# Maven
## 基本介ç»
### Mvn介ç»
Maven:本质是一个项目管ç†å·¥å…·ï¼Œå°†é¡¹ç›®å¼€å‘和管ç†è¿‡ç¨‹æŠ½è±¡æˆä¸€ä¸ªé¡¹ç›®å¯¹è±¡æ¨¡åž‹ï¼ˆPOM)
POM:Project Object Model 项目对象模型。Maven 是用 Java è¯è¨€ç¼–写的,管ç†çš„东西以é¢å‘对象的形å¼è¿›è¡Œè®¾è®¡ï¼Œæœ€ç»ˆæŠŠä¸€ä¸ªé¡¹ç›®çœ‹æˆä¸€ä¸ªå¯¹è±¡ï¼Œè¿™ä¸ªå¯¹è±¡å«åš POM
pom.xml:Maven 需è¦ä¸€ä¸ª pom.xml 文件,Maven é€šè¿‡åŠ è½½è¿™ä¸ªé…置文件å¯ä»¥çŸ¥é“项目的相关信æ¯ï¼Œè¿™ä¸ªæ–‡ä»¶ä»£è¡¨å°±ä¸€ä¸ªé¡¹ç›®ã€‚å¦‚æžœåš 8 个项目,对应的是 8 个 pom.xml 文件
ä¾èµ–管ç†ï¼šMaven 对项目所有ä¾èµ–资æºçš„一ç§ç®¡ç†ï¼Œå®ƒå’Œé¡¹ç›®ä¹‹é—´æ˜¯ä¸€ç§åŒå‘关系,å³åšé¡¹ç›®æ—¶å¯ä»¥ç®¡ç†æ‰€éœ€è¦çš„其他资æºï¼Œå½“其他项目需è¦ä¾èµ–我们项目时,Maven 也会把我们的项目当作一ç§èµ„æºåŽ»è¿›è¡Œç®¡ç†ã€‚
管ç†èµ„æºçš„å˜å‚¨ä½ç½®ï¼šæœ¬åœ°ä»“库,ç§æœï¼Œä¸å¤®ä»“库

基本作用:
* 项目构建:æä¾›æ ‡å‡†çš„ï¼Œè·¨å¹³å°çš„自动化构建项目的方å¼
* ä¾èµ–管ç†ï¼šæ–¹ä¾¿å¿«æ·çš„管ç†é¡¹ç›®ä¾èµ–的资æºï¼ˆjar 包),é¿å…资æºé—´çš„版本冲çªç‰é—®é¢˜
* 统一开å‘结构:æä¾›æ ‡å‡†çš„ï¼Œç»Ÿä¸€çš„é¡¹ç›®å¼€å‘结构

å„目录å˜æ”¾èµ„æºç±»åž‹è¯´æ˜Žï¼š
* src/main/java:项目 java æºç
* src/main/resources:项目的相关é…置文件(比如 mybatis é…置,xml æ˜ å°„é…置,自定义é…置文件ç‰ï¼‰
* src/main/webapp:web 资æºï¼ˆæ¯”如 htmlã€cssã€js ç‰ï¼‰
* src/test/java:测试代ç
* src/test/resources:测试相关é…置文件
* src/pom.xml:项目 pom 文件
å‚考视频:https://www.bilibili.com/video/BV1Ah411S7ZE
***
### 基础概念
仓库:用于å˜å‚¨èµ„æºï¼Œä¸»è¦æ˜¯å„ç§ jar 包。有本地仓库,ç§æœï¼Œä¸å¤®ä»“库,ç§æœå’Œä¸å¤®ä»“库都是远程仓库
* ä¸å¤®ä»“库:Maven 团队自身维护的仓库,属于开æºçš„
* ç§æœï¼šå„å…¬å¸/部门ç‰å°èŒƒå›´å†…å˜å‚¨èµ„æºçš„仓库,ç§æœä¹Ÿå¯ä»¥ä»Žä¸å¤®ä»“库获å–资æºï¼Œä½œç”¨ï¼š
* ä¿å˜å…·æœ‰ç‰ˆæƒçš„资æºï¼ŒåŒ…å«è´ä¹°æˆ–è‡ªä¸»ç ”å‘çš„ jar
* 一定范围内共享资æºï¼Œèƒ½åšåˆ°ä»…对内ä¸å¯¹å¤–开放
* 本地仓库:开å‘者自己电脑上å˜å‚¨èµ„æºçš„仓库,也å¯ä»Žè¿œç¨‹ä»“库获å–资æº
åæ ‡ï¼šMaven ä¸çš„åæ ‡ç”¨äºŽæ述仓库ä¸èµ„æºçš„ä½ç½®
* ä½œç”¨ï¼šä½¿ç”¨å”¯ä¸€æ ‡è¯†ï¼Œå”¯ä¸€æ€§å®šä¹‰èµ„æºä½ç½®ï¼Œé€šè¿‡è¯¥æ ‡è¯†å¯ä»¥å°†èµ„æºçš„识别与下载工作交由机器完æˆ
* https://mvnrepository.com:查询 maven æŸä¸€ä¸ªèµ„æºçš„åæ ‡ï¼Œè¾“å…¥èµ„æºå称进行检索
* ä¾èµ–设置:
* groupId:定义当å‰èµ„æºéš¶å±žç»„织å称(通常是域åå写,如:org.mybatis)
* artifactId:定义当å‰èµ„æºçš„å称(通常是项目或模å—å称,如:crmã€sms)
* version:定义当å‰èµ„æºçš„版本å·
* packaging:定义资æºçš„打包方å¼ï¼Œå–值一般有如下三ç§
* jar:该资æºæ‰“æˆ jar 包,默认是 jar
* war:该资æºæ‰“æˆ war 包
* pom:该资æºæ˜¯ä¸€ä¸ªçˆ¶èµ„æºï¼ˆè¡¨æ˜Žä½¿ç”¨ Maven 分模å—管ç†ï¼‰ï¼Œæ‰“包时åªç”Ÿæˆä¸€ä¸ª pom.xml ä¸ç”Ÿæˆ jar 或其他包结构
***
## 环境æ建
### 环境é…ç½®
Maven 的官网:http://maven.apache.org/
下载安装:Maven 是一个绿色软件,解压å³å®‰è£…
目录结构:
* bin:å¯æ‰§è¡Œç¨‹åºç›®å½•
* boot:Maven 自身的å¯åŠ¨åŠ 载器
* conf:Maven é…置文件的å˜æ”¾ç›®å½•
* lib:Mavenè¿è¡Œæ‰€éœ€åº“çš„å˜æ”¾ç›®å½•
é…ç½® MAVEN_HOME:

Path 下é…置:`%MAVEN_HOME%\bin`
环境å˜é‡é…置好之åŽéœ€è¦æµ‹è¯•çŽ¯å¢ƒé…置结果,在 DOS 命令窗å£ä¸‹è¾“入以下命令查看输出:`mvn -v`
***
### 仓库é…ç½®
默认情况 Maven 本地仓库在系统用户目录下的 `.m2/repository`,修改 Maven çš„é…置文件 `conf/settings.xml` æ¥ä¿®æ”¹ä»“库ä½ç½®
* 修改本地仓库ä½ç½®ï¼šæ‰¾åˆ° æ ‡ç¾ï¼Œä¿®æ”¹é»˜è®¤å€¼
```xml
E:\Workspace\Java\Project\.m2\repository
```
注æ„:在仓库的åŒçº§ç›®å½•å³ `.m2` 也应该包å«ä¸€ä¸ª `settings.xml` é…置文件,局部用户é…置优先与全局é…ç½®
* 全局 setting 定义了 Maven 的公共é…ç½®
* 用户 setting 定义了当å‰ç”¨æˆ·çš„é…ç½®
* 修改远程仓库:在é…置文件ä¸æ‰¾åˆ° `` æ ‡ç¾ï¼Œåœ¨è¿™ç»„æ ‡ç¾ä¸‹æ·»åŠ 国内镜åƒ
```xml
nexus-aliyun
central
Nexus aliyun
http://maven.aliyun.com/nexus/content/groups/public
```
* 修改默认 JDK:在é…置文件ä¸æ‰¾åˆ° `` æ ‡ç¾ï¼Œæ·»åŠ é…ç½®
```xml
jdk-10
true
10
UTF-8
10
10
```
***
## 项目æ建
### 手动æ建
1. 在 E 盘下创建目录 mvnproject 进入该目录,作为我们的æ“作目录
2. 创建我们的 Maven 项目,创建一个目录 `project-java` 作为我们的项目文件夹,并进入到该目录
3. 创建 Java 代ç (æºä»£ç )所在目录,å³åˆ›å»º `src/main/java`
4. 创建é…置文件所在目录,å³åˆ›å»º `src/main/resources`
5. 创建测试æºä»£ç 所在目录,å³åˆ›å»º `src/test/java`
6. 创建测试å˜æ”¾é…置文件å˜æ”¾ç›®å½•ï¼Œå³ `src/test/resources`
7. 在 `src/main/java` ä¸åˆ›å»ºä¸€ä¸ªåŒ…(注æ„在 Windos 文件夹下就是创建目录)`demo`,在该目录下创建 `Demo.java` 文件,作为演示所需 Java 程åºï¼Œå†…容如下
```java
package demo;
public class Demo{
public String say(String name){
System.out.println("hello "+name);
return "hello "+name;
}
}
```
8. 在 `src/test/java` ä¸åˆ›å»ºä¸€ä¸ªæµ‹è¯•åŒ…(目录)`demo`ï¼Œåœ¨è¯¥åŒ…ä¸‹åˆ›å»ºæµ‹è¯•ç¨‹åº `DemoTest.java`
```java
package demo;
import org.junit.*;
public class DemoTest{
@Test
public void testSay(){
Demo d = new Demo();
String ret = d.say("maven");
Assert.assertEquals("hello maven",ret);
}
}
```
9. **在 `project-java/src` 下创建 `pom.xml` æ–‡ä»¶ï¼Œæ ¼å¼å¦‚下:**
```xml
4.0.0
jar
demo
project-java
1.0
junit
junit
4.12
```
10. æå»ºå®Œæˆ Maven 的项目结构,通过 Maven æ¥æž„建项目。Maven 的构建命令以 `mvn` 开头,åŽé¢æ·»åŠ 功能å‚数,å¯ä»¥ä¸€æ¬¡æ€§æ‰§è¡Œå¤šä¸ªå‘½ä»¤ï¼Œç”¨ç©ºæ ¼åˆ†ç¦»
* `mvn compile`:编译
* `mvn clean`:清ç†
* `mvn test`:测试
* `mvn package`:打包
* `mvn install`:安装到本地仓库
注æ„:执行æŸä¸€æ¡å‘½ä»¤ï¼Œåˆ™ä¼šæŠŠå‰é¢æ‰€æœ‰çš„都执行一é
***
### æ’件构建

***
### IDEAæ建
#### ä¸ç”¨åŽŸåž‹
1. 在 IDEA ä¸é…ç½® Maven,选择 maven3.6.1 防æ¢ä¾èµ–问题
 2. 创建 Maven,New Module → Maven → ä¸é€‰ä¸ Create from archetype
3. 填写项目的åæ ‡
* GroupId:demo
* ArtifactId:project-java
4. 查看å„ç›®å½•é¢œè‰²æ ‡è®°æ˜¯å¦æ£ç¡®
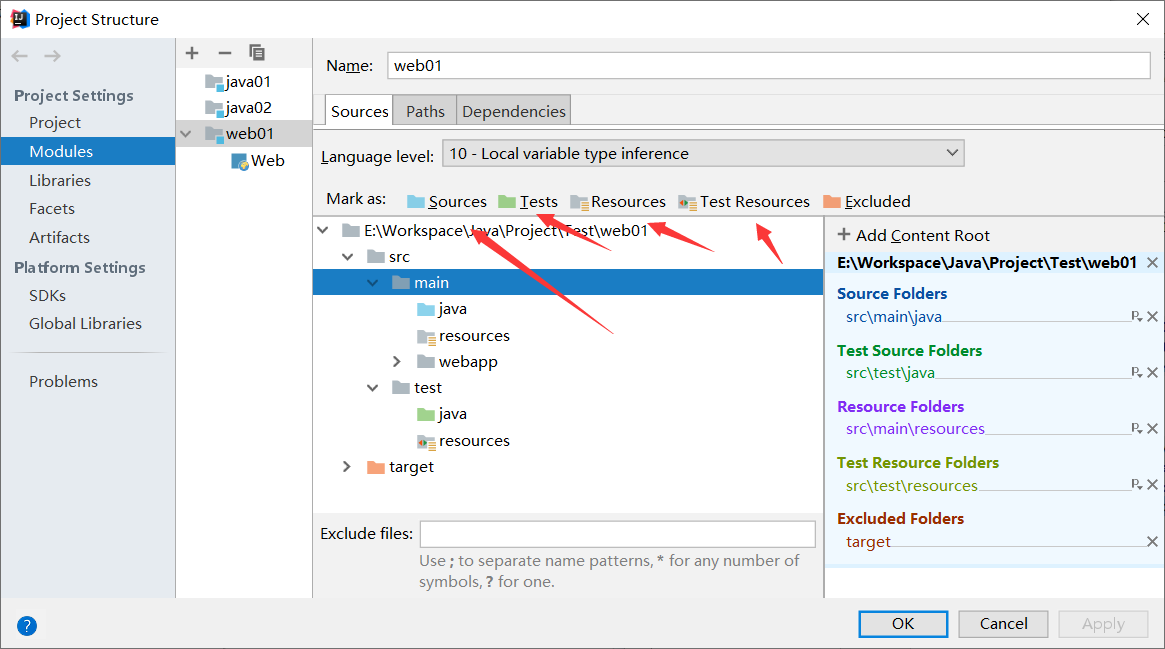
5. IDEA å³ä¾§ä¾§æ 有 Maven Project,打开åŽæœ‰ Lifecycle 生命周期
6. 自定义 Maven 命令:Run → Edit Configurations → 左上角 + → Maven

***
#### 使用原型
普通工程:
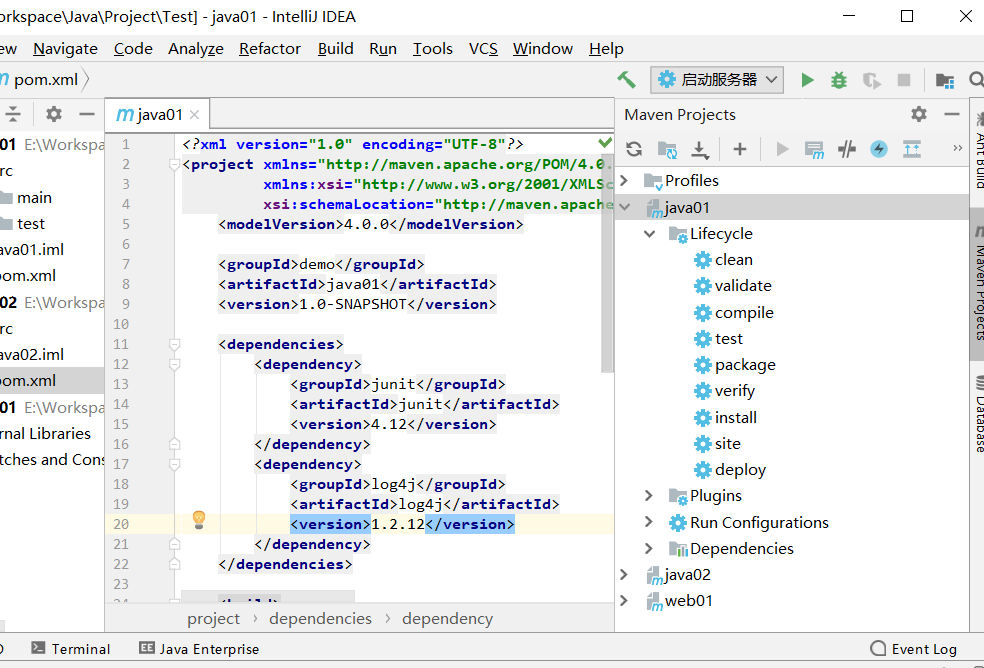
1. 创建 Maven 项目的时候选择使用原型骨架
2. 创建完æˆåŽå‘现通过这ç§æ–¹å¼ç¼ºå°‘一些目录,需è¦æ‰‹åŠ¨åŽ»è¡¥å…¨ç›®å½•ï¼Œå¹¶ä¸”è¦å¯¹è¡¥å…¨çš„ç›®å½•è¿›è¡Œæ ‡è®°
Web 工程:
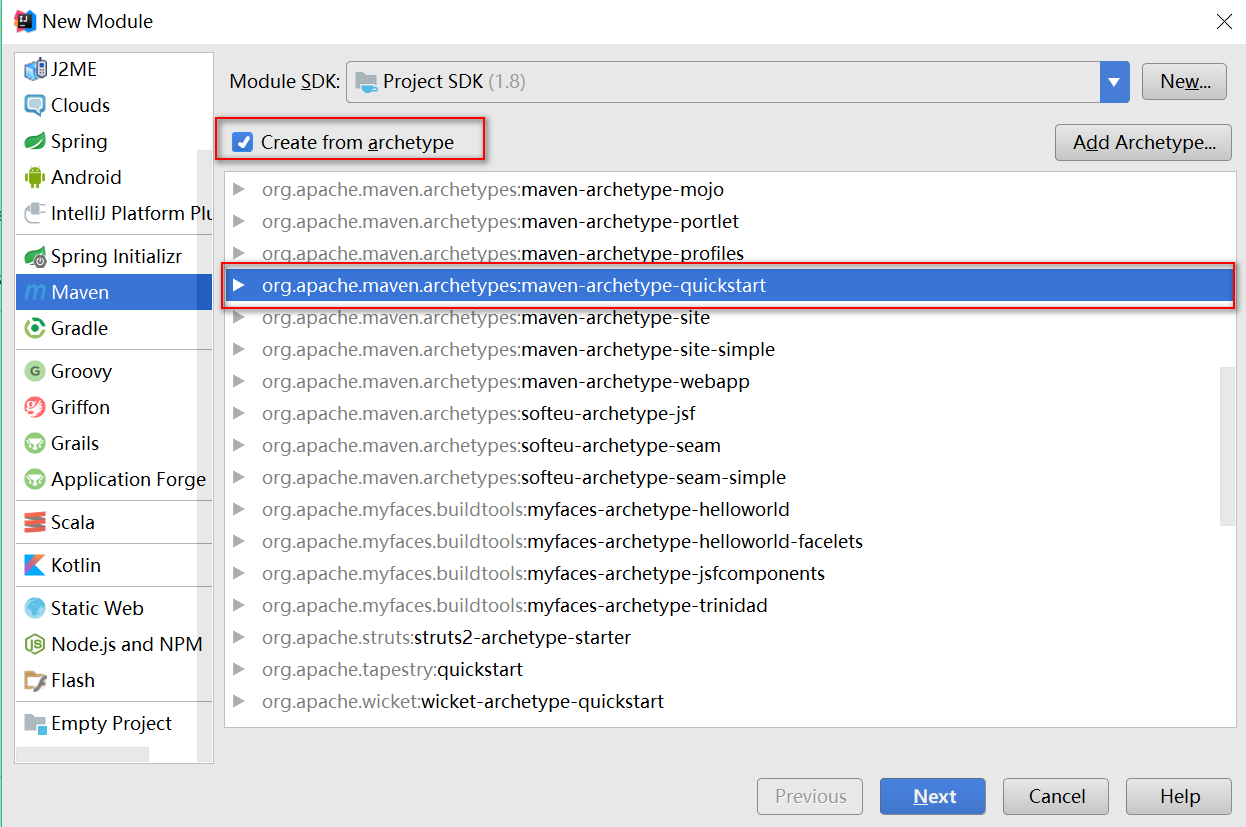
1. 选择 Web 对应的原型骨架(选择 Maven 开头的是简化的)
2. 通过原型创建 Web 项目得到的目录结构是ä¸å…¨çš„ï¼Œå› æ¤éœ€è¦æˆ‘们自行补全,åŒæ—¶è¦æ ‡è®°æ£ç¡®
3. Web 工程创建之åŽéœ€è¦å¯åŠ¨è¿è¡Œï¼Œä½¿ç”¨ tomcat æ’件æ¥è¿è¡Œé¡¹ç›®ï¼Œåœ¨ `pom.xml` ä¸æ·»åŠ æ’件的åæ ‡ï¼š
```xml
4.0.0
war
web01
demo
web01
1.0-SNAPSHOT
org.apache.tomcat.maven
tomcat7-maven-plugin
2.1
80
/
```
4. æ’件é…置以åŽï¼Œåœ¨ IDEA å³ä¾§ `maven-project` æ“作é¢æ¿çœ‹åˆ°è¯¥æ’件,并且å¯ä»¥åˆ©ç”¨è¯¥æ’件å¯åŠ¨é¡¹ç›®ï¼Œweb01 → Plugins → tomcat7 → tomcat7:run
***
## ä¾èµ–管ç†
### ä¾èµ–é…ç½®
ä¾èµ–是指在当å‰é¡¹ç›®ä¸è¿è¡Œæ‰€éœ€çš„ jar,ä¾èµ–é…ç½®çš„æ ¼å¼å¦‚下:
```xml
junit
junit
4.12
```
***
### ä¾èµ–ä¼ é€’
ä¾èµ–å…·æœ‰ä¼ é€’æ€§ï¼Œåˆ†ä¸¤ç§ï¼š
* 直接ä¾èµ–:在当å‰é¡¹ç›®ä¸é€šè¿‡ä¾èµ–é…置建立的ä¾èµ–关系
* 间接ä¾èµ–:被ä¾èµ–的资æºå¦‚æžœä¾èµ–其他资æºï¼Œåˆ™è¡¨æ˜Žå½“å‰é¡¹ç›®é—´æŽ¥ä¾èµ–其他资æº
注æ„:直接ä¾èµ–和间接ä¾èµ–其实也是一个相对关系
ä¾èµ–ä¼ é€’çš„å†²çªé—®é¢˜ï¼šåœ¨ä¾èµ–ä¼ é€’è¿‡ç¨‹ä¸äº§ç”Ÿäº†å†²çªï¼Œæœ‰ä¸‰ç§ä¼˜å…ˆæ³•åˆ™
* 路径优先:当ä¾èµ–ä¸å‡ºçŽ°ç›¸åŒèµ„æºæ—¶ï¼Œå±‚级越深,优先级越低,å之则越高
* 声明优先:当资æºåœ¨ç›¸åŒå±‚级被ä¾èµ–时,é…置顺åºé å‰çš„覆盖é åŽçš„
* 特殊优先:当åŒçº§é…置了相åŒèµ„æºçš„ä¸åŒç‰ˆæœ¬æ—¶ï¼ŒåŽé…置的覆盖先é…置的
**å¯é€‰ä¾èµ–**:对外éšè—当å‰æ‰€ä¾èµ–的资æºï¼Œä¸é€æ˜Ž
```xml
junit
junit
4.11
true
```
**排除ä¾èµ–**:主动æ–å¼€ä¾èµ–的资æºï¼Œè¢«æŽ’除的资æºæ— 需指定版本
```xml
junit
junit
4.12
org.hamcrest
hamcrest-core
```
***
### ä¾èµ–范围
ä¾èµ–çš„ jar 默认情况å¯ä»¥åœ¨ä»»ä½•åœ°æ–¹å¯ç”¨ï¼Œå¯ä»¥é€šè¿‡ `scope` æ ‡ç¾è®¾å®šå…¶ä½œç”¨èŒƒå›´ï¼Œæœ‰ä¸‰ç§ï¼š
* 主程åºèŒƒå›´æœ‰æ•ˆï¼ˆsrc/main 目录范围内)
* 测试程åºèŒƒå›´å†…有效(src/test 目录范围内)
* 是å¦å‚与打包(package 指令范围内)
`scope` æ ‡ç¾çš„å–值有四ç§ï¼š`compile,test,provided,runtime`

