ã“ã‚“ã«ã¡ã¯ï¼ アカツã‚ゲームス クライアントエンジニアã®Suã§ã™ã€‚
ã“ã®è¨˜äº‹ã¯Â Akatsuki Advent Calendar 2025 24日目ã®è¨˜äº‹ã§ã™ã€‚メリークリスマスï¼
ã¯ã˜ã‚ã«
å¦ç”Ÿæ™‚代ã«å¼·åŒ–å¦ç¿’ã®ç ”究を少ã—ãŸã®ã§ã€ä¹…ã—ã¶ã‚Šã«å¼·åŒ–å¦ç¿’ã‚’ã‚„ã‚ŠãŸã„ãªã€œã®æ°—æŒã¡ã§æœ¬è¨˜äº‹ã‚’書ãã¾ã—ãŸã€‚今回ã¯Gymnasiumã¨ã„ã†Pythonライブラリを使用ã—ãŸçµŒé¨“を紹介ã—ãŸã„ã¨æ€ã„ã¾ã™ï¼
強化å¦ç¿’ã¨ã¯ï¼Ÿ
強化å¦ç¿’(Reinforcement Learning)ã¯ç°¡å˜ã«ã„ã†ã¨ã€ã‚¨ãƒ¼ã‚¸ã‚§ãƒ³ãƒˆãŒç’°å¢ƒã®ä¸ã§ã‚¢ã‚¯ã‚·ãƒ§ãƒ³ã¨å®Ÿè¡Œã—ã€ãã®çµæžœã‹ã‚‰å¦ç¿’ã—ã€ã‚¨ãƒ¼ã‚¸ã‚§ãƒ³ãƒˆãŒã‚ˆã‚Šã„ã„çµæžœã‚’出力ã§ãるよã†ã«ã‚¢ã‚¯ã‚·ãƒ§ãƒ³ã‚’é¸æŠžã™ã‚‹æ–¹æ³•ã‚’最é©åŒ–ã™ã‚‹ã“ã¨ã§ã™ã€‚
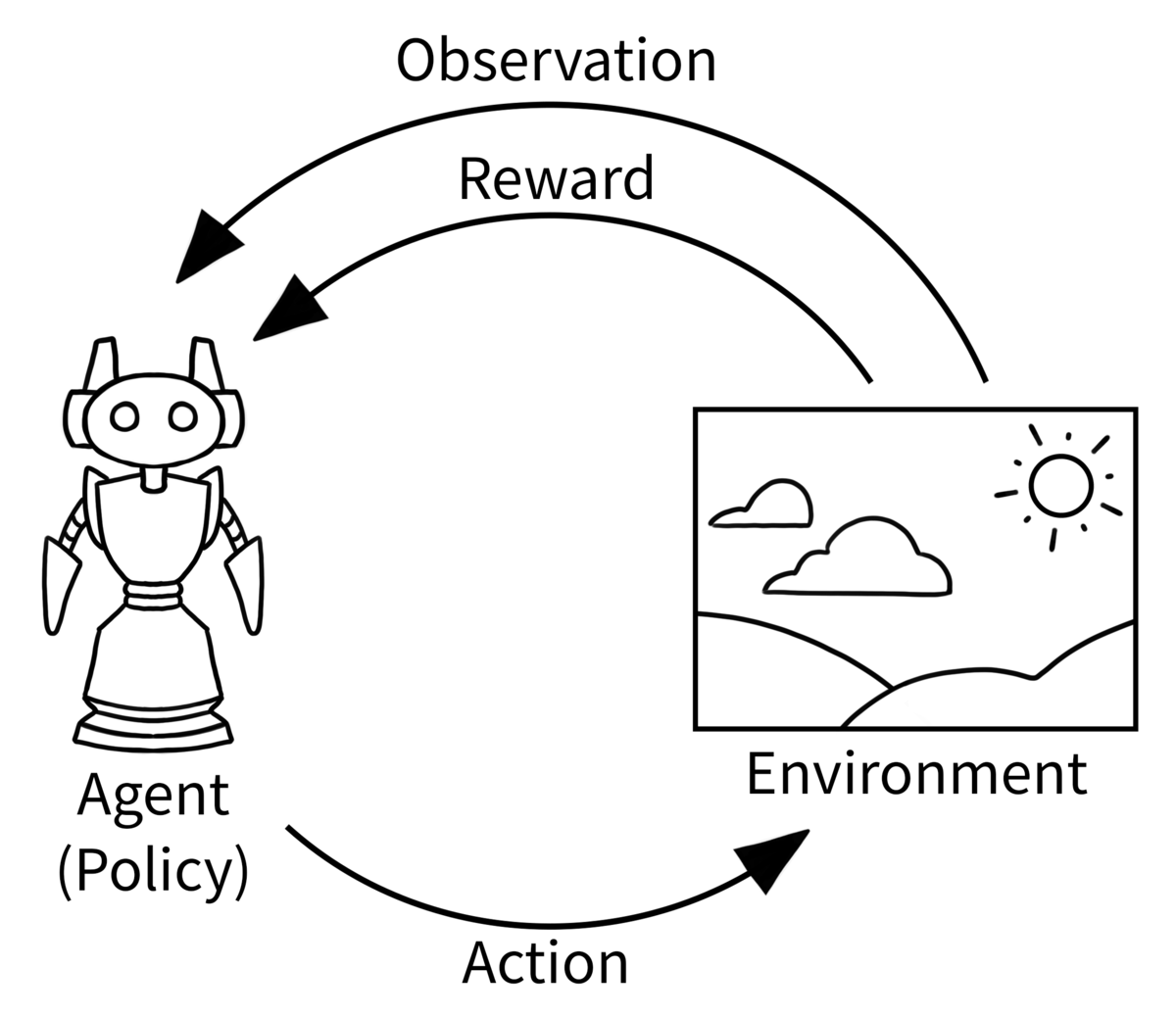
(Gymnasium-Basic Usageより)
例ãˆã°ã€ãƒ¬ãƒ¼ã‚·ãƒ³ã‚°ã‚²ãƒ¼ãƒ ã§è‡ªå‹•é‹è»¢ã®ã‚¨ãƒ¼ã‚¸ã‚§ãƒ³ãƒˆã‚’作るã¨ã—ãŸã‚‰:
- Action: åŠ é€Ÿã€æ¸›é€Ÿã€æ–¹å‘を変ã‚ã‚‹
- Observation: ゴールã¾ã§ã®è·é›¢ã€å£ã®æ–¹å‘ã¨è·é›¢ã€çµŒéŽæ™‚é–“...
