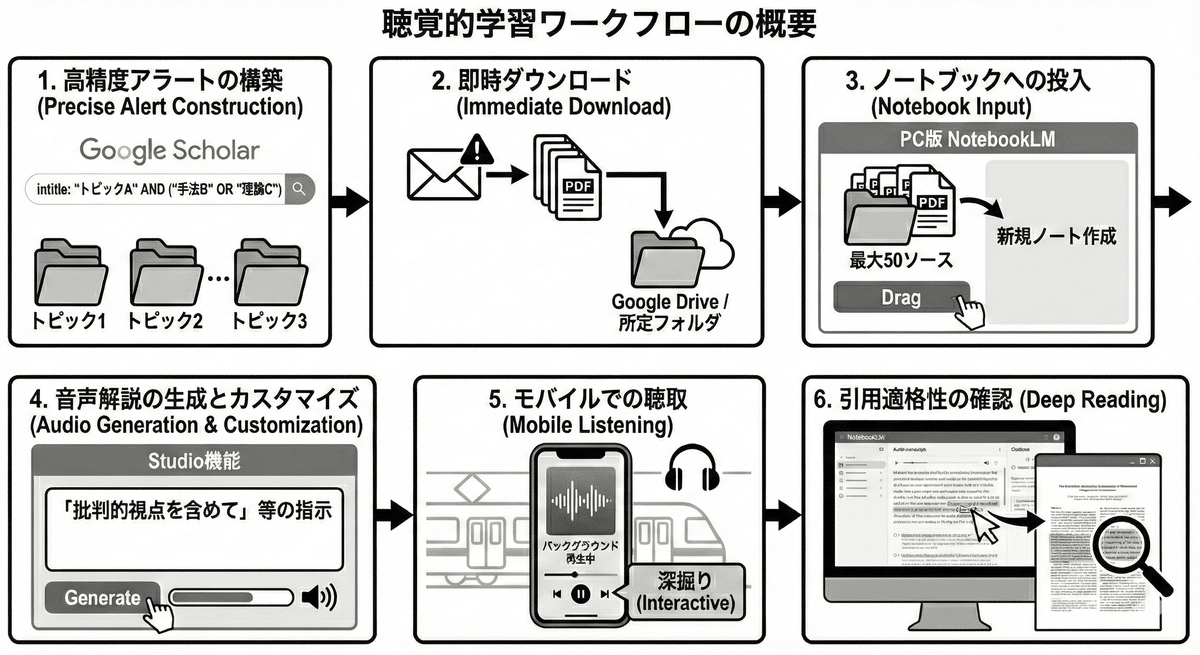
具体的な運用ステップを以下にまとめる。
高精度アラートの構築: Google Scholarにて intitle: や AND/OR を駆使したクエリを設定し、トピックごとに分割登録する。
即時ダウンロード: アラートメールからトリアージを行い、PDFをGoogleドライブ等の所定フォルダへ保存する。
ノートブックへの投入: PC版NotebookLMにて新規ノートを作成し、関連論文(最大50ソース)を一括アップロードする。
音声解説の生成とカスタマイズ: Studio機能にて「批判的視点を含めて」等の指示を出し、音声生成を開始する(生成時間を考慮し、隙間時間の前に実施)。
モバイルでの聴取: 移動中などにアプリでバックグラウンド再生を行う。気になった点はインタラクティブ機能で深掘りする。
引用適格性の確認(Deep Reading): 帰宅後、音声で触れられた重要データについて、NotebookLMの引用リンクから原典(PDF)を直接確認し、精読を行う。
6. クリティカル・アナリシス:限界と留意点
本手法は強力であるが、いくつかの限界も存在する。
雰囲気理解のリスク: 流暢な対話は強い納得感を与えるが、数式や詳細なロジックが省略される場合がある。「分かった気」になることを警戒し、重要論文は必ず原典に当たること。孫引きはNG。
幻覚の残存: ハルシネーションは低減されているとはいえゼロではない。特にAudio Overviewでは、話を盛り上げるための過剰な演出が含まれる可能性がある。違和感があったらファクトチェックを。
結論
Scholarアラートによる「漏れなき収集」、NotebookLMによる「構造化と音声化」、そしてモバイルアプリによる「場所を選ばない学習」。これらを統合したエコシステムは、研究者の最も希少なリソースである「時間」と「注意力」を最適化する。
AIを「答えを出す機械」ではなく「思考を補助する対話者」として扱い、聴覚と視覚をハイブリッドに活用するこのスタイルこそが、次世代の研究者にとっての標準装備となるであろう。
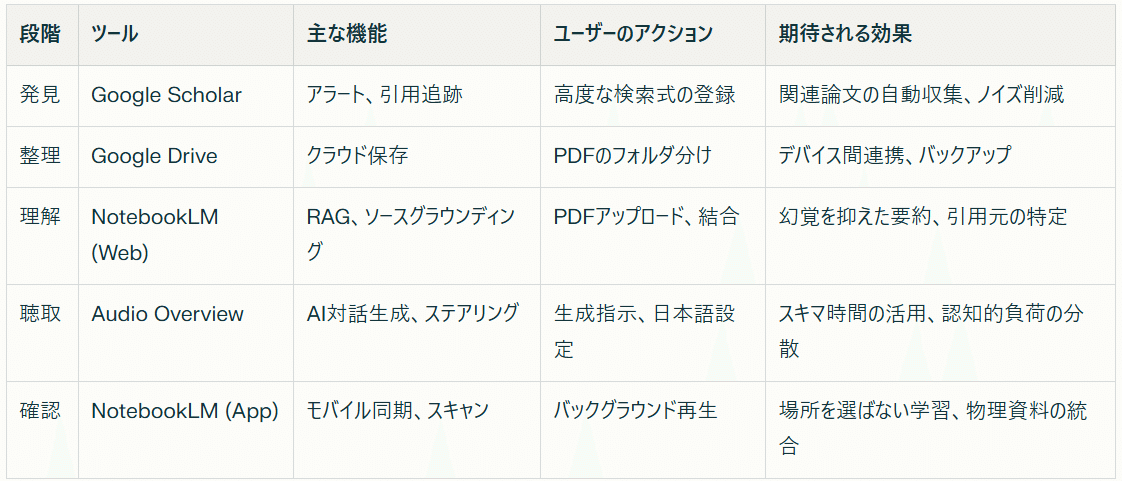
参考:各ツールの役割と特徴