**ä¾èµ–èŒƒå›´çš„ä¼ é€’æ€§ï¼š**

***
## 生命周期
### 相关事件
Maven 的构建生命周期æ述的是一次构建过程ç»åŽ†äº†å¤šå°‘个事件
最常用的一套æµç¨‹ï¼šcompile → test-compile → test → package → install
* clean:清ç†å·¥ä½œ
* pre-clean:执行一些在 clean 之å‰çš„工作
* clean:移除上一次构建产生的所有文件
* post-clean:执行一些在 clean 之åŽç«‹åˆ»å®Œæˆçš„工作
* defaultï¼šæ ¸å¿ƒå·¥ä½œï¼Œä¾‹å¦‚ç¼–è¯‘ï¼Œæµ‹è¯•ï¼Œæ‰“åŒ…ï¼Œéƒ¨ç½²ç‰
对于 default 生命周期,æ¯ä¸ªäº‹ä»¶åœ¨æ‰§è¡Œä¹‹å‰éƒ½ä¼š**将之å‰çš„所有事件ä¾æ¬¡æ‰§è¡Œä¸€é**

* site:产生报告,å‘布站点ç‰
* pre-site:执行一些在生æˆç«™ç‚¹æ–‡æ¡£ä¹‹å‰çš„工作
* site:生æˆé¡¹ç›®çš„站点文档
* post-site:执行一些在生æˆç«™ç‚¹æ–‡æ¡£ä¹‹åŽå®Œæˆçš„工作,并为部署åšå‡†å¤‡
* site-deploy:将生æˆçš„站点文档部署到特定的æœåŠ¡å™¨ä¸Š
***
### 执行事件
Maven çš„æ’件用æ¥æ‰§è¡Œç”Ÿå‘½å‘¨æœŸä¸çš„相关事件
- æ’件与生命周期内的阶段绑定,在执行到对应生命周期时执行对应的æ’件
- Maven 默认在å„个生命周期上都绑定了预先设定的æ’件æ¥å®Œæˆç›¸åº”功能
- æ’件还å¯ä»¥å®Œæˆä¸€äº›è‡ªå®šä¹‰åŠŸèƒ½
```xml
org.apache.maven.plugins
maven-source-plugin
2.2.1
jar
test-jar
generate-test-resources
```
***
## 模å—å¼€å‘
### 拆分
工程模å—与模å—划分:

* ssm_pojo 拆分
* 新建模å—,拷è´åŽŸå§‹é¡¹ç›®ä¸å¯¹åº”的相关内容到 ssm_pojo 模å—ä¸
* 实体类(User)
* é…ç½®æ–‡ä»¶ï¼ˆæ— ï¼‰
* ssm_dao 拆分
* 新建模å—
* æ‹·è´åŽŸå§‹é¡¹ç›®ä¸å¯¹åº”的相关内容到 ssm_dao 模å—ä¸
- æ•°æ®å±‚接å£ï¼ˆUserDao)
- é…置文件:ä¿ç•™ä¸Žæ•°æ®å±‚相关é…置文件(3 个)
- 注æ„:分页æ’件在é…ç½®ä¸ä¸Ž SqlSessionFactoryBean 绑定,需è¦ä¿ç•™
- pom.xml:引入数æ®å±‚相关åæ ‡å³å¯ï¼Œåˆ 除 SpringMVC 相关åæ ‡
- Spring
- MyBatis
- Spring æ•´åˆ MyBatis
- MySQL
- druid
- pagehelper
- 直接ä¾èµ– ssm_pojo(对 ssm_pojo 模å—执行 install 指令,将其安装到本地仓库)
```xml
demo
ssm_pojo
1.0-SNAPSHOT
```
* ssm_service 拆分
* 新建模å—
* æ‹·è´åŽŸå§‹é¡¹ç›®ä¸å¯¹åº”的相关内容到 ssm_service 模å—ä¸
- 业务层接å£ä¸Žå®žçŽ°ç±»ï¼ˆUserServiceã€UserServiceImpl)
- é…置文件:ä¿ç•™ä¸Žæ•°æ®å±‚相关é…置文件(1 个)
- pom.xml:引入数æ®å±‚相关åæ ‡å³å¯ï¼Œåˆ 除 SpringMVC 相关åæ ‡
- spring
- junit
- spring æ•´åˆ junit
- 直接ä¾èµ– ssm_dao(对 ssm_dao 模å—执行 install 指令,将其安装到本地仓库)
- 间接ä¾èµ– ssm_pojo(由 ssm_dao 模å—è´Ÿè´£ä¾èµ–关系的建立)
- 修改 service æ¨¡å— Spring æ ¸å¿ƒé…置文件åï¼Œæ·»åŠ æ¨¡å—åç§°ï¼Œæ ¼å¼ï¼šapplicationContext-service.xml
- 修改 dao æ¨¡å— Spring æ ¸å¿ƒé…置文件åï¼Œæ·»åŠ æ¨¡å—åç§°ï¼Œæ ¼å¼ï¼šapplicationContext-dao.xml
- 修改å•å…ƒæµ‹è¯•å¼•å…¥çš„é…置文件å称,由å•ä¸ªæ–‡ä»¶ä¿®æ”¹ä¸ºå¤šä¸ªæ–‡ä»¶
* ssm_control 拆分
* 新建模å—(使用 webapp 模æ¿ï¼‰
* æ‹·è´åŽŸå§‹é¡¹ç›®ä¸å¯¹åº”的相关内容到 ssm_controller 模å—ä¸
- 现层控制器类与相关设置类(UserControllerã€å¼‚常相关……)
- é…置文件:ä¿ç•™ä¸Žè¡¨çŽ°å±‚相关é…置文件(1 个)ã€æœåŠ¡å™¨ç›¸å…³é…置文件(1 个)
- pom.xml:引入数æ®å±‚相关åæ ‡å³å¯ï¼Œåˆ 除 SpringMVC 相关åæ ‡
- spring
- springmvc
- jackson
- servlet
- tomcat æœåŠ¡å™¨æ’件
- 直接ä¾èµ– ssm_service(对 ssm_service 模å—执行 install 指令,将其安装到本地仓库)
- 间接ä¾èµ– ssm_daoã€ssm_pojo
```xml
demo
ssm_service
1.0-SNAPSHOT
```
- 修改 web.xml é…置文件ä¸åŠ è½½ Spring 环境的é…置文件å称,使用*通é…ï¼ŒåŠ è½½æ‰€æœ‰ applicationContext- 开始的é…置文件:
```xml
contextConfigLocation
classpath*:applicationContext-*.xml
```
- spring-mvc
```xml
```
***
### èšåˆ
作用:èšåˆç”¨äºŽå¿«é€Ÿæž„建 Maven 工程,一次性构建多个项目/模å—
制作方å¼ï¼š
- 创建一个空模å—,打包类型定义为 pom
```xml
pom
```
- 定义当å‰æ¨¡å—进行构建æ“作时关è”的其他模å—å称
```xml
4.0.0
demo
ssm
1.0-SNAPSHOT
pom
../ssm_pojo
../ssm_dao
../ssm_service
../ssm_controller
```
注æ„事项:å‚与èšåˆæ“作的模å—最终执行顺åºä¸Žæ¨¡å—é—´çš„ä¾èµ–关系有关,与é…置顺åºæ— å…³
***
### 继承
作用:通过继承å¯ä»¥å®žçŽ°åœ¨å工程ä¸æ²¿ç”¨çˆ¶å·¥ç¨‹ä¸çš„é…ç½®
- Maven ä¸çš„继承与 Java ä¸çš„继承相似,在å工程ä¸é…置继承关系
制作方å¼ï¼š
- 在å工程ä¸å£°æ˜Žå…¶çˆ¶å·¥ç¨‹åæ ‡ä¸Žå¯¹åº”çš„ä½ç½®
```xml
com.seazean
ssm
1.0-SNAPSHOT
../ssm/pom.xml
```
- 继承ä¾èµ–的定义:在父工程ä¸å®šä¹‰ä¾èµ–管ç†
```xml
org.springframework
spring-context
5.1.9.RELEASE
```
- 继承ä¾èµ–的使用:在å工程ä¸å®šä¹‰ä¾èµ–关系,**æ— éœ€å£°æ˜Žä¾èµ–版本**,版本å‚照父工程ä¸ä¾èµ–的版本
```xml
org.springframework
spring-context
```
- 继承的资æºï¼š
```xml
groupId:项目组ID,项目åæ ‡çš„æ ¸å¿ƒå…ƒç´
version:项目版本,项目åæ ‡çš„æ ¸å¿ƒå› ç´
description:项目的æè¿°ä¿¡æ¯
organization:项目的组织信æ¯
inceptionYear:项目的创始年份
url:项目的URL地å€
developers:项目的开å‘者信æ¯
contributors:项目的贡献者信æ¯
distributionManagement:项目的部署é…ç½®
issueManagement:项目的缺陷跟踪系统信æ¯
ciManagement:项目的æŒç»é›†æˆç³»ç»Ÿä¿¡æ¯
scm:项目的版本控制系统信æ¯
malilingLists:项目的邮件列表信æ¯
properties:自定义的Maven属性
dependencies:项目的ä¾èµ–é…ç½®
dependencyManagement:项目的ä¾èµ–管ç†é…ç½®
repositories:项目的仓库é…ç½®
build:包括项目的æºç 目录é…ç½®ã€è¾“出目录é…ç½®ã€æ’件é…ç½®ã€æ’件管ç†é…ç½®ç‰
reporting:包括项目的报告输出目录é…ç½®ã€æŠ¥å‘Šæ’件é…ç½®ç‰
```
- 继承与èšåˆï¼š
作用:
- èšåˆç”¨äºŽå¿«é€Ÿæž„建项目
- 继承用于快速é…ç½®
相åŒç‚¹ï¼š
- èšåˆä¸Žç»§æ‰¿çš„ pom.xml 文件打包方å¼å‡ä¸º pom,å¯ä»¥å°†ä¸¤ç§å…³ç³»åˆ¶ä½œåˆ°åŒä¸€ä¸ª pom 文件ä¸
- èšåˆä¸Žç»§æ‰¿å‡å±žäºŽè®¾è®¡åž‹æ¨¡å—ï¼Œå¹¶æ— å®žé™…çš„æ¨¡å—内容
ä¸åŒç‚¹ï¼š
- èšåˆæ˜¯åœ¨å½“å‰æ¨¡å—ä¸é…置关系,èšåˆå¯ä»¥æ„ŸçŸ¥åˆ°å‚与èšåˆçš„模å—有哪些
- 继承是在å模å—ä¸é…置关系,父模å—æ— æ³•æ„ŸçŸ¥å“ªäº›å模å—继承了自己
***
### 属性
* 版本统一的é‡è¦æ€§ï¼š

* 属性类别:
1. 自定义属性
2. 内置属性
3. setting 属性
4. Java 系统属性
5. 环境å˜é‡å±žæ€§
* 自定义属性:
作用:ç‰åŒäºŽå®šä¹‰å˜é‡ï¼Œæ–¹ä¾¿ç»Ÿä¸€ç»´æŠ¤
å®šä¹‰æ ¼å¼ï¼š
```xml
5.1.9.RELEASE
4.12
```
- èšåˆä¸Žç»§æ‰¿çš„ pom.xml 文件打包方å¼å‡ä¸º pom,å¯ä»¥å°†ä¸¤ç§å…³ç³»åˆ¶ä½œåˆ°åŒä¸€ä¸ª pom 文件ä¸
- èšåˆä¸Žç»§æ‰¿å‡å±žäºŽè®¾è®¡åž‹æ¨¡å—ï¼Œå¹¶æ— å®žé™…çš„æ¨¡å—内容
è°ƒç”¨æ ¼å¼ï¼š
```xml
org.springframework
spring-context
${spring.version}
```
* 内置属性:
作用:使用 Maven 内置属性,快速é…ç½®
è°ƒç”¨æ ¼å¼ï¼š
```xml
${project.basedir} or ${project.basedir} ${version} or ${project.version}
```
* vresion 是 1.0-SNAPSHOT
```xml
demo
ssm
1.0-SNAPSHOT
```
* setting 属性
- 使用 Maven é…置文件 setting.xml ä¸çš„æ ‡ç¾å±žæ€§ï¼Œç”¨äºŽåŠ¨æ€é…ç½®
è°ƒç”¨æ ¼å¼ï¼š
```xml
${settings.localRepository}
```
* Java 系统属性:
ä½œç”¨ï¼šè¯»å– Java 系统属性
è°ƒç”¨æ ¼å¼ï¼š
```xml
${user.home}
```
ç³»ç»Ÿå±žæ€§æŸ¥è¯¢æ–¹å¼ cmd 命令:
```sh
mvn help:system
```
* 环境å˜é‡å±žæ€§
作用:使用 Maven é…置文件 setting.xml ä¸çš„æ ‡ç¾å±žæ€§ï¼Œç”¨äºŽåŠ¨æ€é…ç½®
è°ƒç”¨æ ¼å¼ï¼š
```xml
${env.JAVA_HOME}
```
环境å˜é‡å±žæ€§æŸ¥è¯¢æ–¹å¼ï¼š
```sh
mvn help:system
```
***
### 工程版本
SNAPSHOT(快照版本)
- 项目开å‘过程ä¸ï¼Œä¸ºæ–¹ä¾¿å›¢é˜Ÿæˆå‘˜åˆä½œï¼Œè§£å†³æ¨¡å—间相互ä¾èµ–和时时更新的问题,开å‘者对æ¯ä¸ªæ¨¡å—进行构建的时候,输出的临时性版本å«å¿«ç…§ç‰ˆæœ¬ï¼ˆæµ‹è¯•é˜¶æ®µç‰ˆæœ¬ï¼‰
- 快照版本会éšç€å¼€å‘的进展ä¸æ–æ›´æ–°
RELEASE(å‘布版本)
- 项目开å‘到进入阶段里程碑åŽï¼Œå‘团队外部å‘布较为稳定的版本,这ç§ç‰ˆæœ¬æ‰€å¯¹åº”的构件文件是稳定的,å³ä¾¿è¿›è¡ŒåŠŸèƒ½çš„åŽç»å¼€å‘,也ä¸ä¼šæ”¹å˜å½“å‰å‘布版本内容,这ç§ç‰ˆæœ¬ç§°ä¸ºå‘布版本
约定规范:
- <主版本>.<次版本>.<增é‡ç‰ˆæœ¬>.<里程碑版本>
- 主版本:表示项目é‡å¤§æž¶æž„çš„å˜æ›´ï¼Œå¦‚:Spring5 相较于 Spring4 çš„è¿ä»£
- æ¬¡ç‰ˆæœ¬ï¼šè¡¨ç¤ºæœ‰è¾ƒå¤§çš„åŠŸèƒ½å¢žåŠ å’Œå˜åŒ–,或者全é¢ç³»ç»Ÿåœ°ä¿®å¤æ¼æ´ž
- 增é‡ç‰ˆæœ¬ï¼šè¡¨ç¤ºæœ‰é‡å¤§æ¼æ´žçš„ä¿®å¤
- é‡Œç¨‹ç¢‘ç‰ˆæœ¬ï¼šè¡¨æ˜Žä¸€ä¸ªç‰ˆæœ¬çš„é‡Œç¨‹ç¢‘ï¼ˆç‰ˆæœ¬å†…éƒ¨ï¼‰ã€‚è¿™æ ·çš„ç‰ˆæœ¬åŒä¸‹ä¸€ä¸ªæ£å¼ç‰ˆæœ¬ç›¸æ¯”,相对æ¥è¯´ä¸æ˜¯å¾ˆç¨³å®šï¼Œæœ‰å¾…更多的测试
***
### 资æºé…ç½®
作用:在任æ„é…置文件ä¸åŠ è½½ pom 文件ä¸å®šä¹‰çš„属性
* 父文件 pom.xml
```xml
jdbc:mysql://192.168.0.137:3306/ssm_db?useSSL=false
```
- å¼€å¯é…ç½®æ–‡ä»¶åŠ è½½ pom 属性:
```xml
${project.basedir}/src/main/resources
true
```
* properties 文件ä¸è°ƒç”¨æ ¼å¼ï¼š
```properties
jdbc.driver=com.mysql.jdbc.Driverjdbc.url=${jdbc.url}
jdbc.username=rootjdbc.password=123456
```
***
### 多环境é…ç½®
* 环境é…ç½®
```xml
pro_env
jdbc:mysql://127.1.1.1:3306/ssm_db
true
dev_env
……
```
* åŠ è½½æŒ‡å®šçŽ¯å¢ƒ
ä½œç”¨ï¼šåŠ è½½æŒ‡å®šçŽ¯å¢ƒé…ç½®
è°ƒç”¨æ ¼å¼ï¼š
```sh
mvn 指令 –P 环境定义id
```
范例:
```sh
mvn install –P pro_env
```
***
## 跳过测试
命令:
```sh
mvn 指令 –D skipTests
```
注æ„事项:执行的指令生命周期必须包å«æµ‹è¯•çŽ¯èŠ‚
IEDA ç•Œé¢ï¼š

é…置跳过:
```xml
maven-surefire-plugin
2.22.1
true
**/User*Test.java
**/User*TestCase.java
```
***
## ç§æœ
### Nexus
Nexus 是 Sonatype å…¬å¸çš„一款 Maven ç§æœäº§å“
下载地å€ï¼šhttps://help.sonatype.com/repomanager3/download
å¯åŠ¨æœåŠ¡å™¨ï¼ˆå‘½ä»¤è¡Œå¯åŠ¨ï¼‰ï¼š
```sh
nexus.exe /run nexus
```
访问æœåŠ¡å™¨ï¼ˆé»˜è®¤ç«¯å£ï¼š8081):
```sh
http://localhost:8081
```
修改基础é…置信æ¯
- 安装路径下 etc ç›®å½•ä¸ nexus-default.properties 文件ä¿å˜æœ‰ nexus 基础é…置信æ¯ï¼Œä¾‹å¦‚默认访问端å£
修改æœåŠ¡å™¨è¿è¡Œé…置信æ¯
- 安装路径下 bin ç›®å½•ä¸ nexus.vmoptions 文件ä¿å˜æœ‰ nexus æœåŠ¡å™¨å¯åŠ¨çš„é…置信æ¯ï¼Œä¾‹å¦‚默认å 用内å˜ç©ºé—´
***
### 资æºæ“作

仓库分类:
* 宿主仓库 hosted
* ä¿å˜æ— 法从ä¸å¤®ä»“库获å–的资æº
* è‡ªä¸»ç ”å‘
* 第三方éžå¼€æºé¡¹ç›®
* 代ç†ä»“库 proxy
* 代ç†è¿œç¨‹ä»“库,通过 nexus 访问其他公共仓库,例如ä¸å¤®ä»“库
* 仓库组 group
* 将若干个仓库组æˆä¸€ä¸ªç¾¤ç»„,简化é…ç½®
* 仓库组ä¸èƒ½ä¿å˜èµ„æºï¼Œå±žäºŽè®¾è®¡åž‹ä»“库
资æºä¸Šä¼ ï¼Œä¸Šä¼ èµ„æºæ—¶æ供对应的信æ¯
- ä¿å˜çš„ä½ç½®ï¼ˆå®¿ä¸»ä»“库)
- 资æºæ–‡ä»¶
- 对应åæ ‡
***
### IDEAæ“作
#### ä¸Šä¼ ä¸‹è½½