- Reward: èµ°è¡Œã—ãŸè·é›¢ã€å£ã«ã¶ã¤ã‹ã‚‹å›žæ•°...
エージェントãŒã‚¢ã‚¯ã‚·ãƒ§ãƒ³ã‚’決ã‚るアルゴリズムã¯å¼·åŒ–å¦ç¿’分野ã®é‡è¦ãƒˆãƒ”ックã§ã™ã€‚Q-Learningã€PPOã€SACã€æœ€è¿‘ã§ãŸDAPOãªã©ã€ã‚¢ãƒ«ã‚´ãƒªã‚ºãƒ ã®é€²åŒ–速度ã¯ã¨ã¦ã‚‚æ—©ã„ã§ã™ã€‚ã“ã®è¨˜äº‹ã¯æ·±æŽ˜ã‚Šã—ã¾ã›ã‚“ãŒã€èˆˆå‘³ãŒã‚ã‚Šã¾ã—ãŸã‚‰ãœã²èª¿ã¹ã¦ã¿ã¦ãã ã•ã„ï¼
Gymnasiumã¨ã¯ï¼Ÿ
2021å¹´ã«OpenAI Gym library ã®é–‹ç™ºãƒãƒ¼ãƒ ㌠Gymnasium ã«ç§»è»¢ã—ã¾ã—ãŸã€‚
強化å¦ç¿’環境開発・訓練ã«ç‰¹åŒ–ã—㟠Python ライブラリã§ã™ã€‚
(https://gymnasium.farama.org/ より)
今回ã¯å…¬å¼ãƒ‰ã‚ュメントã«ã‚る例ã®ãƒžãƒƒãƒ—ã‚’æ”¹é€ ã—ã¦ã€ãã®ãƒžãƒƒãƒ—上ã«ãƒ—レイヤーã€ã‚´ãƒ¼ãƒ«ã€ãƒˆãƒ©ãƒƒãƒ—ãŒã‚ã‚Šã¾ã™ã€‚プレイヤーを動ã‹ã—ã¦ã€ãƒˆãƒ©ãƒƒãƒ—ã‚’ã§ãã‚‹ã ã‘è¸ã¾ãªã„よã†ã«ã€çµ‚点ã¾ã§ç§»å‹•ã™ã‚‹ã‚¿ã‚¹ã‚¯ã‚’AIã«å¦ç¿’ã•ã›ã€ãã®å¦ç¿’çµæžœã‚’評価ã—ãŸã„æ€ã„ã¾ã™ã€‚
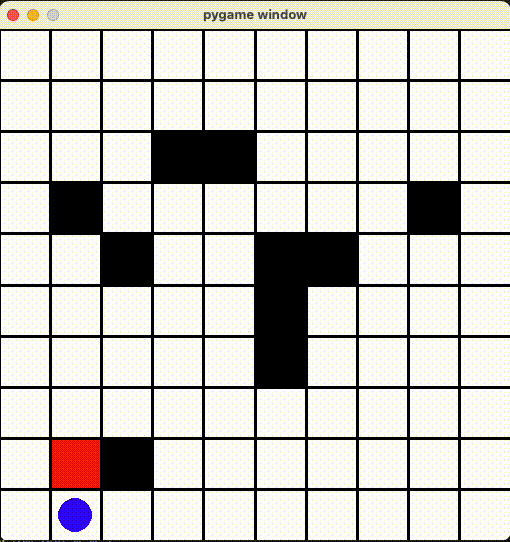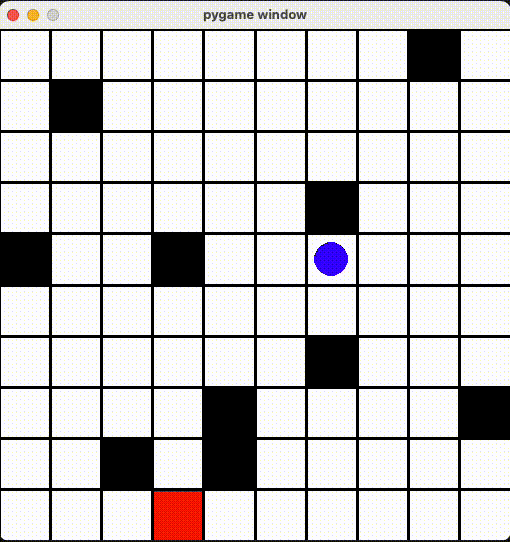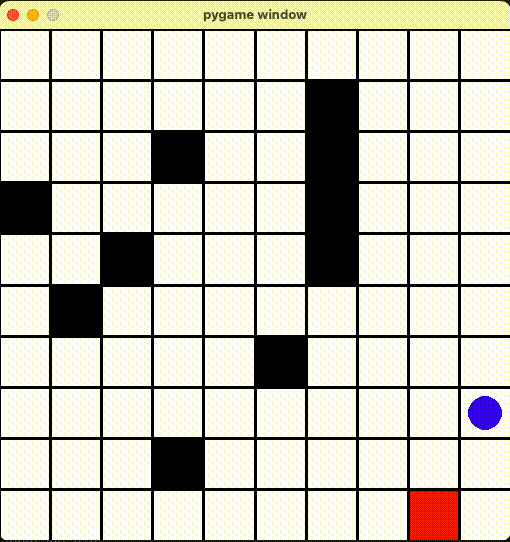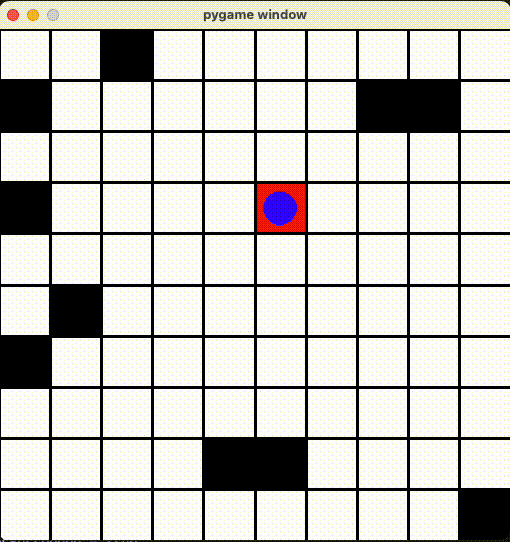