***
#### 访问ç§æœ
##### 本地访问
é…置本地仓库访问ç§æœçš„æƒé™ï¼ˆsetting.xml)
```xml
heima-release
admin
admin
heima-snapshots
admin
admin
```
é…置本地仓库资æºæ¥æºï¼ˆsetting.xml)
```xml
nexus-heima
*
http://localhost:8081/repository/maven-public/
```
***
##### 工程访问
é…置当å‰é¡¹ç›®è®¿é—®ç§æœä¸Šä¼ 资æºçš„ä¿å˜ä½ç½®ï¼ˆpom.xml)
```xml
heima-release
http://localhost:8081/repository/heima-release/
heima-snapshots
http://localhost:8081/repository/heima-snapshots/
```
å‘布资æºåˆ°ç§æœå‘½ä»¤
```sh
mvn deploy
```
***
## 日志
### Log4j
程åºä¸çš„日志å¯ä»¥ç”¨æ¥è®°å½•ç¨‹åºåœ¨è¿è¡Œæ—¶å€™çš„详情,并å¯ä»¥è¿›è¡Œæ°¸ä¹…å˜å‚¨ã€‚
| | 输出è¯å¥ | 日志技术 |
| -------- | -------------------------- | ---------------------------------------- |
| å–消日志 | 需è¦ä¿®æ”¹ä»£ç ,çµæ´»æ€§æ¯”较差 | ä¸éœ€è¦ä¿®æ”¹ä»£ç ,çµæ´»æ€§æ¯”较好 |
| 输出ä½ç½® | åªèƒ½æ˜¯æŽ§åˆ¶å° | å¯ä»¥å°†æ—¥å¿—ä¿¡æ¯å†™å…¥åˆ°æ–‡ä»¶æˆ–者数æ®åº“ä¸ |
| 多线程 | 和业务代ç å¤„äºŽä¸€ä¸ªçº¿ç¨‹ä¸ | 多线程方å¼è®°å½•æ—¥å¿—,ä¸å½±å“业务代ç 的性能 |
Log4j 是 Apache 的一个开æºé¡¹ç›®ã€‚使用 Log4j,通过一个é…置文件æ¥çµæ´»åœ°è¿›è¡Œé…置,而ä¸éœ€è¦ä¿®æ”¹åº”用的代ç 。我们å¯ä»¥æŽ§åˆ¶æ—¥å¿—ä¿¡æ¯è¾“é€çš„目的地是控制å°ã€æ–‡ä»¶ç‰ä½ç½®ï¼Œä¹Ÿå¯ä»¥æŽ§åˆ¶æ¯ä¸€æ¡æ—¥å¿—çš„è¾“å‡ºæ ¼å¼ã€‚
2. 创建 Maven,New Module → Maven → ä¸é€‰ä¸ Create from archetype
3. 填写项目的åæ ‡
* GroupId:demo
* ArtifactId:project-java
4. 查看å„ç›®å½•é¢œè‰²æ ‡è®°æ˜¯å¦æ£ç¡®

5. IDEA å³ä¾§ä¾§æ 有 Maven Project,打开åŽæœ‰ Lifecycle 生命周期

6. 自定义 Maven 命令:Run → Edit Configurations → 左上角 + → Maven

***
#### 使用原型
普通工程:
1. 创建 Maven 项目的时候选择使用原型骨架

2. 创建完æˆåŽå‘现通过这ç§æ–¹å¼ç¼ºå°‘一些目录,需è¦æ‰‹åŠ¨åŽ»è¡¥å…¨ç›®å½•ï¼Œå¹¶ä¸”è¦å¯¹è¡¥å…¨çš„ç›®å½•è¿›è¡Œæ ‡è®°
Web 工程:
1. 选择 Web 对应的原型骨架(选择 Maven 开头的是简化的)

2. 通过原型创建 Web 项目得到的目录结构是ä¸å…¨çš„ï¼Œå› æ¤éœ€è¦æˆ‘们自行补全,åŒæ—¶è¦æ ‡è®°æ£ç¡®
3. Web 工程创建之åŽéœ€è¦å¯åŠ¨è¿è¡Œï¼Œä½¿ç”¨ tomcat æ’件æ¥è¿è¡Œé¡¹ç›®ï¼Œåœ¨ `pom.xml` ä¸æ·»åŠ æ’件的åæ ‡ï¼š
```xml
4.0.0
war
web01
demo
web01
1.0-SNAPSHOT
org.apache.tomcat.maven
tomcat7-maven-plugin
2.1
80
/
```
4. æ’件é…置以åŽï¼Œåœ¨ IDEA å³ä¾§ `maven-project` æ“作é¢æ¿çœ‹åˆ°è¯¥æ’件,并且å¯ä»¥åˆ©ç”¨è¯¥æ’件å¯åŠ¨é¡¹ç›®ï¼Œweb01 → Plugins → tomcat7 → tomcat7:run
***
## ä¾èµ–管ç†
### ä¾èµ–é…ç½®
ä¾èµ–是指在当å‰é¡¹ç›®ä¸è¿è¡Œæ‰€éœ€çš„ jar,ä¾èµ–é…ç½®çš„æ ¼å¼å¦‚下:
```xml
junit
junit
4.12
```
***
### ä¾èµ–ä¼ é€’
ä¾èµ–å…·æœ‰ä¼ é€’æ€§ï¼Œåˆ†ä¸¤ç§ï¼š
* 直接ä¾èµ–:在当å‰é¡¹ç›®ä¸é€šè¿‡ä¾èµ–é…置建立的ä¾èµ–关系
* 间接ä¾èµ–:被ä¾èµ–的资æºå¦‚æžœä¾èµ–其他资æºï¼Œåˆ™è¡¨æ˜Žå½“å‰é¡¹ç›®é—´æŽ¥ä¾èµ–其他资æº
注æ„:直接ä¾èµ–和间接ä¾èµ–其实也是一个相对关系
ä¾èµ–ä¼ é€’çš„å†²çªé—®é¢˜ï¼šåœ¨ä¾èµ–ä¼ é€’è¿‡ç¨‹ä¸äº§ç”Ÿäº†å†²çªï¼Œæœ‰ä¸‰ç§ä¼˜å…ˆæ³•åˆ™
* 路径优先:当ä¾èµ–ä¸å‡ºçŽ°ç›¸åŒèµ„æºæ—¶ï¼Œå±‚级越深,优先级越低,å之则越高
* 声明优先:当资æºåœ¨ç›¸åŒå±‚级被ä¾èµ–时,é…置顺åºé å‰çš„覆盖é åŽçš„
* 特殊优先:当åŒçº§é…置了相åŒèµ„æºçš„ä¸åŒç‰ˆæœ¬æ—¶ï¼ŒåŽé…置的覆盖先é…置的
**å¯é€‰ä¾èµ–**:对外éšè—当å‰æ‰€ä¾èµ–的资æºï¼Œä¸é€æ˜Ž
```xml
junit
junit
4.11
true
```
**排除ä¾èµ–**:主动æ–å¼€ä¾èµ–的资æºï¼Œè¢«æŽ’除的资æºæ— 需指定版本
```xml
junit
junit
4.12
org.hamcrest
hamcrest-core
```
***
### ä¾èµ–范围
ä¾èµ–çš„ jar 默认情况å¯ä»¥åœ¨ä»»ä½•åœ°æ–¹å¯ç”¨ï¼Œå¯ä»¥é€šè¿‡ `scope` æ ‡ç¾è®¾å®šå…¶ä½œç”¨èŒƒå›´ï¼Œæœ‰ä¸‰ç§ï¼š
* 主程åºèŒƒå›´æœ‰æ•ˆï¼ˆsrc/main 目录范围内)
* 测试程åºèŒƒå›´å†…有效(src/test 目录范围内)
* 是å¦å‚与打包(package 指令范围内)
`scope` æ ‡ç¾çš„å–值有四ç§ï¼š`compile,test,provided,runtime`

**ä¾èµ–èŒƒå›´çš„ä¼ é€’æ€§ï¼š**

***
## 生命周期
### 相关事件
Maven 的构建生命周期æ述的是一次构建过程ç»åŽ†äº†å¤šå°‘个事件
最常用的一套æµç¨‹ï¼šcompile → test-compile → test → package → install
* clean:清ç†å·¥ä½œ
* pre-clean:执行一些在 clean 之å‰çš„工作
* clean:移除上一次构建产生的所有文件
* post-clean:执行一些在 clean 之åŽç«‹åˆ»å®Œæˆçš„工作
* defaultï¼šæ ¸å¿ƒå·¥ä½œï¼Œä¾‹å¦‚ç¼–è¯‘ï¼Œæµ‹è¯•ï¼Œæ‰“åŒ…ï¼Œéƒ¨ç½²ç‰
对于 default 生命周期,æ¯ä¸ªäº‹ä»¶åœ¨æ‰§è¡Œä¹‹å‰éƒ½ä¼š**将之å‰çš„所有事件ä¾æ¬¡æ‰§è¡Œä¸€é**

* site:产生报告,å‘布站点ç‰
* pre-site:执行一些在生æˆç«™ç‚¹æ–‡æ¡£ä¹‹å‰çš„工作
* site:生æˆé¡¹ç›®çš„站点文档
* post-site:执行一些在生æˆç«™ç‚¹æ–‡æ¡£ä¹‹åŽå®Œæˆçš„工作,并为部署åšå‡†å¤‡
* site-deploy:将生æˆçš„站点文档部署到特定的æœåŠ¡å™¨ä¸Š
***
### 执行事件
Maven çš„æ’件用æ¥æ‰§è¡Œç”Ÿå‘½å‘¨æœŸä¸çš„相关事件
- æ’件与生命周期内的阶段绑定,在执行到对应生命周期时执行对应的æ’件
- Maven 默认在å„个生命周期上都绑定了预先设定的æ’件æ¥å®Œæˆç›¸åº”功能
- æ’件还å¯ä»¥å®Œæˆä¸€äº›è‡ªå®šä¹‰åŠŸèƒ½
```xml
org.apache.maven.plugins
maven-source-plugin
2.2.1
jar
test-jar
generate-test-resources
```
***
## 模å—å¼€å‘
### 拆分
工程模å—与模å—划分:

* ssm_pojo 拆分
* 新建模å—,拷è´åŽŸå§‹é¡¹ç›®ä¸å¯¹åº”的相关内容到 ssm_pojo 模å—ä¸
* 实体类(User)
* é…ç½®æ–‡ä»¶ï¼ˆæ— ï¼‰
* ssm_dao 拆分
* 新建模å—
* æ‹·è´åŽŸå§‹é¡¹ç›®ä¸å¯¹åº”的相关内容到 ssm_dao 模å—ä¸
- æ•°æ®å±‚接å£ï¼ˆUserDao)
- é…置文件:ä¿ç•™ä¸Žæ•°æ®å±‚相关é…置文件(3 个)
- 注æ„:分页æ’件在é…ç½®ä¸ä¸Ž SqlSessionFactoryBean 绑定,需è¦ä¿ç•™
- pom.xml:引入数æ®å±‚相关åæ ‡å³å¯ï¼Œåˆ 除 SpringMVC 相关åæ ‡
- Spring
- MyBatis
- Spring æ•´åˆ MyBatis
- MySQL
- druid
- pagehelper
- 直接ä¾èµ– ssm_pojo(对 ssm_pojo 模å—执行 install 指令,将其安装到本地仓库)
```xml
demo
ssm_pojo
1.0-SNAPSHOT
```
* ssm_service 拆分
* 新建模å—
* æ‹·è´åŽŸå§‹é¡¹ç›®ä¸å¯¹åº”的相关内容到 ssm_service 模å—ä¸
- 业务层接å£ä¸Žå®žçŽ°ç±»ï¼ˆUserServiceã€UserServiceImpl)
- é…置文件:ä¿ç•™ä¸Žæ•°æ®å±‚相关é…置文件(1 个)
- pom.xml:引入数æ®å±‚相关åæ ‡å³å¯ï¼Œåˆ 除 SpringMVC 相关åæ ‡
- spring
- junit
- spring æ•´åˆ junit
- 直接ä¾èµ– ssm_dao(对 ssm_dao 模å—执行 install 指令,将其安装到本地仓库)
- 间接ä¾èµ– ssm_pojo(由 ssm_dao 模å—è´Ÿè´£ä¾èµ–关系的建立)
- 修改 service æ¨¡å— Spring æ ¸å¿ƒé…置文件åï¼Œæ·»åŠ æ¨¡å—åç§°ï¼Œæ ¼å¼ï¼šapplicationContext-service.xml
- 修改 dao æ¨¡å— Spring æ ¸å¿ƒé…置文件åï¼Œæ·»åŠ æ¨¡å—åç§°ï¼Œæ ¼å¼ï¼šapplicationContext-dao.xml
- 修改å•å…ƒæµ‹è¯•å¼•å…¥çš„é…置文件å称,由å•ä¸ªæ–‡ä»¶ä¿®æ”¹ä¸ºå¤šä¸ªæ–‡ä»¶
* ssm_control 拆分
* 新建模å—(使用 webapp 模æ¿ï¼‰
* æ‹·è´åŽŸå§‹é¡¹ç›®ä¸å¯¹åº”的相关内容到 ssm_controller 模å—ä¸
- 现层控制器类与相关设置类(UserControllerã€å¼‚常相关……)
- é…置文件:ä¿ç•™ä¸Žè¡¨çŽ°å±‚相关é…置文件(1 个)ã€æœåŠ¡å™¨ç›¸å…³é…置文件(1 个)
- pom.xml:引入数æ®å±‚相关åæ ‡å³å¯ï¼Œåˆ 除 SpringMVC 相关åæ ‡
- spring
- springmvc
- jackson
- servlet
- tomcat æœåŠ¡å™¨æ’件
- 直接ä¾èµ– ssm_service(对 ssm_service 模å—执行 install 指令,将其安装到本地仓库)
- 间接ä¾èµ– ssm_daoã€ssm_pojo
```xml
demo
ssm_service
1.0-SNAPSHOT
```
- 修改 web.xml é…置文件ä¸åŠ è½½ Spring 环境的é…置文件å称,使用*通é…ï¼ŒåŠ è½½æ‰€æœ‰ applicationContext- 开始的é…置文件:
```xml
contextConfigLocation
classpath*:applicationContext-*.xml
```
- spring-mvc
```xml
```
***
### èšåˆ
作用:èšåˆç”¨äºŽå¿«é€Ÿæž„建 Maven 工程,一次性构建多个项目/模å—
制作方å¼ï¼š
- 创建一个空模å—,打包类型定义为 pom
```xml
pom
```
- 定义当å‰æ¨¡å—进行构建æ“作时关è”的其他模å—å称
```xml
4.0.0
demo
ssm
1.0-SNAPSHOT
pom
../ssm_pojo
../ssm_dao
../ssm_service
../ssm_controller
```
注æ„事项:å‚与èšåˆæ“作的模å—最终执行顺åºä¸Žæ¨¡å—é—´çš„ä¾èµ–关系有关,与é…置顺åºæ— å…³
***
### 继承
作用:通过继承å¯ä»¥å®žçŽ°åœ¨å工程ä¸æ²¿ç”¨çˆ¶å·¥ç¨‹ä¸çš„é…ç½®
- Maven ä¸çš„继承与 Java ä¸çš„继承相似,在å工程ä¸é…置继承关系
制作方å¼ï¼š
- 在å工程ä¸å£°æ˜Žå…¶çˆ¶å·¥ç¨‹åæ ‡ä¸Žå¯¹åº”çš„ä½ç½®
```xml
com.seazean
ssm
1.0-SNAPSHOT
../ssm/pom.xml
```
- 继承ä¾èµ–的定义:在父工程ä¸å®šä¹‰ä¾èµ–管ç†
```xml
org.springframework
spring-context
5.1.9.RELEASE
```
- 继承ä¾èµ–的使用:在å工程ä¸å®šä¹‰ä¾èµ–关系,**æ— éœ€å£°æ˜Žä¾èµ–版本**,版本å‚照父工程ä¸ä¾èµ–的版本
```xml
org.springframework
spring-context
```
- 继承的资æºï¼š
```xml
groupId:项目组ID,项目åæ ‡çš„æ ¸å¿ƒå…ƒç´
version:项目版本,项目åæ ‡çš„æ ¸å¿ƒå› ç´
description:项目的æè¿°ä¿¡æ¯
organization:项目的组织信æ¯
inceptionYear:项目的创始年份
url:项目的URL地å€
developers:项目的开å‘者信æ¯
contributors:项目的贡献者信æ¯
distributionManagement:项目的部署é…ç½®
issueManagement:项目的缺陷跟踪系统信æ¯
ciManagement:项目的æŒç»é›†æˆç³»ç»Ÿä¿¡æ¯
scm:项目的版本控制系统信æ¯
malilingLists:项目的邮件列表信æ¯
properties:自定义的Maven属性
dependencies:项目的ä¾èµ–é…ç½®
dependencyManagement:项目的ä¾èµ–管ç†é…ç½®
repositories:项目的仓库é…ç½®
build:包括项目的æºç 目录é…ç½®ã€è¾“出目录é…ç½®ã€æ’件é…ç½®ã€æ’件管ç†é…ç½®ç‰
reporting:包括项目的报告输出目录é…ç½®ã€æŠ¥å‘Šæ’件é…ç½®ç‰
```
- 继承与èšåˆï¼š
作用:
- èšåˆç”¨äºŽå¿«é€Ÿæž„建项目
- 继承用于快速é…ç½®
相åŒç‚¹ï¼š
- èšåˆä¸Žç»§æ‰¿çš„ pom.xml 文件打包方å¼å‡ä¸º pom,å¯ä»¥å°†ä¸¤ç§å…³ç³»åˆ¶ä½œåˆ°åŒä¸€ä¸ª pom 文件ä¸
- èšåˆä¸Žç»§æ‰¿å‡å±žäºŽè®¾è®¡åž‹æ¨¡å—ï¼Œå¹¶æ— å®žé™…çš„æ¨¡å—内容
ä¸åŒç‚¹ï¼š
- èšåˆæ˜¯åœ¨å½“å‰æ¨¡å—ä¸é…置关系,èšåˆå¯ä»¥æ„ŸçŸ¥åˆ°å‚与èšåˆçš„模å—有哪些
- 继承是在å模å—ä¸é…置关系,父模å—æ— æ³•æ„ŸçŸ¥å“ªäº›å模å—继承了自己
***
### 属性
* 版本统一的é‡è¦æ€§ï¼š

* 属性类别:
1. 自定义属性
2. 内置属性
3. setting 属性
4. Java 系统属性
5. 环境å˜é‡å±žæ€§
* 自定义属性:
作用:ç‰åŒäºŽå®šä¹‰å˜é‡ï¼Œæ–¹ä¾¿ç»Ÿä¸€ç»´æŠ¤
å®šä¹‰æ ¼å¼ï¼š
```xml
5.1.9.RELEASE
4.12
```
- èšåˆä¸Žç»§æ‰¿çš„ pom.xml 文件打包方å¼å‡ä¸º pom,å¯ä»¥å°†ä¸¤ç§å…³ç³»åˆ¶ä½œåˆ°åŒä¸€ä¸ª pom 文件ä¸
- èšåˆä¸Žç»§æ‰¿å‡å±žäºŽè®¾è®¡åž‹æ¨¡å—ï¼Œå¹¶æ— å®žé™…çš„æ¨¡å—内容
è°ƒç”¨æ ¼å¼ï¼š
```xml
org.springframework
spring-context
${spring.version}
```
* 内置属性:
作用:使用 Maven 内置属性,快速é…ç½®
è°ƒç”¨æ ¼å¼ï¼š
```xml
${project.basedir} or ${project.basedir} ${version} or ${project.version}
```
* vresion 是 1.0-SNAPSHOT
```xml
demo
ssm
1.0-SNAPSHOT
```
* setting 属性
- 使用 Maven é…置文件 setting.xml ä¸çš„æ ‡ç¾å±žæ€§ï¼Œç”¨äºŽåŠ¨æ€é…ç½®
è°ƒç”¨æ ¼å¼ï¼š
```xml
${settings.localRepository}
```
* Java 系统属性:
ä½œç”¨ï¼šè¯»å– Java 系统属性
è°ƒç”¨æ ¼å¼ï¼š
```xml
${user.home}
```
ç³»ç»Ÿå±žæ€§æŸ¥è¯¢æ–¹å¼ cmd 命令:
```sh
mvn help:system
```
* 环境å˜é‡å±žæ€§
作用:使用 Maven é…置文件 setting.xml ä¸çš„æ ‡ç¾å±žæ€§ï¼Œç”¨äºŽåŠ¨æ€é…ç½®
è°ƒç”¨æ ¼å¼ï¼š
```xml
${env.JAVA_HOME}
```
环境å˜é‡å±žæ€§æŸ¥è¯¢æ–¹å¼ï¼š
```sh
mvn help:system
```
***
### 工程版本
SNAPSHOT(快照版本)
- 项目开å‘过程ä¸ï¼Œä¸ºæ–¹ä¾¿å›¢é˜Ÿæˆå‘˜åˆä½œï¼Œè§£å†³æ¨¡å—间相互ä¾èµ–和时时更新的问题,开å‘者对æ¯ä¸ªæ¨¡å—进行构建的时候,输出的临时性版本å«å¿«ç…§ç‰ˆæœ¬ï¼ˆæµ‹è¯•é˜¶æ®µç‰ˆæœ¬ï¼‰
- 快照版本会éšç€å¼€å‘的进展ä¸æ–æ›´æ–°
RELEASE(å‘布版本)
- 项目开å‘到进入阶段里程碑åŽï¼Œå‘团队外部å‘布较为稳定的版本,这ç§ç‰ˆæœ¬æ‰€å¯¹åº”的构件文件是稳定的,å³ä¾¿è¿›è¡ŒåŠŸèƒ½çš„åŽç»å¼€å‘,也ä¸ä¼šæ”¹å˜å½“å‰å‘布版本内容,这ç§ç‰ˆæœ¬ç§°ä¸ºå‘布版本
约定规范:
- <主版本>.<次版本>.<增é‡ç‰ˆæœ¬>.<里程碑版本>
- 主版本:表示项目é‡å¤§æž¶æž„çš„å˜æ›´ï¼Œå¦‚:Spring5 相较于 Spring4 çš„è¿ä»£
- æ¬¡ç‰ˆæœ¬ï¼šè¡¨ç¤ºæœ‰è¾ƒå¤§çš„åŠŸèƒ½å¢žåŠ å’Œå˜åŒ–,或者全é¢ç³»ç»Ÿåœ°ä¿®å¤æ¼æ´ž
- 增é‡ç‰ˆæœ¬ï¼šè¡¨ç¤ºæœ‰é‡å¤§æ¼æ´žçš„ä¿®å¤
- é‡Œç¨‹ç¢‘ç‰ˆæœ¬ï¼šè¡¨æ˜Žä¸€ä¸ªç‰ˆæœ¬çš„é‡Œç¨‹ç¢‘ï¼ˆç‰ˆæœ¬å†…éƒ¨ï¼‰ã€‚è¿™æ ·çš„ç‰ˆæœ¬åŒä¸‹ä¸€ä¸ªæ£å¼ç‰ˆæœ¬ç›¸æ¯”,相对æ¥è¯´ä¸æ˜¯å¾ˆç¨³å®šï¼Œæœ‰å¾…更多的测试
***
### 资æºé…ç½®
作用:在任æ„é…置文件ä¸åŠ è½½ pom 文件ä¸å®šä¹‰çš„属性
* 父文件 pom.xml
```xml
jdbc:mysql://192.168.0.137:3306/ssm_db?useSSL=false
```
- å¼€å¯é…ç½®æ–‡ä»¶åŠ è½½ pom 属性:
```xml
${project.basedir}/src/main/resources
true
```
* properties 文件ä¸è°ƒç”¨æ ¼å¼ï¼š
```properties
jdbc.driver=com.mysql.jdbc.Driverjdbc.url=${jdbc.url}
jdbc.username=rootjdbc.password=123456
```
***
### 多环境é…ç½®
* 环境é…ç½®
```xml
pro_env
jdbc:mysql://127.1.1.1:3306/ssm_db
true
dev_env
……
```
* åŠ è½½æŒ‡å®šçŽ¯å¢ƒ
ä½œç”¨ï¼šåŠ è½½æŒ‡å®šçŽ¯å¢ƒé…ç½®
è°ƒç”¨æ ¼å¼ï¼š
```sh
mvn 指令 –P 环境定义id
```
范例:
```sh
mvn install –P pro_env
```
***
## 跳过测试
命令:
```sh
mvn 指令 –D skipTests
```
注æ„事项:执行的指令生命周期必须包å«æµ‹è¯•çŽ¯èŠ‚
IEDA ç•Œé¢ï¼š

é…置跳过:
```xml
maven-surefire-plugin
2.22.1
true
**/User*Test.java
**/User*TestCase.java
```
***
## ç§æœ
### Nexus
Nexus 是 Sonatype å…¬å¸çš„一款 Maven ç§æœäº§å“
下载地å€ï¼šhttps://help.sonatype.com/repomanager3/download
å¯åŠ¨æœåŠ¡å™¨ï¼ˆå‘½ä»¤è¡Œå¯åŠ¨ï¼‰ï¼š
```sh
nexus.exe /run nexus
```
访问æœåŠ¡å™¨ï¼ˆé»˜è®¤ç«¯å£ï¼š8081):
```sh
http://localhost:8081
```
修改基础é…置信æ¯
- 安装路径下 etc ç›®å½•ä¸ nexus-default.properties 文件ä¿å˜æœ‰ nexus 基础é…置信æ¯ï¼Œä¾‹å¦‚默认访问端å£
修改æœåŠ¡å™¨è¿è¡Œé…置信æ¯
- 安装路径下 bin ç›®å½•ä¸ nexus.vmoptions 文件ä¿å˜æœ‰ nexus æœåŠ¡å™¨å¯åŠ¨çš„é…置信æ¯ï¼Œä¾‹å¦‚默认å 用内å˜ç©ºé—´
***
### 资æºæ“作

仓库分类:
* 宿主仓库 hosted
* ä¿å˜æ— 法从ä¸å¤®ä»“库获å–的资æº
* è‡ªä¸»ç ”å‘
* 第三方éžå¼€æºé¡¹ç›®
* 代ç†ä»“库 proxy
* 代ç†è¿œç¨‹ä»“库,通过 nexus 访问其他公共仓库,例如ä¸å¤®ä»“库
* 仓库组 group
* 将若干个仓库组æˆä¸€ä¸ªç¾¤ç»„,简化é…ç½®
* 仓库组ä¸èƒ½ä¿å˜èµ„æºï¼Œå±žäºŽè®¾è®¡åž‹ä»“库
资æºä¸Šä¼ ï¼Œä¸Šä¼ èµ„æºæ—¶æ供对应的信æ¯
- ä¿å˜çš„ä½ç½®ï¼ˆå®¿ä¸»ä»“库)
- 资æºæ–‡ä»¶
- 对应åæ ‡
***
### IDEAæ“作
#### ä¸Šä¼ ä¸‹è½½