環境ã®ä½œæˆ
ã¾ãšã€Gymnasium環境クラス gymnasium.Env 3パートã§æ§‹æˆã•ã‚Œã¾ã™ï¼šåˆæœŸåŒ–ã€æ›´æ–°ã€æç”»ã§ã™ã€‚ãã‚Œã¨ä¸‹è¨˜ã®æƒ…å ±ã¯ã‚³ãƒ³ã‚¹ãƒˆãƒ©ã‚¯ã‚¿ã§å®šç¾©ã—ã¾ã™ï¼š
- Observation ã®æœ€å¤§æœ€å°å€¤(observation space)
- å¯èƒ½ãª Action(action space)
- æç”»ã€ãƒ‡ãƒãƒƒã‚°ãƒ‘ラメター(metadata)
- ランダムシート(np_random) → 特定çµæžœã‚’å†ç¾ã—ãŸã„時ã«ä½¿ã†ã¨ä¾¿åˆ©
åˆæœŸåŒ–
処ç†ã¯ reset() ã«å…¥ã‚Œã¾ã™ã€‚環境をåˆæœŸçŠ¶æ…‹ã«ã™ã‚‹å‡¦ç†ã§ã™ã€‚最åˆã® Observation ã‚’è¿”ã—ã¾ã™ã€‚処ç†ã¯ 1 episode(タスク開始〜終了)ã”ã¨ã«å®Ÿè¡Œã•ã‚Œã¾ã™ã€‚今回ã¯ãƒ—レイヤーã€ã‚´ãƒ¼ãƒ«ã€ãƒˆãƒ©ãƒƒãƒ—ã®ä½ç½®ã‚’ランダムã«ç”Ÿæˆã™ã‚‹å‡¦ç†ã‚’書ãã¾ã—ãŸã€‚Observation ã¯ãƒ—レイヤーã€ã‚´ãƒ¼ãƒ«ã€ãƒˆãƒ©ãƒƒãƒ—ã®ä½ç½®ã«ã—ã¾ã™ã€‚
æ›´æ–°
実行ã™ã‚‹Actionã‚’ step() 関数ã«æ¸¡ã—ã¦ã€ç’°å¢ƒã¯ã©ã†å¤‰åŒ–ã™ã‚‹ã‹ã¨ã“ã®è¡Œå‹•ã¯ã„ã„ã‹ã©ã†ã‹ã‚’è¿”ã™ã€‚今回㮠Action ã¯ç§»å‹•æ–¹å‘ã§ã€é–¢æ•°å†…ã«ã¯ãƒ—レイヤーã®ä½ç½®ã‚’æ›´æ–°ã€ã‚´ãƒ¼ãƒ«ã«ã¤ã„ãŸã‚‰ç‚¹æ•°ã‚’与ãˆã‚‹ã€ãƒˆãƒ©ãƒƒãƒ—ã‚’è¸ã‚“ã ら減点ã«ã—ã¾ã—ãŸã€‚