***
#### 访问ç§æœ
##### 本地访问
é…置本地仓库访问ç§æœçš„æƒé™ï¼ˆsetting.xml)
```xml
heima-release
admin
admin
heima-snapshots
admin
admin
```
é…置本地仓库资æºæ¥æºï¼ˆsetting.xml)
```xml
nexus-heima
*
http://localhost:8081/repository/maven-public/
```
***
##### 工程访问
é…置当å‰é¡¹ç›®è®¿é—®ç§æœä¸Šä¼ 资æºçš„ä¿å˜ä½ç½®ï¼ˆpom.xml)
```xml
heima-release
http://localhost:8081/repository/heima-release/
heima-snapshots
http://localhost:8081/repository/heima-snapshots/
```
å‘布资æºåˆ°ç§æœå‘½ä»¤
```sh
mvn deploy
```
***
## 日志
### Log4j
程åºä¸çš„日志å¯ä»¥ç”¨æ¥è®°å½•ç¨‹åºåœ¨è¿è¡Œæ—¶å€™çš„详情,并å¯ä»¥è¿›è¡Œæ°¸ä¹…å˜å‚¨ã€‚
| | 输出è¯å¥ | 日志技术 |
| -------- | -------------------------- | ---------------------------------------- |
| å–消日志 | 需è¦ä¿®æ”¹ä»£ç ,çµæ´»æ€§æ¯”较差 | ä¸éœ€è¦ä¿®æ”¹ä»£ç ,çµæ´»æ€§æ¯”较好 |
| 输出ä½ç½® | åªèƒ½æ˜¯æŽ§åˆ¶å° | å¯ä»¥å°†æ—¥å¿—ä¿¡æ¯å†™å…¥åˆ°æ–‡ä»¶æˆ–者数æ®åº“ä¸ |
| 多线程 | 和业务代ç å¤„äºŽä¸€ä¸ªçº¿ç¨‹ä¸ | 多线程方å¼è®°å½•æ—¥å¿—,ä¸å½±å“业务代ç 的性能 |
Log4j 是 Apache 的一个开æºé¡¹ç›®ã€‚使用 Log4j,通过一个é…置文件æ¥çµæ´»åœ°è¿›è¡Œé…置,而ä¸éœ€è¦ä¿®æ”¹åº”用的代ç 。我们å¯ä»¥æŽ§åˆ¶æ—¥å¿—ä¿¡æ¯è¾“é€çš„目的地是控制å°ã€æ–‡ä»¶ç‰ä½ç½®ï¼Œä¹Ÿå¯ä»¥æŽ§åˆ¶æ¯ä¸€æ¡æ—¥å¿—çš„è¾“å‡ºæ ¼å¼ã€‚
 ***
### é…置文件
é…ç½®æ–‡ä»¶çš„ä¸‰ä¸ªæ ¸å¿ƒï¼š
+ é…ç½®æ ¹ Logger
+ æ ¼å¼ï¼šlog4j.rootLogger=日志级别,appenderName1,appenderName2,…
+ 日志级别:常è§çš„五个级别:**DEBUG < INFO < WARN < ERROR < FATAL**(å¯ä»¥è‡ªå®šä¹‰ï¼‰
Log4j规则:åªè¾“出级别ä¸ä½ŽäºŽè®¾å®šçº§åˆ«çš„日志信æ¯
+ appenderName1:指定日志信æ¯è¦è¾“出地å€ã€‚å¯ä»¥åŒæ—¶æŒ‡å®šå¤šä¸ªè¾“出目的地,用逗å·éš”开:
例如:log4j.rootLoggerï¼INFO,ca,fa
+ Appenders(输出æºï¼‰ï¼šæ—¥å¿—è¦è¾“出的地方,如控制å°ï¼ˆConsole)ã€æ–‡ä»¶ï¼ˆFiles)ç‰
+ Appenders å–值:
+ org.apache.log4j.ConsoleAppender(控制å°ï¼‰
+ org.apache.log4j.FileAppender(文件)
+ ConsoleAppender 常用å‚æ•°
+ `ImmediateFlush=true`:表示所有消æ¯éƒ½ä¼šè¢«ç«‹å³è¾“出,设为 false 则ä¸è¾“出,默认值是 true
+ `Target=System.err`:默认值是 System.out
+ FileAppender常用的选项
+ `ImmediateFlush=true`:表示所有消æ¯éƒ½ä¼šè¢«ç«‹å³è¾“出。设为 false 则ä¸è¾“出,默认值是 true
+ `Append=false`:true 表示将消æ¯æ·»åŠ 到指定文件ä¸ï¼ŒåŽŸæ¥çš„消æ¯ä¸è¦†ç›–。默认值是 true
+ `File=E:/logs/logging.log4j`:指定消æ¯è¾“出到 logging.log4j 文件ä¸
+ Layouts (布局)ï¼šæ—¥å¿—è¾“å‡ºçš„æ ¼å¼ï¼Œå¸¸ç”¨çš„布局管ç†å™¨ï¼š
+ org.apache.log4j.PatternLayout(å¯ä»¥çµæ´»åœ°æŒ‡å®šå¸ƒå±€æ¨¡å¼ï¼‰
+ org.apache.log4j.SimpleLayout(包å«æ—¥å¿—ä¿¡æ¯çš„级别和信æ¯å—符串)
+ org.apache.log4j.TTCCLayout(包å«æ—¥å¿—产生的时间ã€çº¿ç¨‹ã€ç±»åˆ«ç‰ä¿¡æ¯ï¼‰
+ PatternLayout 常用的选项
***
### é…置文件
é…ç½®æ–‡ä»¶çš„ä¸‰ä¸ªæ ¸å¿ƒï¼š
+ é…ç½®æ ¹ Logger
+ æ ¼å¼ï¼šlog4j.rootLogger=日志级别,appenderName1,appenderName2,…
+ 日志级别:常è§çš„五个级别:**DEBUG < INFO < WARN < ERROR < FATAL**(å¯ä»¥è‡ªå®šä¹‰ï¼‰
Log4j规则:åªè¾“出级别ä¸ä½ŽäºŽè®¾å®šçº§åˆ«çš„日志信æ¯
+ appenderName1:指定日志信æ¯è¦è¾“出地å€ã€‚å¯ä»¥åŒæ—¶æŒ‡å®šå¤šä¸ªè¾“出目的地,用逗å·éš”开:
例如:log4j.rootLoggerï¼INFO,ca,fa
+ Appenders(输出æºï¼‰ï¼šæ—¥å¿—è¦è¾“出的地方,如控制å°ï¼ˆConsole)ã€æ–‡ä»¶ï¼ˆFiles)ç‰
+ Appenders å–值:
+ org.apache.log4j.ConsoleAppender(控制å°ï¼‰
+ org.apache.log4j.FileAppender(文件)
+ ConsoleAppender 常用å‚æ•°
+ `ImmediateFlush=true`:表示所有消æ¯éƒ½ä¼šè¢«ç«‹å³è¾“出,设为 false 则ä¸è¾“出,默认值是 true
+ `Target=System.err`:默认值是 System.out
+ FileAppender常用的选项
+ `ImmediateFlush=true`:表示所有消æ¯éƒ½ä¼šè¢«ç«‹å³è¾“出。设为 false 则ä¸è¾“出,默认值是 true
+ `Append=false`:true 表示将消æ¯æ·»åŠ 到指定文件ä¸ï¼ŒåŽŸæ¥çš„消æ¯ä¸è¦†ç›–。默认值是 true
+ `File=E:/logs/logging.log4j`:指定消æ¯è¾“出到 logging.log4j 文件ä¸
+ Layouts (布局)ï¼šæ—¥å¿—è¾“å‡ºçš„æ ¼å¼ï¼Œå¸¸ç”¨çš„布局管ç†å™¨ï¼š
+ org.apache.log4j.PatternLayout(å¯ä»¥çµæ´»åœ°æŒ‡å®šå¸ƒå±€æ¨¡å¼ï¼‰
+ org.apache.log4j.SimpleLayout(包å«æ—¥å¿—ä¿¡æ¯çš„级别和信æ¯å—符串)
+ org.apache.log4j.TTCCLayout(包å«æ—¥å¿—产生的时间ã€çº¿ç¨‹ã€ç±»åˆ«ç‰ä¿¡æ¯ï¼‰
+ PatternLayout 常用的选项
 ***
### 日志应用
* log4j çš„é…置文件,åå—为 log4j.properties, 放在 src æ ¹ç›®å½•ä¸‹
```properties
log4j.rootLogger=debug,my,fileAppender
### direct log messages to my ###
log4j.appender.my=org.apache.log4j.ConsoleAppender
log4j.appender.my.ImmediateFlush = true
log4j.appender.my.Target=System.out
log4j.appender.my.layout=org.apache.log4j.PatternLayout
log4j.appender.my.layout.ConversionPattern=%d %t %5p %c{1}:%L - %m%n
# fileAppender演示
log4j.appender.fileAppender=org.apache.log4j.FileAppender
log4j.appender.fileAppender.ImmediateFlush = true
log4j.appender.fileAppender.Append=true
log4j.appender.fileAppender.File=E:/log4j-log.log
log4j.appender.fileAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.fileAppender.layout.ConversionPattern=%d %5p %c{1}:%L - %m%n
```
* 测试类
```java
// 测试类
public class Log4JTest01 {
//使用log4jçš„apiæ¥èŽ·å–日志的对象
//弊端:如果以åŽæˆ‘们更æ¢æ—¥å¿—的实现类,那么下é¢çš„代ç 就需è¦è·Ÿç€æ”¹
//ä¸æŽ¨è使用
//private static final Logger LOGGER = Logger.getLogger(Log4JTest01.class);
//使用slf4j里é¢çš„apiæ¥èŽ·å–日志的对象
//好处:如果以åŽæˆ‘们更æ¢æ—¥å¿—的实现类,那么下é¢çš„代ç ä¸éœ€è¦è·Ÿç€ä¿®æ”¹
//推è使用
private static final Logger LOGGER = LoggerFactory.getLogger(Log4JTest01.class);
public static void main(String[] args) {
//1.导入jar包
//2.编写é…置文件
//3.在代ç ä¸èŽ·å–日志的对象
//4.按照日志级别设置日志信æ¯
LOGGER.debug("debug级别的日志");
LOGGER.info("info级别的日志");
LOGGER.warn("warn级别的日志");
LOGGER.error("error级别的日志");
}
}
```
***
# Netty
## 基本介ç»
Netty 是一个异æ¥äº‹ä»¶é©±åŠ¨çš„网络应用程åºæ¡†æž¶ï¼Œç”¨äºŽå¿«é€Ÿå¼€å‘å¯ç»´æŠ¤ã€é«˜æ€§èƒ½çš„网络æœåŠ¡å™¨å’Œå®¢æˆ·ç«¯
Netty 官网:https://netty.io/
Netty 的对 JDK 自带的 NIO çš„ API 进行å°è£…,解决上述问题,主è¦ç‰¹ç‚¹æœ‰ï¼š
- 设计优雅,适用于å„ç§ä¼ 输类型的统一 API, 阻塞和éžé˜»å¡ž Socket 基于çµæ´»ä¸”å¯æ‰©å±•çš„事件模型
- 使用方便,详细记录的 Javadocã€ç”¨æˆ·æŒ‡å—和示例,没有其他ä¾èµ–项
- 高性能,åžåé‡æ›´é«˜ï¼Œå»¶è¿Ÿæ›´ä½Žï¼Œå‡å°‘资æºæ¶ˆè€—,最å°åŒ–ä¸å¿…è¦çš„内å˜å¤åˆ¶
- 安全,完整的 SSL/TLS å’Œ StartTLS 支æŒ
Netty 的功能特性:
* ä¼ è¾“æœåŠ¡ï¼šæ”¯æŒ BIO å’Œ NIO
* 容器集æˆï¼šæ”¯æŒ OSGIã€JBossMCã€Springã€Guice 容器
* å议支æŒï¼šHTTPã€Protobufã€äºŒè¿›åˆ¶ã€æ–‡æœ¬ã€WebSocket ç‰ä¸€ç³»åˆ—å议都支æŒï¼Œä¹Ÿæ”¯æŒé€šè¿‡å®žè¡Œç¼–ç 解ç 逻辑æ¥å®žçŽ°è‡ªå®šä¹‰åè®®
* Core æ ¸å¿ƒï¼šå¯æ‰©å±•äº‹ä»¶æ¨¡åž‹ã€é€šç”¨é€šä¿¡ APIã€æ”¯æŒé›¶æ‹·è´çš„ ByteBuf 缓冲对象
***
### 日志应用
* log4j çš„é…置文件,åå—为 log4j.properties, 放在 src æ ¹ç›®å½•ä¸‹
```properties
log4j.rootLogger=debug,my,fileAppender
### direct log messages to my ###
log4j.appender.my=org.apache.log4j.ConsoleAppender
log4j.appender.my.ImmediateFlush = true
log4j.appender.my.Target=System.out
log4j.appender.my.layout=org.apache.log4j.PatternLayout
log4j.appender.my.layout.ConversionPattern=%d %t %5p %c{1}:%L - %m%n
# fileAppender演示
log4j.appender.fileAppender=org.apache.log4j.FileAppender
log4j.appender.fileAppender.ImmediateFlush = true
log4j.appender.fileAppender.Append=true
log4j.appender.fileAppender.File=E:/log4j-log.log
log4j.appender.fileAppender.layout=org.apache.log4j.PatternLayout
log4j.appender.fileAppender.layout.ConversionPattern=%d %5p %c{1}:%L - %m%n
```
* 测试类
```java
// 测试类
public class Log4JTest01 {
//使用log4jçš„apiæ¥èŽ·å–日志的对象
//弊端:如果以åŽæˆ‘们更æ¢æ—¥å¿—的实现类,那么下é¢çš„代ç 就需è¦è·Ÿç€æ”¹
//ä¸æŽ¨è使用
//private static final Logger LOGGER = Logger.getLogger(Log4JTest01.class);
//使用slf4j里é¢çš„apiæ¥èŽ·å–日志的对象
//好处:如果以åŽæˆ‘们更æ¢æ—¥å¿—的实现类,那么下é¢çš„代ç ä¸éœ€è¦è·Ÿç€ä¿®æ”¹
//推è使用
private static final Logger LOGGER = LoggerFactory.getLogger(Log4JTest01.class);
public static void main(String[] args) {
//1.导入jar包
//2.编写é…置文件
//3.在代ç ä¸èŽ·å–日志的对象
//4.按照日志级别设置日志信æ¯
LOGGER.debug("debug级别的日志");
LOGGER.info("info级别的日志");
LOGGER.warn("warn级别的日志");
LOGGER.error("error级别的日志");
}
}
```
***
# Netty
## 基本介ç»
Netty 是一个异æ¥äº‹ä»¶é©±åŠ¨çš„网络应用程åºæ¡†æž¶ï¼Œç”¨äºŽå¿«é€Ÿå¼€å‘å¯ç»´æŠ¤ã€é«˜æ€§èƒ½çš„网络æœåŠ¡å™¨å’Œå®¢æˆ·ç«¯
Netty 官网:https://netty.io/
Netty 的对 JDK 自带的 NIO çš„ API 进行å°è£…,解决上述问题,主è¦ç‰¹ç‚¹æœ‰ï¼š
- 设计优雅,适用于å„ç§ä¼ 输类型的统一 API, 阻塞和éžé˜»å¡ž Socket 基于çµæ´»ä¸”å¯æ‰©å±•çš„事件模型
- 使用方便,详细记录的 Javadocã€ç”¨æˆ·æŒ‡å—和示例,没有其他ä¾èµ–项
- 高性能,åžåé‡æ›´é«˜ï¼Œå»¶è¿Ÿæ›´ä½Žï¼Œå‡å°‘资æºæ¶ˆè€—,最å°åŒ–ä¸å¿…è¦çš„内å˜å¤åˆ¶
- 安全,完整的 SSL/TLS å’Œ StartTLS 支æŒ
Netty 的功能特性:
* ä¼ è¾“æœåŠ¡ï¼šæ”¯æŒ BIO å’Œ NIO
* 容器集æˆï¼šæ”¯æŒ OSGIã€JBossMCã€Springã€Guice 容器
* å议支æŒï¼šHTTPã€Protobufã€äºŒè¿›åˆ¶ã€æ–‡æœ¬ã€WebSocket ç‰ä¸€ç³»åˆ—å议都支æŒï¼Œä¹Ÿæ”¯æŒé€šè¿‡å®žè¡Œç¼–ç 解ç 逻辑æ¥å®žçŽ°è‡ªå®šä¹‰åè®®
* Core æ ¸å¿ƒï¼šå¯æ‰©å±•äº‹ä»¶æ¨¡åž‹ã€é€šç”¨é€šä¿¡ APIã€æ”¯æŒé›¶æ‹·è´çš„ ByteBuf 缓冲对象
 ***
## 线程模型
### 阻塞模型
ä¼ ç»Ÿé˜»å¡žåž‹ I/O 模å¼ï¼Œæ¯ä¸ªè¿žæŽ¥éƒ½éœ€è¦ç‹¬ç«‹çš„线程完æˆæ•°æ®çš„输入,业务处ç†ï¼Œæ•°æ®è¿”回
***
## 线程模型
### 阻塞模型
ä¼ ç»Ÿé˜»å¡žåž‹ I/O 模å¼ï¼Œæ¯ä¸ªè¿žæŽ¥éƒ½éœ€è¦ç‹¬ç«‹çš„线程完æˆæ•°æ®çš„输入,业务处ç†ï¼Œæ•°æ®è¿”回
 模型缺点:
- 当并å‘数较大时,需è¦åˆ›å»ºå¤§é‡çº¿ç¨‹æ¥å¤„ç†è¿žæŽ¥ï¼Œç³»ç»Ÿèµ„æºå 用较大
- 连接建立åŽï¼Œå¦‚果当å‰çº¿ç¨‹æš‚时没有数æ®å¯è¯»ï¼Œåˆ™çº¿ç¨‹å°±é˜»å¡žåœ¨ read æ“ä½œä¸Šï¼Œé€ æˆçº¿ç¨‹èµ„æºæµªè´¹
å‚è€ƒæ–‡ç« ï¼šhttps://www.jianshu.com/p/2965fca6bb8f
***
### Reactor
#### 设计æ€æƒ³
Reactor 模å¼ï¼Œé€šè¿‡ä¸€ä¸ªæˆ–多个输入åŒæ—¶ä¼ 递给æœåŠ¡å¤„ç†å™¨çš„**事件驱动处ç†æ¨¡å¼**。 æœåŠ¡ç«¯ç¨‹åºå¤„ç†ä¼ 入的多路请求,并将它们åŒæ¥åˆ†æ´¾ç»™å¯¹åº”的处ç†çº¿ç¨‹ï¼ŒReactor 模å¼ä¹Ÿå« Dispatcher 模å¼ï¼Œå³ I/O 多路å¤ç”¨ç»Ÿä¸€ç›‘å¬äº‹ä»¶ï¼Œæ”¶åˆ°äº‹ä»¶åŽåˆ†å‘(Dispatch ç»™æŸçº¿ç¨‹ï¼‰
**I/O å¤ç”¨ç»“åˆçº¿ç¨‹æ± **,就是 Reactor 模å¼åŸºæœ¬è®¾è®¡æ€æƒ³ï¼š
模型缺点:
- 当并å‘数较大时,需è¦åˆ›å»ºå¤§é‡çº¿ç¨‹æ¥å¤„ç†è¿žæŽ¥ï¼Œç³»ç»Ÿèµ„æºå 用较大
- 连接建立åŽï¼Œå¦‚果当å‰çº¿ç¨‹æš‚时没有数æ®å¯è¯»ï¼Œåˆ™çº¿ç¨‹å°±é˜»å¡žåœ¨ read æ“ä½œä¸Šï¼Œé€ æˆçº¿ç¨‹èµ„æºæµªè´¹
å‚è€ƒæ–‡ç« ï¼šhttps://www.jianshu.com/p/2965fca6bb8f
***
### Reactor
#### 设计æ€æƒ³
Reactor 模å¼ï¼Œé€šè¿‡ä¸€ä¸ªæˆ–多个输入åŒæ—¶ä¼ 递给æœåŠ¡å¤„ç†å™¨çš„**事件驱动处ç†æ¨¡å¼**。 æœåŠ¡ç«¯ç¨‹åºå¤„ç†ä¼ 入的多路请求,并将它们åŒæ¥åˆ†æ´¾ç»™å¯¹åº”的处ç†çº¿ç¨‹ï¼ŒReactor 模å¼ä¹Ÿå« Dispatcher 模å¼ï¼Œå³ I/O 多路å¤ç”¨ç»Ÿä¸€ç›‘å¬äº‹ä»¶ï¼Œæ”¶åˆ°äº‹ä»¶åŽåˆ†å‘(Dispatch ç»™æŸçº¿ç¨‹ï¼‰
**I/O å¤ç”¨ç»“åˆçº¿ç¨‹æ± **,就是 Reactor 模å¼åŸºæœ¬è®¾è®¡æ€æƒ³ï¼š
 Reactor 模å¼å…³é”®ç»„æˆï¼š
- Reactor:在一个å•ç‹¬çš„线程ä¸è¿è¡Œï¼Œè´Ÿè´£**监å¬å’Œåˆ†å‘事件**,分å‘给适当的处ç†ç¨‹åºæ¥å¯¹ I/O 事件åšå‡ºå应
- Handler:处ç†ç¨‹åºæ‰§è¡Œ I/O è¦å®Œæˆçš„实际事件,Reactor 通过调度适当的处ç†ç¨‹åºæ¥å“应 I/O 事件,处ç†ç¨‹åºæ‰§è¡Œ**éžé˜»å¡žæ“作**
Reactor 模å¼å…·æœ‰å¦‚下的优点:
- å“应快,ä¸å¿…为å•ä¸ªåŒæ¥æ—¶é—´æ‰€é˜»å¡žï¼Œè™½ç„¶ Reactor 本身ä¾ç„¶æ˜¯åŒæ¥çš„
- 编程相对简å•ï¼Œå¯ä»¥æœ€å¤§ç¨‹åº¦çš„é¿å…å¤æ‚的多线程åŠåŒæ¥é—®é¢˜ï¼Œå¹¶ä¸”é¿å…了多线程/进程的切æ¢å¼€é”€
- å¯æ‰©å±•æ€§ï¼Œå¯ä»¥æ–¹ä¾¿çš„é€šè¿‡å¢žåŠ Reactor 实例个数æ¥å……分利用 CPU 资æº
- å¯å¤ç”¨æ€§ï¼ŒReactor 模型本身与具体事件处ç†é€»è¾‘æ— å…³ï¼Œå…·æœ‰å¾ˆé«˜çš„å¤ç”¨æ€§
æ ¹æ® Reactor çš„æ•°é‡å’Œå¤„ç†èµ„æºæ± 线程的数é‡ä¸åŒï¼Œæœ‰ä¸‰ç§å…¸åž‹çš„实现:
- å• Reactor å•çº¿ç¨‹
- å• Reactor 多线程
- 主从 Reactor 多线程
***
#### å•Rå•çº¿ç¨‹
Reactor 对象通过 select 监控客户端请求事件,收到事件åŽé€šè¿‡ dispatch 进行分å‘:
* 如果是建立连接请求事件,则由 Acceptor 通过 accept 处ç†è¿žæŽ¥è¯·æ±‚,然åŽåˆ›å»ºä¸€ä¸ª Handler 对象处ç†è¿žæŽ¥å®ŒæˆåŽçš„åŽç»ä¸šåŠ¡å¤„ç†
* 如果ä¸æ˜¯å»ºç«‹è¿žæŽ¥äº‹ä»¶ï¼Œåˆ™ Reactor 会分å‘给连接对应的 Handler æ¥å“应,Handler ä¼šå®Œæˆ readã€ä¸šåŠ¡å¤„ç†ã€send 的完整æµç¨‹
说明:**Handler å’Œ Acceptor 属于åŒä¸€ä¸ªçº¿ç¨‹**
Reactor 模å¼å…³é”®ç»„æˆï¼š
- Reactor:在一个å•ç‹¬çš„线程ä¸è¿è¡Œï¼Œè´Ÿè´£**监å¬å’Œåˆ†å‘事件**,分å‘给适当的处ç†ç¨‹åºæ¥å¯¹ I/O 事件åšå‡ºå应
- Handler:处ç†ç¨‹åºæ‰§è¡Œ I/O è¦å®Œæˆçš„实际事件,Reactor 通过调度适当的处ç†ç¨‹åºæ¥å“应 I/O 事件,处ç†ç¨‹åºæ‰§è¡Œ**éžé˜»å¡žæ“作**
Reactor 模å¼å…·æœ‰å¦‚下的优点:
- å“应快,ä¸å¿…为å•ä¸ªåŒæ¥æ—¶é—´æ‰€é˜»å¡žï¼Œè™½ç„¶ Reactor 本身ä¾ç„¶æ˜¯åŒæ¥çš„
- 编程相对简å•ï¼Œå¯ä»¥æœ€å¤§ç¨‹åº¦çš„é¿å…å¤æ‚的多线程åŠåŒæ¥é—®é¢˜ï¼Œå¹¶ä¸”é¿å…了多线程/进程的切æ¢å¼€é”€
- å¯æ‰©å±•æ€§ï¼Œå¯ä»¥æ–¹ä¾¿çš„é€šè¿‡å¢žåŠ Reactor 实例个数æ¥å……分利用 CPU 资æº
- å¯å¤ç”¨æ€§ï¼ŒReactor 模型本身与具体事件处ç†é€»è¾‘æ— å…³ï¼Œå…·æœ‰å¾ˆé«˜çš„å¤ç”¨æ€§
æ ¹æ® Reactor çš„æ•°é‡å’Œå¤„ç†èµ„æºæ± 线程的数é‡ä¸åŒï¼Œæœ‰ä¸‰ç§å…¸åž‹çš„实现:
- å• Reactor å•çº¿ç¨‹
- å• Reactor 多线程
- 主从 Reactor 多线程
***
#### å•Rå•çº¿ç¨‹
Reactor 对象通过 select 监控客户端请求事件,收到事件åŽé€šè¿‡ dispatch 进行分å‘:
* 如果是建立连接请求事件,则由 Acceptor 通过 accept 处ç†è¿žæŽ¥è¯·æ±‚,然åŽåˆ›å»ºä¸€ä¸ª Handler 对象处ç†è¿žæŽ¥å®ŒæˆåŽçš„åŽç»ä¸šåŠ¡å¤„ç†
* 如果ä¸æ˜¯å»ºç«‹è¿žæŽ¥äº‹ä»¶ï¼Œåˆ™ Reactor 会分å‘给连接对应的 Handler æ¥å“应,Handler ä¼šå®Œæˆ readã€ä¸šåŠ¡å¤„ç†ã€send 的完整æµç¨‹
说明:**Handler å’Œ Acceptor 属于åŒä¸€ä¸ªçº¿ç¨‹**
 模型优点:模型简å•ï¼Œæ²¡æœ‰å¤šçº¿ç¨‹ã€è¿›ç¨‹é€šä¿¡ã€ç«žäº‰çš„问题,全部都在一个线程ä¸å®Œæˆ
模型缺点:
* 性能问题:åªæœ‰ä¸€ä¸ªçº¿ç¨‹ï¼Œæ— 法å‘æŒ¥å¤šæ ¸ CPU 的性能,Handler 在处ç†æŸä¸ªè¿žæŽ¥ä¸Šçš„ä¸šåŠ¡æ—¶ï¼Œæ•´ä¸ªè¿›ç¨‹æ— æ³•å¤„ç†å…¶ä»–连接事件,很容易导致性能瓶颈
* å¯é 性问题:线程æ„外跑飞,或者进入æ»å¾ªçŽ¯ï¼Œä¼šå¯¼è‡´æ•´ä¸ªç³»ç»Ÿé€šä¿¡æ¨¡å—ä¸å¯ç”¨ï¼Œä¸èƒ½æŽ¥æ”¶å’Œå¤„ç†å¤–部消æ¯ï¼Œé€ æˆèŠ‚点故障
使用场景:客户端的数é‡æœ‰é™ï¼Œä¸šåŠ¡å¤„ç†éžå¸¸å¿«é€Ÿï¼Œæ¯”如 Redis,业务处ç†çš„时间å¤æ‚度 O(1)
***
#### å•R多线程
执行æµç¨‹é€šåŒå• Reactor å•çº¿ç¨‹ï¼Œä¸åŒçš„是:
* Handler åªè´Ÿè´£å“应事件,ä¸åšå…·ä½“业务处ç†ï¼Œé€šè¿‡ read 读å–æ•°æ®åŽï¼Œä¼šåˆ†å‘ç»™åŽé¢çš„ Worker çº¿ç¨‹æ± è¿›è¡Œä¸šåŠ¡å¤„ç†
* Worker çº¿ç¨‹æ± ä¼šåˆ†é…独立的线程完æˆçœŸæ£çš„业务处ç†ï¼Œå°†å“应结果å‘ç»™ Handler 进行处ç†ï¼Œæœ€åŽç”± Handler 收到å“应结果åŽé€šè¿‡ send å°†å“应结果返回给 Client
模型优点:模型简å•ï¼Œæ²¡æœ‰å¤šçº¿ç¨‹ã€è¿›ç¨‹é€šä¿¡ã€ç«žäº‰çš„问题,全部都在一个线程ä¸å®Œæˆ
模型缺点:
* 性能问题:åªæœ‰ä¸€ä¸ªçº¿ç¨‹ï¼Œæ— 法å‘æŒ¥å¤šæ ¸ CPU 的性能,Handler 在处ç†æŸä¸ªè¿žæŽ¥ä¸Šçš„ä¸šåŠ¡æ—¶ï¼Œæ•´ä¸ªè¿›ç¨‹æ— æ³•å¤„ç†å…¶ä»–连接事件,很容易导致性能瓶颈
* å¯é 性问题:线程æ„外跑飞,或者进入æ»å¾ªçŽ¯ï¼Œä¼šå¯¼è‡´æ•´ä¸ªç³»ç»Ÿé€šä¿¡æ¨¡å—ä¸å¯ç”¨ï¼Œä¸èƒ½æŽ¥æ”¶å’Œå¤„ç†å¤–部消æ¯ï¼Œé€ æˆèŠ‚点故障
使用场景:客户端的数é‡æœ‰é™ï¼Œä¸šåŠ¡å¤„ç†éžå¸¸å¿«é€Ÿï¼Œæ¯”如 Redis,业务处ç†çš„时间å¤æ‚度 O(1)
***
#### å•R多线程
执行æµç¨‹é€šåŒå• Reactor å•çº¿ç¨‹ï¼Œä¸åŒçš„是:
* Handler åªè´Ÿè´£å“应事件,ä¸åšå…·ä½“业务处ç†ï¼Œé€šè¿‡ read 读å–æ•°æ®åŽï¼Œä¼šåˆ†å‘ç»™åŽé¢çš„ Worker çº¿ç¨‹æ± è¿›è¡Œä¸šåŠ¡å¤„ç†
* Worker çº¿ç¨‹æ± ä¼šåˆ†é…独立的线程完æˆçœŸæ£çš„业务处ç†ï¼Œå°†å“应结果å‘ç»™ Handler 进行处ç†ï¼Œæœ€åŽç”± Handler 收到å“应结果åŽé€šè¿‡ send å°†å“应结果返回给 Client
 模型优点:å¯ä»¥å……åˆ†åˆ©ç”¨å¤šæ ¸ CPU 的处ç†èƒ½åŠ›
模型缺点:
* 多线程数æ®å…±äº«å’Œè®¿é—®æ¯”较å¤æ‚
* Reactor 承担所有事件的监å¬å’Œå“应,在å•çº¿ç¨‹ä¸è¿è¡Œï¼Œé«˜å¹¶å‘场景下容易æˆä¸ºæ€§èƒ½ç“¶é¢ˆ
***
#### 主从模型
采用多个 Reactor ,执行æµç¨‹ï¼š
* Reactor 主线程 MainReactor 通过 select 监控建立连接事件,收到事件åŽé€šè¿‡ Acceptor 接收,处ç†å»ºç«‹è¿žæŽ¥äº‹ä»¶ï¼Œå¤„ç†å®ŒæˆåŽ MainReactor 会将连接分é…ç»™ Reactor å线程的 SubReactor(有多个)处ç†
* SubReactor å°†è¿žæŽ¥åŠ å…¥è¿žæŽ¥é˜Ÿåˆ—è¿›è¡Œç›‘å¬ï¼Œå¹¶åˆ›å»ºä¸€ä¸ª Handler 用于处ç†è¯¥è¿žæŽ¥çš„事件,当有新的事件å‘生时,SubReactor 会调用连接对应的 Handler 进行å“应
* Handler 通过 read 读å–æ•°æ®åŽï¼Œä¼šåˆ†å‘ç»™ Worker çº¿ç¨‹æ± è¿›è¡Œä¸šåŠ¡å¤„ç†
* Worker çº¿ç¨‹æ± ä¼šåˆ†é…独立的线程完æˆçœŸæ£çš„业务处ç†ï¼Œå°†å“应结果å‘ç»™ Handler 进行处ç†ï¼Œæœ€åŽç”± Handler 收到å“应结果åŽé€šè¿‡ send å°†å“应结果返回给 Client
模型优点:å¯ä»¥å……åˆ†åˆ©ç”¨å¤šæ ¸ CPU 的处ç†èƒ½åŠ›
模型缺点:
* 多线程数æ®å…±äº«å’Œè®¿é—®æ¯”较å¤æ‚
* Reactor 承担所有事件的监å¬å’Œå“应,在å•çº¿ç¨‹ä¸è¿è¡Œï¼Œé«˜å¹¶å‘场景下容易æˆä¸ºæ€§èƒ½ç“¶é¢ˆ
***
#### 主从模型
采用多个 Reactor ,执行æµç¨‹ï¼š
* Reactor 主线程 MainReactor 通过 select 监控建立连接事件,收到事件åŽé€šè¿‡ Acceptor 接收,处ç†å»ºç«‹è¿žæŽ¥äº‹ä»¶ï¼Œå¤„ç†å®ŒæˆåŽ MainReactor 会将连接分é…ç»™ Reactor å线程的 SubReactor(有多个)处ç†
* SubReactor å°†è¿žæŽ¥åŠ å…¥è¿žæŽ¥é˜Ÿåˆ—è¿›è¡Œç›‘å¬ï¼Œå¹¶åˆ›å»ºä¸€ä¸ª Handler 用于处ç†è¯¥è¿žæŽ¥çš„事件,当有新的事件å‘生时,SubReactor 会调用连接对应的 Handler 进行å“应
* Handler 通过 read 读å–æ•°æ®åŽï¼Œä¼šåˆ†å‘ç»™ Worker çº¿ç¨‹æ± è¿›è¡Œä¸šåŠ¡å¤„ç†
* Worker çº¿ç¨‹æ± ä¼šåˆ†é…独立的线程完æˆçœŸæ£çš„业务处ç†ï¼Œå°†å“应结果å‘ç»™ Handler 进行处ç†ï¼Œæœ€åŽç”± Handler 收到å“应结果åŽé€šè¿‡ send å°†å“应结果返回给 Client
 模型优点
- **父线程与å线程**çš„æ•°æ®äº¤äº’简å•èŒè´£æ˜Žç¡®ï¼Œçˆ¶çº¿ç¨‹åªéœ€è¦æŽ¥æ”¶æ–°è¿žæŽ¥ï¼Œå线程完æˆåŽç»çš„业务处ç†
- 父线程与å线程的数æ®äº¤äº’简å•ï¼ŒReactor 主线程åªéœ€è¦æŠŠæ–°è¿žæŽ¥ä¼ ç»™å线程,åçº¿ç¨‹æ— éœ€è¿”å›žæ•°æ®
使用场景:Nginx 主从 Reactor 多进程模型,Memcached 主从多线程,Netty 主从多线程模型的支æŒ
***
### Proactor
Reactor 模å¼ä¸ï¼ŒReactor ç‰å¾…æŸä¸ªäº‹ä»¶çš„æ“作状æ€å‘生å˜åŒ–(文件æ述符å¯è¯»å†™ï¼Œsocket å¯è¯»å†™ï¼‰ï¼Œç„¶åŽæŠŠäº‹ä»¶ä¼ 递给事先注册的 Handler æ¥åšå®žé™…的读写æ“作,其ä¸çš„读写æ“作都需è¦åº”用程åºåŒæ¥æ“作,所以 **Reactor 是éžé˜»å¡žåŒæ¥ç½‘络模型(NIO)**
把 I/O æ“作改为异æ¥ï¼Œäº¤ç»™æ“作系统æ¥å®Œæˆå°±èƒ½è¿›ä¸€æ¥æå‡æ€§èƒ½ï¼Œè¿™å°±æ˜¯å¼‚æ¥ç½‘络模型 Proactor(AIO):
模型优点
- **父线程与å线程**çš„æ•°æ®äº¤äº’简å•èŒè´£æ˜Žç¡®ï¼Œçˆ¶çº¿ç¨‹åªéœ€è¦æŽ¥æ”¶æ–°è¿žæŽ¥ï¼Œå线程完æˆåŽç»çš„业务处ç†
- 父线程与å线程的数æ®äº¤äº’简å•ï¼ŒReactor 主线程åªéœ€è¦æŠŠæ–°è¿žæŽ¥ä¼ ç»™å线程,åçº¿ç¨‹æ— éœ€è¿”å›žæ•°æ®
使用场景:Nginx 主从 Reactor 多进程模型,Memcached 主从多线程,Netty 主从多线程模型的支æŒ
***
### Proactor
Reactor 模å¼ä¸ï¼ŒReactor ç‰å¾…æŸä¸ªäº‹ä»¶çš„æ“作状æ€å‘生å˜åŒ–(文件æ述符å¯è¯»å†™ï¼Œsocket å¯è¯»å†™ï¼‰ï¼Œç„¶åŽæŠŠäº‹ä»¶ä¼ 递给事先注册的 Handler æ¥åšå®žé™…的读写æ“作,其ä¸çš„读写æ“作都需è¦åº”用程åºåŒæ¥æ“作,所以 **Reactor 是éžé˜»å¡žåŒæ¥ç½‘络模型(NIO)**
把 I/O æ“作改为异æ¥ï¼Œäº¤ç»™æ“作系统æ¥å®Œæˆå°±èƒ½è¿›ä¸€æ¥æå‡æ€§èƒ½ï¼Œè¿™å°±æ˜¯å¼‚æ¥ç½‘络模型 Proactor(AIO):
 工作æµç¨‹ï¼š
* ProactorInitiator 创建 Proactor å’Œ Handler 对象,并将 Proactor å’Œ Handler 通过 Asynchronous Operation Processor(AsyOptProcessorï¼‰æ³¨å†Œåˆ°å†…æ ¸
* AsyOptProcessor 处ç†æ³¨å†Œè¯·æ±‚ï¼Œå¹¶å¤„ç† I/O æ“作,完æˆI/OåŽé€šçŸ¥ Proactor
* Proactor æ ¹æ®ä¸åŒçš„事件类型回调ä¸åŒçš„ Handler 进行业务处ç†ï¼Œæœ€åŽç”± Handler 完æˆä¸šåŠ¡å¤„ç†
对比:Reactor 在事件å‘生时就通知事先注册的处ç†å™¨ï¼ˆè¯»å†™åœ¨åº”用程åºçº¿ç¨‹ä¸å¤„ç†å®Œæˆï¼‰ï¼›Proactor 是在事件å‘ç”Ÿæ—¶åŸºäºŽå¼‚æ¥ I/O 完æˆè¯»å†™æ“ä½œï¼ˆå†…æ ¸å®Œæˆï¼‰ï¼ŒI/O 完æˆåŽæ‰å›žè°ƒåº”用程åºçš„处ç†å™¨è¿›è¡Œä¸šåŠ¡å¤„ç†
模å¼ä¼˜ç‚¹ï¼šå¼‚æ¥ I/O æ›´åŠ å……åˆ†å‘挥 DMA(Direct Memory Access 直接内å˜å˜å–)的优势
模å¼ç¼ºç‚¹ï¼š
* 编程å¤æ‚性,由于异æ¥æ“作æµç¨‹çš„事件的åˆå§‹åŒ–和事件完æˆåœ¨æ—¶é—´å’Œç©ºé—´ä¸Šéƒ½æ˜¯ç›¸äº’åˆ†ç¦»çš„ï¼Œå› æ¤å¼€å‘异æ¥åº”用程åºæ›´åŠ å¤æ‚,应用程åºè¿˜å¯èƒ½å› 为åå‘çš„æµæŽ§è€Œå˜å¾—æ›´åŠ éš¾ä»¥è°ƒè¯•
* 内å˜ä½¿ç”¨ï¼Œç¼“冲区在读或写æ“作的时间段内必须ä¿æŒä½ï¼Œå¯èƒ½é€ æˆæŒç»çš„ä¸ç¡®å®šæ€§ï¼Œå¹¶ä¸”æ¯ä¸ªå¹¶å‘æ“作都è¦æ±‚有独立的缓å˜ï¼ŒReactor 模å¼åœ¨ socket 准备好读或写之å‰æ˜¯ä¸è¦æ±‚开辟缓å˜çš„
* æ“作系统支æŒï¼ŒWindows 下通过 IOCP 实现了真æ£çš„å¼‚æ¥ I/O,而在 Linux 系统下,Linux2.6 æ‰å¼•å…¥å¼‚æ¥ I/O,目å‰è¿˜ä¸å®Œå–„,所以在 Linux 下实现高并å‘网络编程都是以 Reactor 模型为主
****
### Netty
Netty 主è¦åŸºäºŽä¸»ä»Ž Reactors 多线程模型åšäº†ä¸€å®šçš„改进,Netty 的工作架构图:
工作æµç¨‹ï¼š
* ProactorInitiator 创建 Proactor å’Œ Handler 对象,并将 Proactor å’Œ Handler 通过 Asynchronous Operation Processor(AsyOptProcessorï¼‰æ³¨å†Œåˆ°å†…æ ¸
* AsyOptProcessor 处ç†æ³¨å†Œè¯·æ±‚ï¼Œå¹¶å¤„ç† I/O æ“作,完æˆI/OåŽé€šçŸ¥ Proactor
* Proactor æ ¹æ®ä¸åŒçš„事件类型回调ä¸åŒçš„ Handler 进行业务处ç†ï¼Œæœ€åŽç”± Handler 完æˆä¸šåŠ¡å¤„ç†
对比:Reactor 在事件å‘生时就通知事先注册的处ç†å™¨ï¼ˆè¯»å†™åœ¨åº”用程åºçº¿ç¨‹ä¸å¤„ç†å®Œæˆï¼‰ï¼›Proactor 是在事件å‘ç”Ÿæ—¶åŸºäºŽå¼‚æ¥ I/O 完æˆè¯»å†™æ“ä½œï¼ˆå†…æ ¸å®Œæˆï¼‰ï¼ŒI/O 完æˆåŽæ‰å›žè°ƒåº”用程åºçš„处ç†å™¨è¿›è¡Œä¸šåŠ¡å¤„ç†
模å¼ä¼˜ç‚¹ï¼šå¼‚æ¥ I/O æ›´åŠ å……åˆ†å‘挥 DMA(Direct Memory Access 直接内å˜å˜å–)的优势
模å¼ç¼ºç‚¹ï¼š
* 编程å¤æ‚性,由于异æ¥æ“作æµç¨‹çš„事件的åˆå§‹åŒ–和事件完æˆåœ¨æ—¶é—´å’Œç©ºé—´ä¸Šéƒ½æ˜¯ç›¸äº’åˆ†ç¦»çš„ï¼Œå› æ¤å¼€å‘异æ¥åº”用程åºæ›´åŠ å¤æ‚,应用程åºè¿˜å¯èƒ½å› 为åå‘çš„æµæŽ§è€Œå˜å¾—æ›´åŠ éš¾ä»¥è°ƒè¯•
* 内å˜ä½¿ç”¨ï¼Œç¼“冲区在读或写æ“作的时间段内必须ä¿æŒä½ï¼Œå¯èƒ½é€ æˆæŒç»çš„ä¸ç¡®å®šæ€§ï¼Œå¹¶ä¸”æ¯ä¸ªå¹¶å‘æ“作都è¦æ±‚有独立的缓å˜ï¼ŒReactor 模å¼åœ¨ socket 准备好读或写之å‰æ˜¯ä¸è¦æ±‚开辟缓å˜çš„
* æ“作系统支æŒï¼ŒWindows 下通过 IOCP 实现了真æ£çš„å¼‚æ¥ I/O,而在 Linux 系统下,Linux2.6 æ‰å¼•å…¥å¼‚æ¥ I/O,目å‰è¿˜ä¸å®Œå–„,所以在 Linux 下实现高并å‘网络编程都是以 Reactor 模型为主
****
### Netty
Netty 主è¦åŸºäºŽä¸»ä»Ž Reactors 多线程模型åšäº†ä¸€å®šçš„改进,Netty 的工作架构图:
 工作æµç¨‹ï¼š
1. Netty æŠ½è±¡å‡ºä¸¤ç»„çº¿ç¨‹æ± BossGroup 专门负责接收客户端的连接,WorkerGroup 专门负责网络的读写
2. BossGroup å’Œ WorkerGroup 类型都是 NioEventLoopGroup,该 Group 相当于一个事件循环组,å«æœ‰å¤šä¸ªäº‹ä»¶å¾ªçŽ¯ï¼Œæ¯ä¸€ä¸ªäº‹ä»¶å¾ªçŽ¯æ˜¯ NioEventLoop,所以å¯ä»¥æœ‰å¤šä¸ªçº¿ç¨‹
3. NioEventLoop 表示一个**循环处ç†ä»»åŠ¡çš„线程**,æ¯ä¸ª NioEventLoop 都有一个 Selector,用于监å¬ç»‘定在其上的 Socket 的通讯
4. æ¯ä¸ª Boss NioEventLoop 循环执行的æ¥éª¤ï¼š
- 轮询 accept 事件
- å¤„ç† accept 事件,与 client å»ºç«‹è¿žæŽ¥ï¼Œç”Ÿæˆ NioScocketChannel,并将其**注册到æŸä¸ª Worker ä¸**çš„æŸä¸ª NioEventLoop 上的 Selector,连接就与 NioEventLoop 绑定
- 处ç†ä»»åŠ¡é˜Ÿåˆ—çš„ä»»åŠ¡ï¼Œå³ runAllTasks
5. æ¯ä¸ª Worker NioEventLoop 循环执行的æ¥éª¤ï¼š
- 轮询 readã€write 事件
- å¤„ç† I/O äº‹ä»¶ï¼Œå³ read,write 事件,在对应 NioSocketChannel 处ç†
- 处ç†ä»»åŠ¡é˜Ÿåˆ—çš„ä»»åŠ¡ï¼Œå³ runAllTasks
6. æ¯ä¸ª Worker NioEventLoop 处ç†ä¸šåŠ¡æ—¶ï¼Œä¼šä½¿ç”¨ pipeline(管é“),pipeline ä¸åŒ…å«äº† channel,å³é€šè¿‡ pipeline å¯ä»¥èŽ·å–到对应通é“,管é“ä¸ç»´æŠ¤äº†å¾ˆå¤šçš„处ç†å™¨ Handler
工作æµç¨‹ï¼š
1. Netty æŠ½è±¡å‡ºä¸¤ç»„çº¿ç¨‹æ± BossGroup 专门负责接收客户端的连接,WorkerGroup 专门负责网络的读写
2. BossGroup å’Œ WorkerGroup 类型都是 NioEventLoopGroup,该 Group 相当于一个事件循环组,å«æœ‰å¤šä¸ªäº‹ä»¶å¾ªçŽ¯ï¼Œæ¯ä¸€ä¸ªäº‹ä»¶å¾ªçŽ¯æ˜¯ NioEventLoop,所以å¯ä»¥æœ‰å¤šä¸ªçº¿ç¨‹
3. NioEventLoop 表示一个**循环处ç†ä»»åŠ¡çš„线程**,æ¯ä¸ª NioEventLoop 都有一个 Selector,用于监å¬ç»‘定在其上的 Socket 的通讯
4. æ¯ä¸ª Boss NioEventLoop 循环执行的æ¥éª¤ï¼š
- 轮询 accept 事件
- å¤„ç† accept 事件,与 client å»ºç«‹è¿žæŽ¥ï¼Œç”Ÿæˆ NioScocketChannel,并将其**注册到æŸä¸ª Worker ä¸**çš„æŸä¸ª NioEventLoop 上的 Selector,连接就与 NioEventLoop 绑定
- 处ç†ä»»åŠ¡é˜Ÿåˆ—çš„ä»»åŠ¡ï¼Œå³ runAllTasks
5. æ¯ä¸ª Worker NioEventLoop 循环执行的æ¥éª¤ï¼š
- 轮询 readã€write 事件
- å¤„ç† I/O äº‹ä»¶ï¼Œå³ read,write 事件,在对应 NioSocketChannel 处ç†
- 处ç†ä»»åŠ¡é˜Ÿåˆ—çš„ä»»åŠ¡ï¼Œå³ runAllTasks
6. æ¯ä¸ª Worker NioEventLoop 处ç†ä¸šåŠ¡æ—¶ï¼Œä¼šä½¿ç”¨ pipeline(管é“),pipeline ä¸åŒ…å«äº† channel,å³é€šè¿‡ pipeline å¯ä»¥èŽ·å–到对应通é“,管é“ä¸ç»´æŠ¤äº†å¾ˆå¤šçš„处ç†å™¨ Handler
 ***
## 基本实现
å¼€å‘简å•çš„æœåŠ¡å™¨ç«¯å’Œå®¢æˆ·ç«¯ï¼ŒåŸºæœ¬ä»‹ç»ï¼š
* channel ç†è§£ä¸ºæ•°æ®çš„通é“,把 msg ç†è§£ä¸ºæµåŠ¨çš„æ•°æ®ï¼Œæœ€å¼€å§‹è¾“入是 ByteBuf,但ç»è¿‡ pipeline çš„åŠ å·¥ï¼Œä¼šå˜æˆå…¶å®ƒç±»åž‹å¯¹è±¡ï¼Œæœ€åŽè¾“出åˆå˜æˆ ByteBuf
* handler ç†è§£ä¸ºæ•°æ®çš„处ç†å·¥åºï¼Œpipeline è´Ÿè´£å‘å¸ƒäº‹ä»¶ä¼ æ’ç»™æ¯ä¸ª handler,handler 对自己感兴趣的事件进行处ç†ï¼ˆé‡å†™äº†ç›¸åº”事件处ç†æ–¹æ³•ï¼‰ï¼Œåˆ† Inbound å’Œ Outbound 两类
* eventLoop ç†è§£ä¸ºå¤„ç†æ•°æ®çš„执行者,既å¯ä»¥æ‰§è¡Œ IO æ“作,也å¯ä»¥è¿›è¡Œä»»åŠ¡å¤„ç†ã€‚æ¯ä¸ªæ‰§è¡Œè€…有任务队列,队列里å¯ä»¥å †æ”¾å¤šä¸ª channel 的待处ç†ä»»åŠ¡ï¼Œä»»åŠ¡åˆ†ä¸ºæ™®é€šä»»åŠ¡ã€å®šæ—¶ä»»åŠ¡ã€‚按照 pipeline 顺åºï¼Œä¾æ¬¡æŒ‰ç…§ handler 的规划(代ç )处ç†æ•°æ®
代ç 实现:
* pom.xml
```xml
io.netty
netty-all
4.1.20.Final
```
* Server.java
```java
public class HelloServer {
public static void main(String[] args) {
EventLoopGroup boss = new NioEventLoopGroup();
EventLoopGroup worker = new NioEventLoopGroup(2);
// 1. å¯åŠ¨å™¨ï¼Œè´Ÿè´£ç»„装 netty 组件,å¯åŠ¨æœåŠ¡å™¨
new ServerBootstrap()
// 2. 线程组,boss åªè´Ÿè´£ã€å¤„ç† accept 事件】, worker åªã€è´Ÿè´£ channel 上的读写】
.group(boss, worker)
//.option() // ç»™ ServerSocketChannel é…ç½®å‚æ•°
//.childOption() // ç»™ SocketChannel é…ç½®å‚æ•°
// 3. 选择æœåŠ¡å™¨çš„ ServerSocketChannel 实现
.channel(NioServerSocketChannel.class)
// 4. boss 负责处ç†è¿žæŽ¥ï¼Œworker(child) 负责处ç†è¯»å†™ï¼Œå†³å®šäº†èƒ½æ‰§è¡Œå“ªäº›æ“作(handler)
.childHandler(new ChannelInitializer() {
// 5. channel 代表和客户端进行数æ®è¯»å†™çš„é€šé“ Initializer åˆå§‹åŒ–ï¼Œè´Ÿè´£æ·»åŠ åˆ«çš„ handler
// 7. 连接建立åŽï¼Œæ‰§è¡Œåˆå§‹åŒ–方法
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// æ·»åŠ å…·ä½“çš„ handler
ch.pipeline().addLast(new StringDecoder());// å°† ByteBuf 转æˆå—符串
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() { // 自定义 handler
// 读事件
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
// 打å°è½¬æ¢å¥½çš„å—符串
System.out.println(msg);
}
});
}
})
// 6. 绑定监å¬ç«¯å£
.bind(8080);
}
}
```
* Client.java
```java
public class HelloClient {
public static void main(String[] args) throws InterruptedException {
// 1. 创建å¯åŠ¨å™¨ç±»
new Bootstrap()