æç”»
render() 関数ã«å®šç¾©ã•ã‚Œã¾ã™ã€‚今回ã¯é’ã„丸ãŒãƒ—レイヤーã€èµ¤ã„丸ãŒã‚´ãƒ¼ãƒ«ã€é»’ã„丸ãŒãƒˆãƒ©ãƒƒãƒ—ã€ãã‚Œã¨ãƒžã‚¹ã‚’ PyGame ライブラリã§æç”»ã—ã¾ã—ãŸã€‚
パッケージ
環境ã§ããŸã‚‰ã€åˆ©ç”¨ã—ã‚„ã™ããŸã‚パッケージ化ã—ã¾ã™ã€‚パッケージ化ã™ã‚‹ã¨ã€ä¾¿åˆ©ãª Wrapper ãŒä½¿ãˆã¾ã™ã€‚Observation ã‚’ä»–ã®å½¢å¼ã«å¤‰æ›´ã™ã‚‹ï¼ˆä¾‹ãˆã°ã€ãƒ—レイヤーã¨ã‚´ãƒ¼ãƒ«ã®ä½ç½®ã§ã¯ãªãã€ãã®ç›¸å¯¾ä½ç½®ã«å¤‰æ›´ï¼‰ã«ã¯ã‚ˆã使ã„ã—ã¾ã™ã€‚
エージェント
Observation を見ã¦ã€ã©ã†ã„ㆠAction ã‚’å–ã‚‹ã‹ã‚’決ã‚るルールã§ã™ã€‚Q-Learningã€PPOã€SAC ã¨ã„ã†ã‚¢ãƒ«ã‚´ãƒªã‚ºãƒ ã®éƒ¨åˆ†ã§ã™ã€‚自分ã§å®Ÿè£…ã™ã‚‹ã®ã‚‚ã„ã„ã—ã€å…¬å¼ãŠã™ã™ã‚ã®ãƒ©ã‚¤ãƒ–ラリ Stable-Baselines3 を使ã†ã¨ä¾¿åˆ©ã§ã™ã€‚パッケージã•ã‚ŒãŸ Gym 環境ãŒã‚ã‚Œã°ä¸‹è¨˜ã®ã‚ˆã†ã«ç°¡å˜ã«ãƒ¢ãƒ‡ãƒ«ä½œã‚Œã¾ã™ã€‚複数環境ã§ä¸¦è¡Œå¦ç¿’ã‚‚ã§ãã¾ã™ã€‚
å¦ç¿’