// 2. æ·»åŠ EventLoop
.group(new NioEventLoopGroup())
//.option() //ç»™ SocketChannel é…ç½®å‚æ•°
// 3. 选择客户端 channel 实现
.channel(NioSocketChannel.class)
// 4. æ·»åŠ å¤„ç†å™¨
.handler(new ChannelInitializer() {
// 4.1 连接建立åŽè¢«è°ƒç”¨
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// 将 Hello World 转为 ByteBuf
ch.pipeline().addLast(new StringEncoder());
}
})
// 5. 连接到æœåŠ¡å™¨ï¼Œç„¶åŽè°ƒç”¨ 4.1
.connect(new InetSocketAddress("127.0.0.1",8080))
// 6. 阻塞方法,直到连接建立
.sync()
// 7. 代表连接对象
.channel()
// 8. å‘æœåŠ¡å™¨å‘é€æ•°æ®
.writeAndFlush("Hello World");
}
}
```
å‚考视频:https://www.bilibili.com/video/BV1py4y1E7oA
****
## 组件介ç»
### EventLoop
#### 基本介ç»
事件循环对象 EventLoop,**本质是一个å•çº¿ç¨‹æ‰§è¡Œå™¨åŒæ—¶ç»´æŠ¤äº†ä¸€ä¸ª Selector**,有 run æ–¹æ³•å¤„ç† Channel 上æºæºä¸æ–çš„ IO 事件
事件循环组 EventLoopGroup 是一组 EventLoop,Channel 会调用 Boss EventLoopGroup çš„ register 方法æ¥ç»‘定其ä¸ä¸€ä¸ª Worker çš„ EventLoop,åŽç»è¿™ä¸ª Channel 上的 IO äº‹ä»¶éƒ½ç”±æ¤ EventLoop æ¥å¤„ç†ï¼Œä¿è¯äº†äº‹ä»¶å¤„ç†æ—¶çš„线程安全
EventLoopGroup 类 API:
* `EventLoop next()`:获å–集åˆä¸ä¸‹ä¸€ä¸ª EventLoop,EventLoopGroup 实现了 Iterable 接å£æä¾›é历 EventLoop 的能力
* `Future> shutdownGracefully()`:优雅关é—çš„æ–¹æ³•ï¼Œä¼šé¦–å…ˆåˆ‡æ¢ EventLoopGroup 到关é—状æ€ä»Žè€Œæ‹’ç»æ–°çš„ä»»åŠ¡çš„åŠ å…¥ï¼Œç„¶åŽåœ¨ä»»åŠ¡é˜Ÿåˆ—的任务都处ç†å®ŒæˆåŽï¼Œåœæ¢çº¿ç¨‹çš„è¿è¡Œï¼Œä»Žè€Œç¡®ä¿æ•´ä½“应用是在æ£å¸¸æœ‰åºçš„状æ€ä¸‹é€€å‡ºçš„
* ` Future submit(Callable task)`:æ交任务
* `ScheduledFuture> scheduleWithFixedDelay`:æ交定时任务
***
#### ä»»åŠ¡ä¼ é€’
把è¦è°ƒç”¨çš„代ç å°è£…为一个任务对象,由下一个 handler 的线程æ¥è°ƒç”¨
```java
public class EventLoopServer {
public static void main(String[] args) {
EventLoopGroup group = new DefaultEventLoopGroup();
new ServerBootstrap()
.group(new NioEventLoopGroup(), new NioEventLoopGroup(2))
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast("handler1", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf buf = (ByteBuf) msg;
log.debug(buf.toString(Charset.defaultCharset()));
ctx.fireChannelRead(msg); // 让消æ¯ã€ä¼ 递】给下一个 handler
}
}).addLast(group, "handler2", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf buf = (ByteBuf) msg;
log.debug(buf.toString(Charset.defaultCharset()));
}
});
}
})
.bind(8080);
}
}
```
æºç 分æžï¼š
```java
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(MASK_CHANNEL_READ), msg);
return this;
}
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
// 下一个 handler 的事件循环是å¦ä¸Žå½“å‰çš„事件循环是åŒä¸€ä¸ªçº¿ç¨‹
if (executor.inEventLoop()) {
// 是,直接调用
next.invokeChannelRead(m);
} else {
// ä¸æ˜¯ï¼Œå°†è¦æ‰§è¡Œçš„代ç 作为任务æ交给下一个 handler 处ç†
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
```
****
### Channel
#### 连接æ“作
Channel 类 API:
* `ChannelFuture close()`:关é—通é“
* `ChannelPipeline pipeline()`ï¼šæ·»åŠ å¤„ç†å™¨
* `ChannelFuture write(Object msg)`:数æ®å†™å…¥ç¼“冲区
* `ChannelFuture writeAndFlush(Object msg)`:数æ®å†™å…¥ç¼“冲区并且刷出
ChannelFuture 类 API:
* `ChannelFuture sync()`:åŒæ¥é˜»å¡žç‰å¾…连接æˆåŠŸ
* `ChannelFuture addListener(GenericFutureListener listener)`:异æ¥ç‰å¾…
代ç 实现:
* connect 方法是异æ¥çš„,ä¸ç‰è¿žæŽ¥å»ºç«‹å®Œæˆå°±è¿”å›žï¼Œå› æ¤ channelFuture 对象ä¸ä¸èƒ½ç«‹åˆ»èŽ·å¾—到æ£ç¡®çš„ Channel 对象,需è¦ç‰å¾…
* 连接未建立 channel 打å°ä¸º `[id: 0x2e1884dd]`;建立æˆåŠŸæ‰“å°ä¸º `[id: 0x2e1884dd, L:/127.0.0.1:57191 - R:/127.0.0.1:8080]`
```java
public class ChannelClient {
public static void main(String[] args) throws InterruptedException {
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new StringEncoder());
}
})
// 1. 连接æœåŠ¡å™¨ï¼Œã€å¼‚æ¥éžé˜»å¡žã€‘,main 调用 connect 方法,真æ£æ‰§è¡Œè¿žæŽ¥çš„是 nio 线程
.connect(new InetSocketAddress("127.0.0.1", 8080));
// 2.1 使用 sync 方法ã€åŒæ¥ã€‘处ç†ç»“果,阻塞当å‰çº¿ç¨‹ï¼Œç›´åˆ° nio 线程连接建立完毕
channelFuture.sync();
Channel channel = channelFuture.channel();
System.out.println(channel); // ã€æ‰“å°ã€‘
// å‘æœåŠ¡å™¨å‘é€æ•°æ®
channel.writeAndFlush("hello world");
**************************************************************************************二选一
// 2.2 使用 addListener 方法ã€å¼‚æ¥ã€‘处ç†ç»“æžœ
channelFuture.addListener(new ChannelFutureListener() {
@Override
// nio 线程连接建立好以åŽï¼Œå›žè°ƒè¯¥æ–¹æ³•
public void operationComplete(ChannelFuture future) throws Exception {
Channel channel = future.channel();
channel.writeAndFlush("hello, world");
}
});
}
}
```
***
#### å…³é—æ“作
å…³é— EventLoopGroup çš„è¿è¡Œï¼Œåˆ†ä¸ºåŒæ¥å…³é—和异æ¥å…³é—
```java
public class CloseFutureClient {
public static void main(String[] args) throws InterruptedException {
NioEventLoopGroup group = new NioEventLoopGroup();
ChannelFuture channelFuture = new Bootstrap()
.group(group)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
ch.pipeline().addLast(new StringEncoder());
}
})
.connect(new InetSocketAddress("127.0.0.1", 8080));
Channel channel = channelFuture.sync().channel();
// å‘é€æ•°æ®
new Thread(() -> {
Scanner sc = new Scanner(System.in);
while (true) {
String line = sc.nextLine();
if (line.equals("q")) {
channel.close();
break;
}
channel.writeAndFlush(line);
}
}, "input").start();
// èŽ·å– CloseFuture 对象
ChannelFuture closeFuture = channel.closeFuture();
// 1. åŒæ¥å¤„ç†å…³é—
System.out.println("waiting close...");
closeFuture.sync();
System.out.println("处ç†å…³é—åŽçš„æ“作");
****************************************************
// 2. 异æ¥å¤„ç†å…³é—
closeFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
System.out.println("处ç†å…³é—åŽçš„æ“作");
group.shutdownGracefully();
}
});
}
}
```
****
### Future
#### 基本介ç»
Netty ä¸çš„ Future 与 JDK ä¸çš„ Future åŒå,但是功能的实现ä¸åŒ
```java
package io.netty.util.concurrent;
public interface Future extends java.util.concurrent.Future
```
Future 类 API:
* `V get()`:阻塞ç‰å¾…获å–任务执行结果
* `V getNow()`:éžé˜»å¡žèŽ·å–任务结果,还未产生结果时返回 null
* `Throwable cause()`:éžé˜»å¡žèŽ·å–失败信æ¯ï¼Œå¦‚果没有失败,返回 null
* `Future sync()`:ç‰å¾…任务结æŸï¼Œå¦‚果任务失败,抛出异常
* `boolean cancel(boolean mayInterruptIfRunning)`:å–消任务
* `Future addListener(GenericFutureListener listener)`ï¼šæ·»åŠ å›žè°ƒï¼Œå¼‚æ¥æŽ¥æ”¶ç»“æžœ
* `boolean isSuccess()`:判æ–任务是å¦æˆåŠŸ
* `boolean isCancellable()`:判æ–任务是å¦å–消
```java
public class NettyFutureDemo {
public static void main(String[] args) throws Exception {
NioEventLoopGroup group = new NioEventLoopGroup();
EventLoop eventLoop = group.next();
Future future = eventLoop.submit(new Callable() {
@Override
public Integer call() throws Exception {
System.out.println("执行计算");
Thread.sleep(1000);
return 70;
}
});
future.getNow();
System.out.println(new Date() + "ç‰å¾…结果");
System.out.println(new Date() + "" + future.get());
}
}
```
****
#### 扩展åç±»
Promise 类是 Future çš„å类,å¯ä»¥è„±ç¦»ä»»åŠ¡ç‹¬ç«‹å˜åœ¨ï¼Œä½œä¸ºä¸¤ä¸ªçº¿ç¨‹é—´ä¼ 递结果的容器
```java
public interface Promise extends Future
```
Promise 类 API:
* `Promise setSuccess(V result)`:设置æˆåŠŸç»“æžœ
* `Promise setFailure(Throwable cause)`:设置失败结果
```java
public class NettyPromiseDemo {
public static void main(String[] args) throws Exception {
// 1. 准备 EventLoop 对象
EventLoop eventLoop = new NioEventLoopGroup().next();
// 2. 主动创建 promise
DefaultPromise promise = new DefaultPromise<>(eventLoop);
// 3. ä»»æ„一个线程执行计算,计算完毕åŽå‘ promise 填充结果
new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
promise.setSuccess(200);
}).start();
// 4. 接å—结果的线程
System.out.println(new Date() + "ç‰å¾…结果");
System.out.println(new Date() + "" + promise.get());
}
}
```
****
### Pipeline
ChannelHandler 用æ¥å¤„ç† Channel 上的å„ç§äº‹ä»¶ï¼Œåˆ†ä¸ºå…¥ç«™å‡ºç«™ä¸¤ç§ï¼Œæ‰€æœ‰ ChannelHandler 连接æˆåŒå‘链表就是 Pipeline
* 入站处ç†å™¨é€šå¸¸æ˜¯ ChannelInboundHandlerAdapter çš„å类,主è¦ç”¨æ¥è¯»å–客户端数æ®ï¼Œå†™å›žç»“æžœ
* 出站处ç†å™¨é€šå¸¸æ˜¯ ChannelOutboundHandlerAdapter çš„å类,主è¦å¯¹å†™å›žç»“æžœè¿›è¡ŒåŠ å·¥ï¼ˆå…¥ç«™å’Œå‡ºç«™æ˜¯å¯¹äºŽæœåŠ¡ç«¯æ¥è¯´çš„)
```java
public static void main(String[] args) {
new ServerBootstrap()
.group(new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// 1. 通过 channel 拿到 pipeline
ChannelPipeline pipeline = ch.pipeline();
// 2. æ·»åŠ å¤„ç†å™¨ head -> h1 -> h2 -> h3 -> h4 -> h5 -> h6 -> tail
pipeline.addLast("h1", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("1");
ByteBuf buf = (ByteBuf) msg;
String s = buf.toString(Charset.defaultCharset());
// 将数æ®ä¼ 递给下一个ã€å…¥ç«™ã€‘handler,如果ä¸è°ƒç”¨è¯¥æ–¹æ³•åˆ™é“¾ä¼šæ–å¼€
super.channelRead(ctx, s);
}
});
pipeline.addLast("h2", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("2");
// 从ã€å°¾éƒ¨å¼€å§‹å‘å‰è§¦å‘】出站处ç†å™¨
ch.writeAndFlush(ctx.alloc().buffer().writeBytes("server".getBytes()));
// 该方法会让管é“从ã€å½“å‰ handler å‘å‰ã€‘寻找出站处ç†å™¨
// ctx.writeAndFlush();
}
});
pipeline.addLast("h3", new ChannelOutboundHandlerAdapter() {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("3");
super.write(ctx, msg, promise);
}
});
pipeline.addLast("h4", new ChannelOutboundHandlerAdapter() {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("4");
super.write(ctx, msg, promise);
}
});
}
})
.bind(8080);
}
```
æœåŠ¡å™¨ç«¯ä¾æ¬¡æ‰“å°ï¼š1 2 4 3 ,所以**入站是按照 addLast 的顺åºæ‰§è¡Œçš„,出站是按照 addLast 的逆åºæ‰§è¡Œ**
一个 Channel 包å«äº†ä¸€ä¸ª ChannelPipeline,而 ChannelPipeline ä¸åˆç»´æŠ¤äº†ä¸€ä¸ªç”± ChannelHandlerContext 组æˆçš„åŒå‘链表,并且æ¯ä¸ª ChannelHandlerContext ä¸å…³è”ç€ä¸€ä¸ª ChannelHandler
入站事件和出站事件在一个åŒå‘链表ä¸ï¼Œä¸¤ç§ç±»åž‹çš„ handler 互ä¸å¹²æ‰°ï¼š
* 入站事件会从链表 head å¾€åŽä¼ 递到最åŽä¸€ä¸ªå…¥ç«™çš„ handler
* 出站事件会从链表 tail å¾€å‰ä¼ 递到最å‰ä¸€ä¸ªå‡ºç«™çš„ handler
****
### ByteBuf
#### 基本介ç»
ByteBuf 是对å—节数æ®çš„å°è£…,优点:
* æ± åŒ–ï¼Œå¯ä»¥é‡ç”¨æ± ä¸ ByteBuf 实例,更节约内å˜ï¼Œå‡å°‘内å˜æº¢å‡ºçš„å¯èƒ½
* 读写指针分离,ä¸éœ€è¦åƒ ByteBuffer ä¸€æ ·åˆ‡æ¢è¯»å†™æ¨¡å¼
* å¯ä»¥è‡ªåŠ¨æ‰©å®¹
* 支æŒé“¾å¼è°ƒç”¨ï¼Œä½¿ç”¨æ›´æµç•…
* 零拷è´æ€æƒ³ï¼Œä¾‹å¦‚ sliceã€duplicateã€CompositeByteBuf
****
#### 创建方法
创建方å¼
* `ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10)`:创建了一个默认的 ByteBuf,åˆå§‹å®¹é‡æ˜¯ 10
```java
public ByteBuf buffer() {
if (directByDefault) {
return directBuffer();
}
return heapBuffer();
}
```
* `ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(10)`ï¼šåˆ›å»ºæ± åŒ–åŸºäºŽå †çš„ ByteBuf
* `ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer(10)`ï¼šåˆ›å»ºæ± åŒ–åŸºäºŽç›´æŽ¥å†…å˜çš„ ByteBuf
* **推è**的创建方å¼ï¼šåœ¨æ·»åŠ 处ç†å™¨çš„方法ä¸
```java
pipeline.addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buffer = ctx.alloc().buffer();
}
});
```
直接内å˜å¯¹æ¯”å †å†…å˜ï¼š
* 直接内å˜åˆ›å»ºå’Œé”€æ¯çš„代价昂贵,但读写性能高(少一次内å˜å¤åˆ¶ï¼‰ï¼Œé€‚åˆé…åˆæ± 化功能一起用
* 直接内å˜å¯¹ GC 压力å°ï¼Œå› 为这部分内å˜ä¸å— JVM 垃圾回收的管ç†ï¼Œä½†ä¹Ÿè¦æ³¨æ„åŠæ—¶ä¸»åŠ¨é‡Šæ”¾
æ± åŒ–çš„æ„义在于å¯ä»¥**é‡ç”¨ ByteBuf**,高并å‘æ—¶æ± åŒ–åŠŸèƒ½æ›´èŠ‚çº¦å†…å˜ï¼Œå‡å°‘内å˜æº¢å‡ºçš„å¯èƒ½ï¼Œä¸Žéžæ± 化对比:
* éžæ± 化,æ¯æ¬¡éƒ½è¦åˆ›å»ºæ–°çš„ ByteBuf 实例,这个æ“作对直接内å˜ä»£ä»·æ˜‚è´µï¼Œå †å†…å˜ä¼šå¢žåŠ GC 压力
* æ± åŒ–ï¼Œå¯ä»¥é‡ç”¨æ± ä¸ ByteBuf 实例,并且采用了与 jemalloc 类似的内å˜åˆ†é…算法æå‡åˆ†é…效率
æ± åŒ–åŠŸèƒ½çš„å¼€å¯ï¼Œå¯ä»¥é€šè¿‡ä¸‹é¢çš„系统环境å˜é‡æ¥è®¾ç½®ï¼š
```sh
-Dio.netty.allocator.type={unpooled|pooled} # VM å‚æ•°
```
* 4.1 以åŽï¼Œéž Android å¹³å°é»˜è®¤å¯ç”¨æ± 化实现,Android å¹³å°å¯ç”¨éžæ± 化实现
* 4.1 之å‰ï¼Œæ± 化功能还ä¸æˆç†Ÿï¼Œé»˜è®¤æ˜¯éžæ± 化实现
****
#### 读写æ“作
ByteBuf 由四部分组æˆï¼Œæœ€å¼€å§‹è¯»å†™æŒ‡é’ˆï¼ˆ**åŒæŒ‡é’ˆ**)都在 0 ä½ç½®