環境ã‹ã‚‰è¿”ã—ãŸç‚¹æ•°ã§ä»Šå›žé¸ã‚“ã Actionを評価ã—ã¦ã€æ¬¡åŒã˜ObservationãŒæ¥ãŸæ™‚ã«åŒã˜Actionã‚’é¸ã¶ã‹ã©ã†ã‹ã€ã‚¢ãƒ«ã‚´ãƒªã‚ºãƒ ã‚’ä¿®æ£ã—ã¾ã™ã€‚Stable-Baselines3ã®ãƒ‰ã‚ュメントをå‚考ã™ã‚Œã°å„パラメターã®æ„味ãŒæ›¸ã‹ã‚Œã¦ã„ã¾ã™ã®ã§ã€ã“ã“ã¯å‰²æ„›ã—ã¾ã™ã€‚
ãƒã‚°
Stable-Baselines3 㯠TensorBoard 出力ã§ãã¾ã™ã€‚TensorBoard を使用ã—ã¦ãƒã‚°ã‚’出力ã§ãã¾ã™ã€‚å¦ç¿’ã®éŽç¨‹ã‚’図ã§è¡¨ç¤ºã§ãã¾ã™ã€‚å¦ç¿’足りã¦ã„ã‚‹ã‹ã©ã†ã‹ã®ç¢ºèªã‚„パラメター調整ã™ã‚‹éš›ã«ã‹ãªã‚Šå‚考ã«ãªã‚Šã¾ã—ãŸã€‚
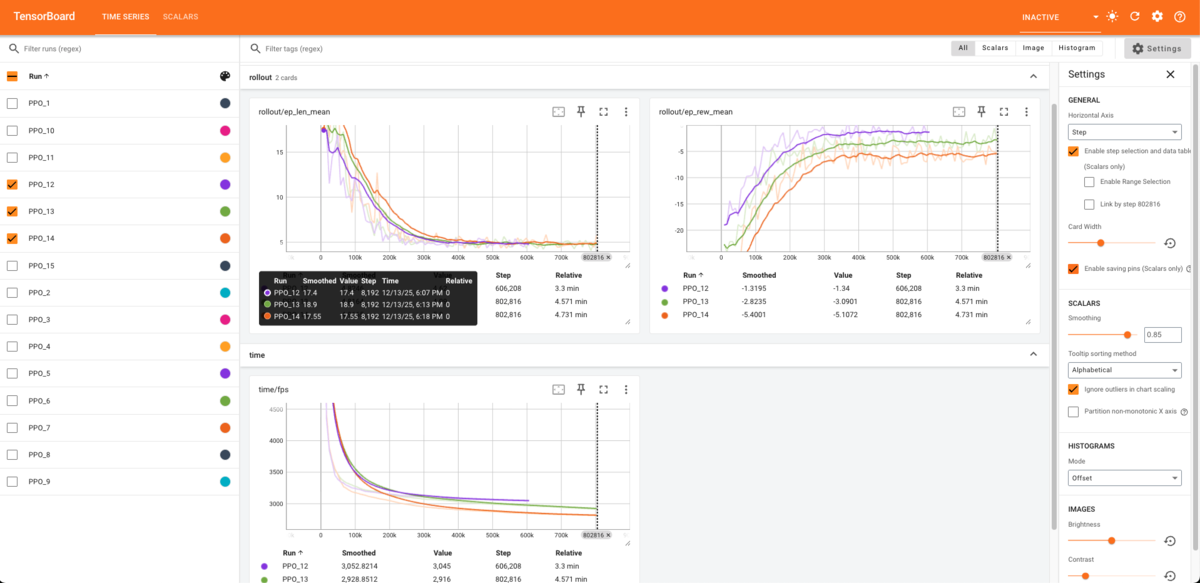
訓練çµæžœã‚’評価
Stable-Baselines3ã§å¦ç¿’ã—ãŸãƒ¢ãƒ‡ãƒ«ã‚’ä¿å˜ã§ãã¾ã™ã€‚ãã®ä¿å˜ã—ãŸãƒ¢ãƒ‡ãƒ«ã‚’ãƒãƒ¼ãƒ‰ã™ã‚Œã°ã€ä¸ŽãˆãŸ Observation ã«å¯¾ã—㦠Action を出力ã—ã¾ã™ã€‚
<gist>
よã—ï¼æœ€å¼·ã®AIを作ã£ãŸã®ã§ã€æ—©é€Ÿãƒ¢ãƒ‡ãƒ«ã‚’試ã™ãžï¼
ã‚ã‚Œã€ãªã‚“ã‹å‹•ã‹ãªã„ã ã‘ã©......
移動ã—ãªã„
最åˆã®å•é¡Œã¯ã€å£ã«ã¶ã¤ã‘ãŸã‚‰ç§»å‹•ã—ãªããªã£ãŸå•é¡Œã§ã™ã€‚ã“れを解決ã™ã‚‹ãŸã‚ã«ã€ã€Œå‰å›žã¨åŒã˜ä½ç½®ãªã‚‰æ¸›ç‚¹ã€ã™ã‚‹Rewardã‚’è¿½åŠ ã—ã¦ã¿ã¾ã—ãŸãŒ...
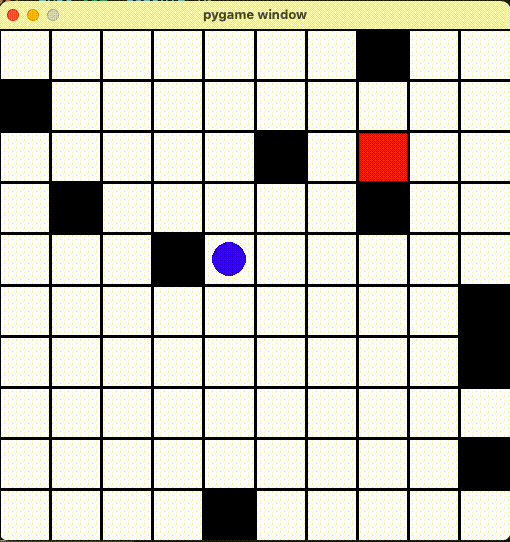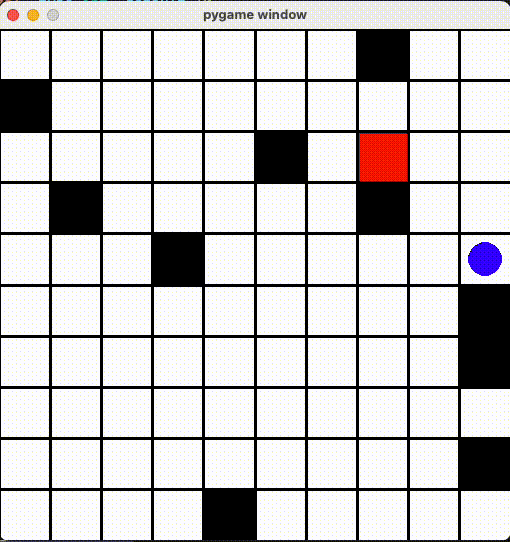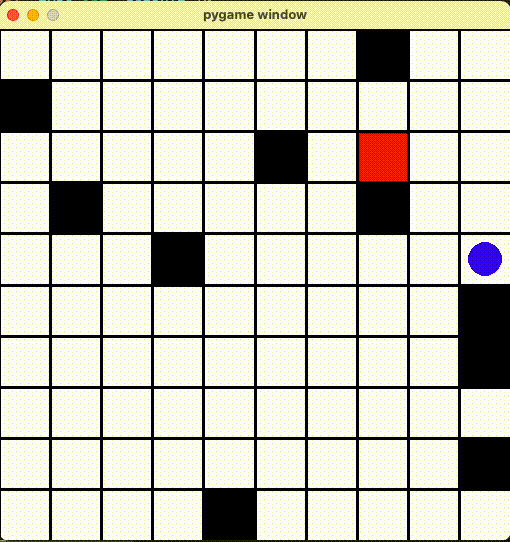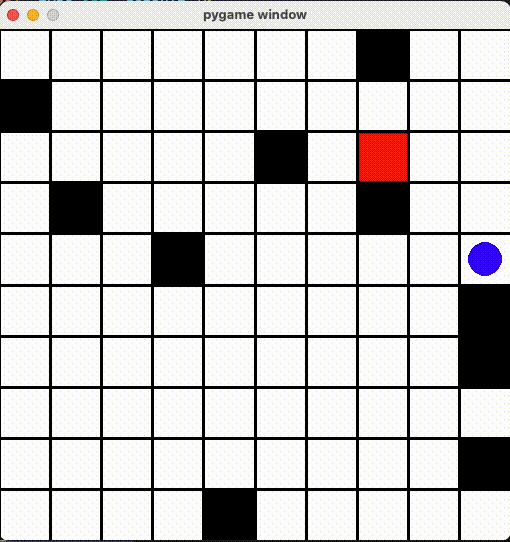
ãšã£ã¨éš£ã®ãƒžã‚¹ã«è¡Œã£ãŸã‚Šãã£ãŸã‚Š
「åŒã˜å ´æ‰€ã˜ã‚ƒãªã‘ã‚Œã°ã„ã„ã€ã¨ã‚¨ãƒ¼ã‚¸ã‚§ãƒ³ãƒˆã‚‚ãã®æŠœã‘é“を見ã¤ã‘ã¦ã€ãšã£ã¨åŒã˜ãƒžã‚¹ã«è¡Œã£ãŸã‚Šãã£ãŸã‚Šã—ã¦ã„ã¾ã—ãŸ...
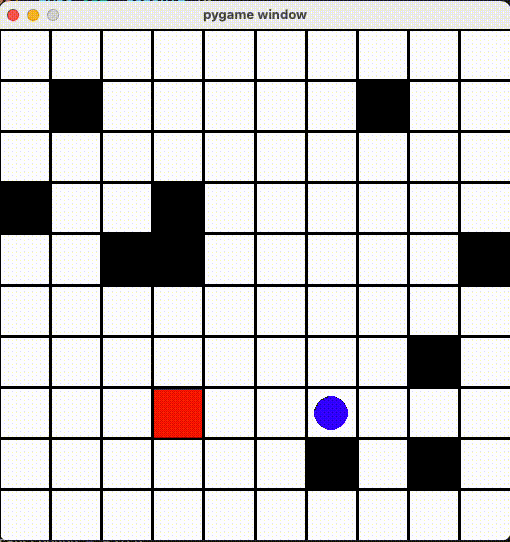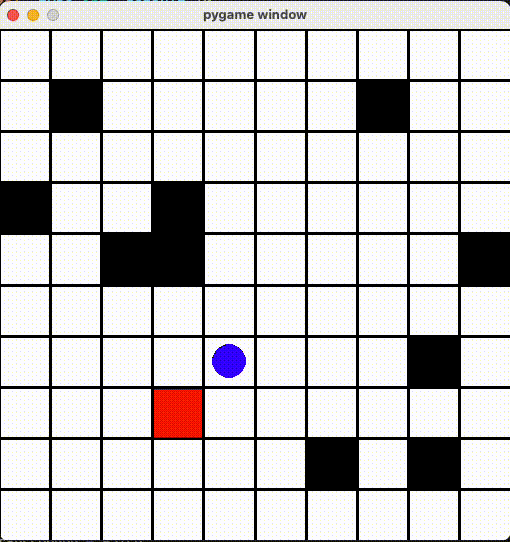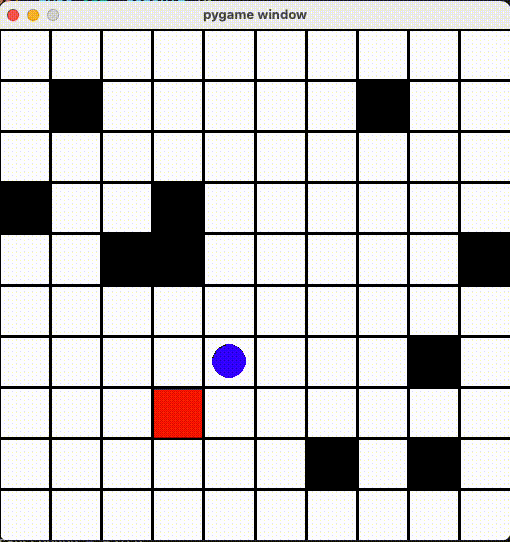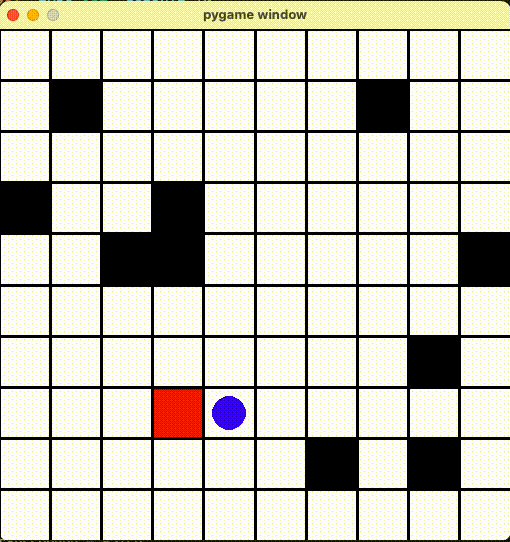
AIã¡ã‚ƒã‚“ã‚’ã¡ã‚ƒã‚“ã¨å‹•ã‹ã›ã‚‹ãŸã‚ã€ã€Œã™ã§ã«çµŒéŽã—ãŸå ´æ‰€ã«ç§»å‹•ã™ã‚‹ã¨æ¸›ç‚¹ã™ã‚‹ï¼ã€ã‚ˆã†ã« Reward ä¿®æ£ã—ã¾ã—ãŸã€‚
色々調整ã—ãŸçµæžœã€ãã‚Œã£ã½ã„å‹•ãã«ãªã£ãŸï¼
時々トラップã«è¸ã‚€ã§ã™ãŒã€é¿ã‘るよã†ã«é ‘å¼µã£ã¦ã‚‹ã‚’æ„Ÿã˜ã¦ã¾ã™ã€‚
より広ã„マップ
15x15ã®ãƒžãƒƒãƒ—ã§æ”¹ã‚ã¦å¦ç¿’ã•ã›ã¾ã—ãŸï¼10x10よりå¦ç¿’時間2å€ã‹ã‹ã£ãŸãŒã€æˆæžœã¯æ‚ªããªã„ã¨æ€ã„ã¾ã™ã€‚
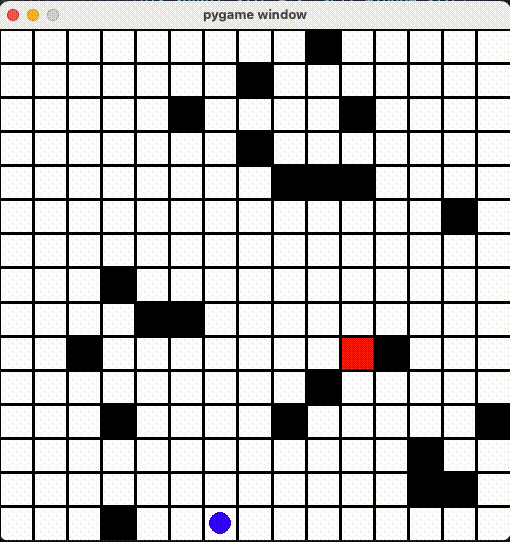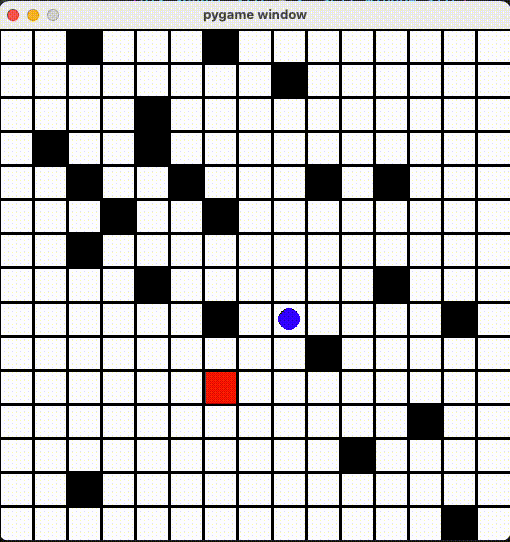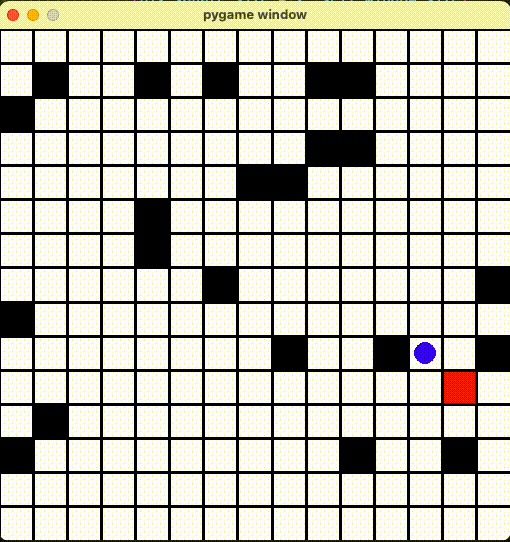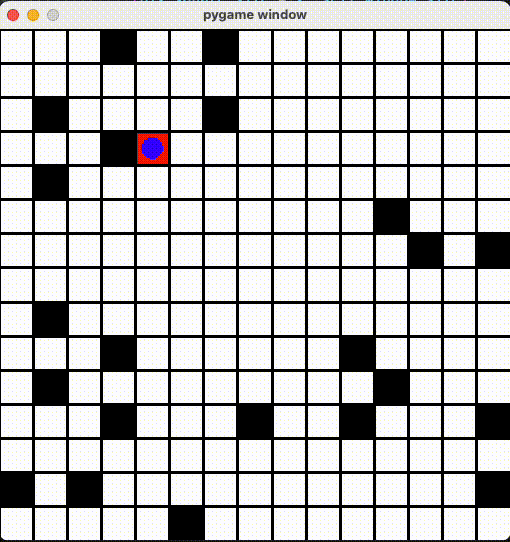
Github Repo
今回使用ã—ãŸã‚³ãƒ¼ãƒ‰ã‚’GitHubã«ã‚¢ãƒƒãƒ—ãƒãƒ¼ãƒ‰ã—ãŸã®ã§ã€èˆˆå‘³ãŒã‚ã‚‹æ–¹ã¯ãœã²è§¦ã£ã¦ã¿ã¦ãã ã•ã„ï¼
最後ã«
調整ã—ã¦AIã‚’ã©ã‚“ã©ã‚“æˆé•·ã•ã›ã‚‹ã®ã‚‚楽ã—ã„ã§ã™ãŒã€é©åˆ‡ãªRewardã‚’è¨å®šã™ã‚‹ã®ãŒé›£ã—ã„ã¨å®Ÿæ„Ÿã—ã¾ã—ãŸã€‚ãã‚Œã¨ã€å€‹äººçš„ãªæ„Ÿæƒ³ã§ã™ãŒã€ActionãŒé€£ç¶šã‚¹ãƒšãƒ¼ã‚¹ãªã‚¿ã‚¹ã‚¯ã®æ–¹ãŒå¾—æ„ãªã‚¤ãƒ¡ãƒ¼ã‚¸ãŒã‚ã‚Šã¾ã™ã€‚ã¨ãªã‚‹ã¨Actionã®è¨è¨ˆã‚‚é‡è¦ã«ãªã£ã¦ãã¾ã™ã。もã£ã¨è¤‡é›‘ãªã‚¿ã‚¹ã‚¯ã‚’やらã›ã¦æ¬²ã—ããªã£ãŸï¼
AIã ã‘ã§ã¯ãªãã€å¼·åŒ–å¦ç¿’ã®æ¦‚念ã¨ã‚¢ãƒ«ã‚´ãƒªã‚ºãƒ ã¯ã‚²ãƒ¼ãƒ 開発ä¸ã«ã‚‚活用ã§ãã‚‹ã¨æ€ã„ã¾ã™ã€‚勉強ã«ãªã‚Šã¾ã—ãŸï¼
明日ã¯25æ—¥ï¼ã‚¯ãƒªã‚¹ãƒžã‚¹å½“æ—¥ã«è»æ›¹ãŒç´ 敵ãªè¨˜äº‹ã‚’公開ã™ã‚‹äºˆå®šã§ã™ã€‚ã¿ãªã•ã‚“ãœã²èªã‚“ã§ã¿ã¦ãã ã•ã„〜ï¼