写入方法:
| 方法å | 说明 | 备注 |
| ------------------------------------------------ | ---------------------- | ------------------------------------------- |
| writeBoolean(boolean value) | 写入 boolean 值 | 用一å—节 01\|00 代表 true\|false |
| writeByte(int value) | 写入 byte 值 | |
| writeInt(int value) | 写入 int 值 | Big Endianï¼Œå³ 0x250ï¼Œå†™å…¥åŽ 00 00 02 50 |
| writeIntLE(int value) | 写入 int 值 | Little Endianï¼Œå³ 0x250ï¼Œå†™å…¥åŽ 50 02 00 00 |
| writeBytes(ByteBuf src) | 写入 ByteBuf | |
| writeBytes(byte[] src) | 写入 byte[] | |
| writeBytes(ByteBuffer src) | 写入 NIO 的 ByteBuffer | |
| int writeCharSequence(CharSequence s, Charset c) | 写入å—符串 | |
* 这些方法的未指明返回值的,其返回值都是 ByteBuf,æ„味ç€å¯ä»¥é“¾å¼è°ƒç”¨
* å†™å…¥å‡ ä½å†™æŒ‡é’ˆåŽç§»å‡ ä½ï¼ŒæŒ‡å‘å¯ä»¥å†™å…¥çš„ä½ç½®
* ç½‘ç»œä¼ è¾“ï¼Œé»˜è®¤ä¹ æƒ¯æ˜¯ Big Endian
扩容:写入数æ®æ—¶ï¼Œå®¹é‡ä¸å¤Ÿäº†ï¼ˆåˆå§‹å®¹é‡æ˜¯ 10),这时会引å‘扩容
* 如果写入åŽæ•°æ®å¤§å°æœªè¶…过 512,则选择下一个 16 çš„æ•´æ•°å€ï¼Œä¾‹å¦‚写入åŽå¤§å°ä¸º 12 ï¼Œåˆ™æ‰©å®¹åŽ capacity 是 16
* 如果写入åŽæ•°æ®å¤§å°è¶…过 512,则选择下一个 2^n,例如写入åŽå¤§å°ä¸º 513ï¼Œåˆ™æ‰©å®¹åŽ capacity 是 2^10 = 1024(2^9=512 ä¸å¤Ÿï¼‰
* 扩容ä¸èƒ½è¶…过 max capacity 会报错
读å–方法:
* `byte readByte()`:读å–一个å—节,读指针åŽç§»
* `byte getByte(int index)`:读å–指定索引ä½ç½®çš„å—节,读指针ä¸åŠ¨
* `ByteBuf markReaderIndex()`ï¼šæ ‡è®°è¯»æ•°æ®çš„ä½ç½®
* `ByteBuf resetReaderIndex()`:é‡ç½®åˆ°æ ‡è®°ä½ç½®ï¼Œå¯ä»¥é‡å¤è¯»å–æ ‡è®°ä½ç½®å‘åŽçš„æ•°æ®
****
#### 内å˜é‡Šæ”¾
Netty ä¸ä¸‰ç§å†…å˜çš„回收:
* UnpooledHeapByteBuf 使用的是 JVM 内å˜ï¼Œåªéœ€ç‰ GC 回收内å˜
* UnpooledDirectByteBuf 使用的就是直接内å˜äº†ï¼Œéœ€è¦ç‰¹æ®Šçš„方法æ¥å›žæ”¶å†…å˜
* PooledByteBuf å’Œåç±»ä½¿ç”¨äº†æ± åŒ–æœºåˆ¶ï¼Œéœ€è¦æ›´å¤æ‚的规则æ¥å›žæ”¶å†…å˜
Netty 采用了引用计数法æ¥æŽ§åˆ¶å›žæ”¶å†…å˜ï¼Œæ¯ä¸ª ByteBuf 都实现了 ReferenceCounted 接å£ï¼Œå›žæ”¶çš„规则:
* æ¯ä¸ª ByteBuf 对象的åˆå§‹è®¡æ•°ä¸º 1
* 调用 release æ–¹æ³•è®¡æ•°å‡ 1,如果计数为 0,ByteBuf 内å˜è¢«å›žæ”¶
* 调用 retain æ–¹æ³•è®¡æ•°åŠ 1,表示调用者没用完之å‰ï¼Œå…¶å®ƒ handler å³ä½¿è°ƒç”¨äº† release 也ä¸ä¼šé€ æˆå›žæ”¶
* 当计数为 0 时,底层内å˜ä¼šè¢«å›žæ”¶ï¼Œè¿™æ—¶å³ä½¿ ByteBuf 对象还在,其å„个方法å‡æ— 法æ£å¸¸ä½¿ç”¨
```java
ByteBuf buf = .ByteBufAllocator.DEFAULT.buffer(10)
try {
// 逻辑处ç†
} finally {
buf.release();
}
```
Pipeline çš„å˜åœ¨ï¼Œéœ€è¦å°† ByteBuf ä¼ é€’ç»™ä¸‹ä¸€ä¸ª ChannelHandler,如果在 finally ä¸ release äº†ï¼Œå°±å¤±åŽ»äº†ä¼ é€’æ€§ï¼Œå¤„ç†è§„则:
* 创建 ByteBuf 放入 pipeline
* 入站 ByteBuf 处ç†åŽŸåˆ™
* 对原始 ByteBuf ä¸åšå¤„ç†ï¼Œè°ƒç”¨ ctx.fireChannelRead(msg) å‘åŽä¼ é€’ï¼Œè¿™æ—¶æ— é¡» release
* 将原始 ByteBuf 转æ¢ä¸ºå…¶å®ƒç±»åž‹çš„ Java 对象,这时 ByteBuf 就没用了,æ¤æ—¶å¿…é¡» release
* 如果ä¸è°ƒç”¨ ctx.fireChannelRead(msg) å‘åŽä¼ 递,那么也必须 release
* 如果出现异常,ByteBuf 没有æˆåŠŸä¼ 递到下一个 ChannelHandler,必须 release
* å‡è®¾æ¶ˆæ¯ä¸€ç›´å‘åŽä¼ ,那么 TailContext 会负责释放未处ç†æ¶ˆæ¯ï¼ˆåŽŸå§‹çš„ ByteBuf)
```java
// io.netty.channel.DefaultChannelPipeline#onUnhandledInboundMessage(java.lang.Object)
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug();
} finally {
ReferenceCountUtil.release(msg);
}
}
// io.netty.util.ReferenceCountUtil#release(java.lang.Object)
public static boolean release(Object msg) {
if (msg instanceof ReferenceCounted) {
return ((ReferenceCounted) msg).release();
}
return false;
}
```
* 出站 ByteBuf 处ç†åŽŸåˆ™
* 出站消æ¯æœ€ç»ˆéƒ½ä¼šè½¬ä¸º ByteBuf 输出,一直å‘å‰ä¼ ,由 HeadContext flush åŽ release
* ä¸ç¡®å®š ByteBuf 被引用了多少次,但åˆå¿…须彻底释放,å¯ä»¥å¾ªçŽ¯è°ƒç”¨ release 直到返回 true
****
#### æ‹·è´æ“作
零拷è´æ–¹æ³•ï¼š
* `ByteBuf slice(int index, int length)`:对原始 ByteBuf 进行切片æˆå¤šä¸ª ByteBuf,切片åŽçš„ ByteBuf 并没有å‘生内å˜å¤åˆ¶ï¼Œ**共用原始 ByteBuf 的内å˜**,切片åŽçš„ ByteBuf 维护独立的 read,write 指针
```java
public static void main(String[] args) {
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer(10);
buf.writeBytes(new byte[]{'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'});
// 在切片过程ä¸å¹¶æ²¡æœ‰å‘生数æ®å¤åˆ¶
ByteBuf f1 = buf.slice(0, 5);
f1.retain();
ByteBuf f2 = buf.slice(5, 5);
f2.retain();
// 对 f1 进行相关的æ“作也会体现在 buf 上
}
```
* `ByteBuf duplicate()`:截å–原始 ByteBuf 所有内容,并且没有 max capacity çš„é™åˆ¶ï¼Œä¹Ÿæ˜¯ä¸ŽåŽŸå§‹ ByteBuf 使用åŒä¸€å—底层内å˜ï¼Œåªæ˜¯è¯»å†™æŒ‡é’ˆæ˜¯ç‹¬ç«‹çš„
* `CompositeByteBuf addComponents(boolean increaseWriterIndex, ByteBuf... buffers)`:åˆå¹¶å¤šä¸ª ByteBuf
```java
public static void main(String[] args) {
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer();
buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer();
buf1.writeBytes(new byte[]{6, 7, 8, 9, 10});
CompositeByteBuf buf = ByteBufAllocator.DEFAULT.compositeBuffer();
// true è¡¨ç¤ºå¢žåŠ æ–°çš„ ByteBuf 自动递增 write index, å¦åˆ™ write index 会始终为 0
buf.addComponents(true, buf1, buf2);
}
```
CompositeByteBuf 是一个组åˆçš„ ByteBuf,内部维护了一个 Component 数组,æ¯ä¸ª Component 管ç†ä¸€ä¸ª ByteBuf,记录了这个 ByteBuf 相对于整体å移é‡ç‰ä¿¡æ¯ï¼Œä»£è¡¨ç€æ•´ä½“ä¸æŸä¸€æ®µçš„æ•°æ®
* 优点:对外是一个虚拟视图,组åˆè¿™äº› ByteBuf ä¸ä¼šäº§ç”Ÿå†…å˜å¤åˆ¶
* 缺点:å¤æ‚了很多,多次æ“作会带æ¥æ€§èƒ½çš„æŸè€—
深拷è´ï¼š
* `ByteBuf copy()`:将底层内å˜æ•°æ®è¿›è¡Œæ·±æ‹·è´ï¼Œå› æ¤æ— 论读写,都与原始 ByteBuf æ— å…³
æ± åŒ–ç›¸å…³ï¼š
* Unpooled 是一个工具类,æ供了éžæ± 化的 ByteBuf 创建ã€ç»„åˆã€å¤åˆ¶ç‰æ“作
```java
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(5);
buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(5);
buf2.writeBytes(new byte[]{6, 7, 8, 9, 10});
// 当包装 ByteBuf 个数超过一个时, 底层使用了 CompositeByteBuf,零拷è´æ€æƒ³
ByteBuf buf = Unpooled.wrappedBuffer(buf1, buf2);
```
****
## 粘包åŠåŒ…
### 现象演示
在 TCP ä¼ è¾“ä¸ï¼Œå®¢æˆ·ç«¯å‘é€æ¶ˆæ¯æ—¶ï¼Œå®žé™…上是将数æ®å†™å…¥ TCP 的缓å˜ï¼Œæ¤æ—¶æ•°æ®çš„大å°å’Œç¼“å˜çš„大å°å°±ä¼šé€ æˆç²˜åŒ…å’ŒåŠåŒ…
* 当数æ®è¶…过 TCP 缓å˜å®¹é‡æ—¶ï¼Œå°±ä¼šè¢«æ‹†åˆ†æˆå¤šä¸ªåŒ…,通过 Socket 多次å‘é€åˆ°æœåŠ¡ç«¯ï¼ŒæœåŠ¡ç«¯æ¯æ¬¡ä»Žç¼“å˜ä¸å–æ•°æ®ï¼Œäº§ç”ŸåŠåŒ…问题
* 当数æ®å°äºŽ TCP 缓å˜å®¹é‡æ—¶ï¼Œç¼“å˜ä¸å¯ä»¥å˜æ”¾å¤šä¸ªåŒ…,客户端和æœåŠ¡ç«¯ä¸€æ¬¡é€šä¿¡å°±å¯èƒ½ä¼ 递多个包,这时候æœåŠ¡ç«¯å°±å¯èƒ½ä¸€æ¬¡è¯»å–多个包,产生粘包的问题
代ç 演示:
* 客户端代ç :
```java
public class HelloWorldClient {
public static void main(String[] args) {
send();
}
private static void send() {
NioEventLoopGroup worker = new NioEventLoopGroup();
try {
Bootstrap bootstrap = new Bootstrap();
bootstrap.channel(NioSocketChannel.class);
bootstrap.group(worker);
bootstrap.handler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {
// ã€åœ¨è¿žæŽ¥ channel 建立æˆåŠŸåŽï¼Œä¼šè§¦å‘ active 方法】
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
// å‘é€å†…容éšæœºçš„æ•°æ®åŒ…
Random r = new Random();
char c = '0';
ByteBuf buf = ctx.alloc().buffer();
for (int i = 0; i < 10; i++) {
byte[] bytes = new byte[10];
for (int j = 0; j < r.nextInt(9) + 1; j++) {
bytes[j] = (byte) c;
}
c++;
buf.writeBytes(bytes);
}
ctx.writeAndFlush(buf);
}
});
}
});
ChannelFuture channelFuture = bootstrap.connect("127.0.0.1", 8080).sync();
channelFuture.channel().closeFuture().sync();
} catch (InterruptedException e) {
log.error("client error", e);
} finally {
worker.shutdownGracefully();
}
}
}
```
* æœåŠ¡å™¨ä»£ç :
```java
public class HelloWorldServer {
public static void main(String[] args) {
NioEventLoopGroup boss = new NioEventLoopGroup(1);
NioEventLoopGroup worker = new NioEventLoopGroup();
try {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
// 调整系统的接å—缓冲区ã€æ»‘动窗å£ã€‘
//serverBootstrap.option(ChannelOption.SO_RCVBUF, 10);
// 调整 netty 的接å—缓冲区(ByteBuf)
//serverBootstrap.childOption(ChannelOption.RCVBUF_ALLOCATOR,
// new AdaptiveRecvByteBufAllocator(16, 16, 16));
serverBootstrap.group(boss, worker);
serverBootstrap.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// ã€è¿™é‡Œå¯ä»¥æ·»åŠ 解ç 器】
// LoggingHandler 用æ¥æ‰“å°æ¶ˆæ¯
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
}
});
ChannelFuture channelFuture = serverBootstrap.bind(8080);
channelFuture.sync();
channelFuture.channel().closeFuture().sync();
} catch (InterruptedException e) {
log.error("server error", e);
} finally {
boss.shutdownGracefully();
worker.shutdownGracefully();
log.debug("stop");
}
}
}
```
* 粘包效果展示:
```java
09:57:27.140 [nioEventLoopGroup-3-1] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0xddbaaef6, L:/127.0.0.1:8080 - R:/127.0.0.1:8701] READ: 100B // 读了 100 å—节,å‘生粘包
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 30 30 30 30 30 00 00 00 00 00 31 00 00 00 00 00 |00000.....1.....|
|00000010| 00 00 00 00 32 32 32 32 00 00 00 00 00 00 33 00 |....2222......3.|
|00000020| 00 00 00 00 00 00 00 00 34 34 00 00 00 00 00 00 |........44......|
|00000030| 00 00 35 35 35 35 00 00 00 00 00 00 36 36 36 00 |..5555......666.|
|00000040| 00 00 00 00 00 00 37 37 37 37 00 00 00 00 00 00 |......7777......|
|00000050| 38 38 38 38 38 00 00 00 00 00 39 39 00 00 00 00 |88888.....99....|
|00000060| 00 00 00 00 |.... |
+--------+-------------------------------------------------+----------------+
```
解决方法:通过调整系统的接å—缓冲区的滑动窗å£å’Œ Netty 的接å—缓冲区ä¿è¯æ¯æ¡åŒ…åªå«æœ‰ä¸€æ¡æ•°æ®ï¼Œæ»‘动窗å£çš„大å°ä»…决定了 Netty 读å–çš„**最å°å•ä½**,实际æ¯æ¬¡è¯»å–的一般是它的整数å€
***
### 解决方案
#### çŸè¿žæŽ¥
å‘ä¸€ä¸ªåŒ…å»ºç«‹ä¸€æ¬¡è¿žæŽ¥ï¼Œè¿™æ ·è¿žæŽ¥å»ºç«‹åˆ°è¿žæŽ¥æ–开之间就是消æ¯çš„边界,缺点就是效率很低
客户端代ç æ”¹é€ ï¼š
```java
public class HelloWorldClient {
public static void main(String[] args) {
// 分 10 次å‘é€
for (int i = 0; i < 10; i++) {
send();
}
}
}
```
****
#### 固定长度
æœåŠ¡å™¨ç«¯åŠ 入定长解ç 器,æ¯ä¸€æ¡æ¶ˆæ¯é‡‡ç”¨å›ºå®šé•¿åº¦ã€‚如果是åŠåŒ…消æ¯ï¼Œä¼šç¼“å˜åŠåŒ…消æ¯å¹¶ç‰å¾…下个包到达之åŽè¿›è¡Œæ‹¼åŒ…åˆå¹¶ï¼Œç›´åˆ°è¯»å–一个完整的消æ¯åŒ…;如果是粘包消æ¯ï¼Œç©ºä½™çš„ä½ç½®ä¼šè¿›è¡Œè¡¥ 0,会浪费空间
```java
serverBootstrap.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new FixedLengthFrameDecoder(10));
// LoggingHandler 用æ¥æ‰“å°æ¶ˆæ¯
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
}
});
```
```java
10:29:06.522 [nioEventLoopGroup-3-1] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0x38a70fbf, L:/127.0.0.1:8080 - R:/127.0.0.1:10144] READ: 10B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 31 31 00 00 00 00 00 00 00 00 |11........ |
+--------+-------------------------------------------------+----------------+
10:29:06.522 [nioEventLoopGroup-3-1] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0x38a70fbf, L:/127.0.0.1:8080 - R:/127.0.0.1:10144] READ: 10B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 32 32 32 32 32 32 00 00 00 00 |222222.... |
+--------+-------------------------------------------------+----------------+
```
****
#### 分隔符
æœåŠ¡ç«¯åŠ 入行解ç 器,默认以 `\n` 或 `\r\n` 作为分隔符,如果超出指定长度ä»æœªå‡ºçŽ°åˆ†éš”符,则抛出异常:
```java
serverBootstrap.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new FixedLengthFrameDecoder(8));
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
}
});
```
客户端在æ¯æ¡æ¶ˆæ¯ä¹‹åŽï¼ŒåŠ å…¥ `\n` 分隔符:
```java
public void channelActive(ChannelHandlerContext ctx) throws Exception {
Random r = new Random();
char c = 'a';
ByteBuf buffer = ctx.alloc().buffer();
for (int i = 0; i < 10; i++) {
for (int j = 1; j <= r.nextInt(16)+1; j++) {
buffer.writeByte((byte) c);
}
// 10 代表 '\n'
buffer.writeByte(10);
c++;
}
ctx.writeAndFlush(buffer);
}
```
****
#### 预设长度
LengthFieldBasedFrameDecoder 解ç 器自定义长度解决 TCP 粘包é»åŒ…问题
```java
int maxFrameLength // æ•°æ®æœ€å¤§é•¿åº¦
int lengthFieldOffset // 长度å—段å移é‡ï¼Œä»Žç¬¬å‡ 个å—节开始是内容的长度å—段
int lengthFieldLength // 长度å—段本身的长度
int lengthAdjustment // 长度å—æ®µä¸ºåŸºå‡†ï¼Œå‡ ä¸ªå—节åŽæ‰æ˜¯å†…容
int initialBytesToStrip // ä»Žå¤´å¼€å§‹å‰¥ç¦»å‡ ä¸ªå—节解ç åŽæ˜¾ç¤º
```
```java
lengthFieldOffset = 1 (= the length of HDR1)
lengthFieldLength = 2
lengthAdjustment = 1 (= the length of HDR2)
initialBytesToStrip = 3 (= the length of HDR1 + LEN)
BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)//解ç
+------+--------+------+----------------+ +------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+------+--------+------+----------------+ +------+----------------+
```
代ç 实现:
```java
public class LengthFieldDecoderDemo {
public static void main(String[] args) {
EmbeddedChannel channel = new EmbeddedChannel(
// int å 4 å—节,版本å·ä¸€ä¸ªå—节
new LengthFieldBasedFrameDecoder(1024, 0, 4, 1,5),
new LoggingHandler(LogLevel.DEBUG)
);
// 4 个å—节的内容长度, 实际内容
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();
send(buffer, "Hello, world");
send(buffer, "Hi!");
// 写出缓å˜
channel.writeInbound(buffer);
}
// 写入缓å˜
private static void send(ByteBuf buffer, String content) {
byte[] bytes = content.getBytes(); // 实际内容
int length = bytes.length; // 实际内容长度
buffer.writeInt(length);
buffer.writeByte(1); // 表示版本å·
buffer.writeBytes(bytes);
}
}
```
```java
10:49:59.344 [main] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0xembedded, L:embedded - R:embedded] READ: 12B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 65 6c 6c 6f 2c 20 77 6f 72 6c 64 |Hello, world |
+--------+-------------------------------------------------+----------------+
10:49:59.344 [main] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0xembedded, L:embedded - R:embedded] READ: 3B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 69 21 |Hi! |
+--------+-------------------------------------------------+----------------+
```
****
### å议设计
#### HTTP
访问 URL:http://localhost:8080/
```java
public class HttpDemo {
public static void main(String[] args) {
NioEventLoopGroup boss = new NioEventLoopGroup();
NioEventLoopGroup worker = new NioEventLoopGroup();
try {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(boss, worker);
serverBootstrap.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
ch.pipeline().addLast(new HttpServerCodec());
// åªé’ˆå¯¹æŸä¸€ç§ç±»åž‹çš„请求处ç†ï¼Œæ¤å¤„针对 HttpRequest
ch.pipeline().addLast(new SimpleChannelInboundHandler() {
@Override
protected void channelRead0(ChannelHandlerContext ctx, HttpRequest msg) throws Exception {
// 获å–请求
log.debug(msg.uri());
// 返回å“应
DefaultFullHttpResponse response = new DefaultFullHttpResponse(
msg.protocolVersion(), HttpResponseStatus.OK);
byte[] bytes = "
***
## 基本实现
å¼€å‘简å•çš„æœåŠ¡å™¨ç«¯å’Œå®¢æˆ·ç«¯ï¼ŒåŸºæœ¬ä»‹ç»ï¼š
* channel ç†è§£ä¸ºæ•°æ®çš„通é“,把 msg ç†è§£ä¸ºæµåŠ¨çš„æ•°æ®ï¼Œæœ€å¼€å§‹è¾“入是 ByteBuf,但ç»è¿‡ pipeline çš„åŠ å·¥ï¼Œä¼šå˜æˆå…¶å®ƒç±»åž‹å¯¹è±¡ï¼Œæœ€åŽè¾“出åˆå˜æˆ ByteBuf
* handler ç†è§£ä¸ºæ•°æ®çš„处ç†å·¥åºï¼Œpipeline è´Ÿè´£å‘å¸ƒäº‹ä»¶ä¼ æ’ç»™æ¯ä¸ª handler,handler 对自己感兴趣的事件进行处ç†ï¼ˆé‡å†™äº†ç›¸åº”事件处ç†æ–¹æ³•ï¼‰ï¼Œåˆ† Inbound å’Œ Outbound 两类
* eventLoop ç†è§£ä¸ºå¤„ç†æ•°æ®çš„执行者,既å¯ä»¥æ‰§è¡Œ IO æ“作,也å¯ä»¥è¿›è¡Œä»»åŠ¡å¤„ç†ã€‚æ¯ä¸ªæ‰§è¡Œè€…有任务队列,队列里å¯ä»¥å †æ”¾å¤šä¸ª channel 的待处ç†ä»»åŠ¡ï¼Œä»»åŠ¡åˆ†ä¸ºæ™®é€šä»»åŠ¡ã€å®šæ—¶ä»»åŠ¡ã€‚按照 pipeline 顺åºï¼Œä¾æ¬¡æŒ‰ç…§ handler 的规划(代ç )处ç†æ•°æ®
代ç 实现:
* pom.xml
```xml
io.netty
netty-all
4.1.20.Final
```
* Server.java
```java
public class HelloServer {
public static void main(String[] args) {
EventLoopGroup boss = new NioEventLoopGroup();
EventLoopGroup worker = new NioEventLoopGroup(2);
// 1. å¯åŠ¨å™¨ï¼Œè´Ÿè´£ç»„装 netty 组件,å¯åŠ¨æœåŠ¡å™¨
new ServerBootstrap()
// 2. 线程组,boss åªè´Ÿè´£ã€å¤„ç† accept 事件】, worker åªã€è´Ÿè´£ channel 上的读写】
.group(boss, worker)
//.option() // ç»™ ServerSocketChannel é…ç½®å‚æ•°
//.childOption() // ç»™ SocketChannel é…ç½®å‚æ•°
// 3. 选择æœåŠ¡å™¨çš„ ServerSocketChannel 实现
.channel(NioServerSocketChannel.class)
// 4. boss 负责处ç†è¿žæŽ¥ï¼Œworker(child) 负责处ç†è¯»å†™ï¼Œå†³å®šäº†èƒ½æ‰§è¡Œå“ªäº›æ“作(handler)
.childHandler(new ChannelInitializer() {
// 5. channel 代表和客户端进行数æ®è¯»å†™çš„é€šé“ Initializer åˆå§‹åŒ–ï¼Œè´Ÿè´£æ·»åŠ åˆ«çš„ handler
// 7. 连接建立åŽï¼Œæ‰§è¡Œåˆå§‹åŒ–方法
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// æ·»åŠ å…·ä½“çš„ handler
ch.pipeline().addLast(new StringDecoder());// å°† ByteBuf 转æˆå—符串
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() { // 自定义 handler
// 读事件
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
// 打å°è½¬æ¢å¥½çš„å—符串
System.out.println(msg);
}
});
}
})
// 6. 绑定监å¬ç«¯å£
.bind(8080);
}
}
```
* Client.java
```java
public class HelloClient {
public static void main(String[] args) throws InterruptedException {
// 1. 创建å¯åŠ¨å™¨ç±»
new Bootstrap()
// 2. æ·»åŠ EventLoop
.group(new NioEventLoopGroup())
//.option() //ç»™ SocketChannel é…ç½®å‚æ•°
// 3. 选择客户端 channel 实现
.channel(NioSocketChannel.class)
// 4. æ·»åŠ å¤„ç†å™¨
.handler(new ChannelInitializer() {
// 4.1 连接建立åŽè¢«è°ƒç”¨
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// 将 Hello World 转为 ByteBuf
ch.pipeline().addLast(new StringEncoder());
}
})
// 5. 连接到æœåŠ¡å™¨ï¼Œç„¶åŽè°ƒç”¨ 4.1
.connect(new InetSocketAddress("127.0.0.1",8080))
// 6. 阻塞方法,直到连接建立
.sync()
// 7. 代表连接对象
.channel()
// 8. å‘æœåŠ¡å™¨å‘é€æ•°æ®
.writeAndFlush("Hello World");
}
}
```
å‚考视频:https://www.bilibili.com/video/BV1py4y1E7oA
****
## 组件介ç»
### EventLoop
#### 基本介ç»
事件循环对象 EventLoop,**本质是一个å•çº¿ç¨‹æ‰§è¡Œå™¨åŒæ—¶ç»´æŠ¤äº†ä¸€ä¸ª Selector**,有 run æ–¹æ³•å¤„ç† Channel 上æºæºä¸æ–çš„ IO 事件
事件循环组 EventLoopGroup 是一组 EventLoop,Channel 会调用 Boss EventLoopGroup çš„ register 方法æ¥ç»‘定其ä¸ä¸€ä¸ª Worker çš„ EventLoop,åŽç»è¿™ä¸ª Channel 上的 IO äº‹ä»¶éƒ½ç”±æ¤ EventLoop æ¥å¤„ç†ï¼Œä¿è¯äº†äº‹ä»¶å¤„ç†æ—¶çš„线程安全
EventLoopGroup 类 API:
* `EventLoop next()`:获å–集åˆä¸ä¸‹ä¸€ä¸ª EventLoop,EventLoopGroup 实现了 Iterable 接å£æä¾›é历 EventLoop 的能力
* `Future> shutdownGracefully()`:优雅关é—çš„æ–¹æ³•ï¼Œä¼šé¦–å…ˆåˆ‡æ¢ EventLoopGroup 到关é—状æ€ä»Žè€Œæ‹’ç»æ–°çš„ä»»åŠ¡çš„åŠ å…¥ï¼Œç„¶åŽåœ¨ä»»åŠ¡é˜Ÿåˆ—的任务都处ç†å®ŒæˆåŽï¼Œåœæ¢çº¿ç¨‹çš„è¿è¡Œï¼Œä»Žè€Œç¡®ä¿æ•´ä½“应用是在æ£å¸¸æœ‰åºçš„状æ€ä¸‹é€€å‡ºçš„
* ` Future submit(Callable task)`:æ交任务
* `ScheduledFuture> scheduleWithFixedDelay`:æ交定时任务
***
#### ä»»åŠ¡ä¼ é€’
把è¦è°ƒç”¨çš„代ç å°è£…为一个任务对象,由下一个 handler 的线程æ¥è°ƒç”¨
```java
public class EventLoopServer {
public static void main(String[] args) {
EventLoopGroup group = new DefaultEventLoopGroup();
new ServerBootstrap()
.group(new NioEventLoopGroup(), new NioEventLoopGroup(2))
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) {
ch.pipeline().addLast("handler1", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf buf = (ByteBuf) msg;
log.debug(buf.toString(Charset.defaultCharset()));
ctx.fireChannelRead(msg); // 让消æ¯ã€ä¼ 递】给下一个 handler
}
}).addLast(group, "handler2", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf buf = (ByteBuf) msg;
log.debug(buf.toString(Charset.defaultCharset()));
}
});
}
})
.bind(8080);
}
}
```
æºç 分æžï¼š
```java
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(MASK_CHANNEL_READ), msg);
return this;
}
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
// 下一个 handler 的事件循环是å¦ä¸Žå½“å‰çš„事件循环是åŒä¸€ä¸ªçº¿ç¨‹
if (executor.inEventLoop()) {
// 是,直接调用
next.invokeChannelRead(m);
} else {
// ä¸æ˜¯ï¼Œå°†è¦æ‰§è¡Œçš„代ç 作为任务æ交给下一个 handler 处ç†
executor.execute(new Runnable() {
@Override
public void run() {
next.invokeChannelRead(m);
}
});
}
}
```
****
### Channel
#### 连接æ“作
Channel 类 API:
* `ChannelFuture close()`:关é—通é“
* `ChannelPipeline pipeline()`ï¼šæ·»åŠ å¤„ç†å™¨
* `ChannelFuture write(Object msg)`:数æ®å†™å…¥ç¼“冲区
* `ChannelFuture writeAndFlush(Object msg)`:数æ®å†™å…¥ç¼“冲区并且刷出
ChannelFuture 类 API:
* `ChannelFuture sync()`:åŒæ¥é˜»å¡žç‰å¾…连接æˆåŠŸ
* `ChannelFuture addListener(GenericFutureListener listener)`:异æ¥ç‰å¾…
代ç 实现:
* connect 方法是异æ¥çš„,ä¸ç‰è¿žæŽ¥å»ºç«‹å®Œæˆå°±è¿”å›žï¼Œå› æ¤ channelFuture 对象ä¸ä¸èƒ½ç«‹åˆ»èŽ·å¾—到æ£ç¡®çš„ Channel 对象,需è¦ç‰å¾…
* 连接未建立 channel 打å°ä¸º `[id: 0x2e1884dd]`;建立æˆåŠŸæ‰“å°ä¸º `[id: 0x2e1884dd, L:/127.0.0.1:57191 - R:/127.0.0.1:8080]`
```java
public class ChannelClient {
public static void main(String[] args) throws InterruptedException {
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new StringEncoder());
}
})
// 1. 连接æœåŠ¡å™¨ï¼Œã€å¼‚æ¥éžé˜»å¡žã€‘,main 调用 connect 方法,真æ£æ‰§è¡Œè¿žæŽ¥çš„是 nio 线程
.connect(new InetSocketAddress("127.0.0.1", 8080));
// 2.1 使用 sync 方法ã€åŒæ¥ã€‘处ç†ç»“果,阻塞当å‰çº¿ç¨‹ï¼Œç›´åˆ° nio 线程连接建立完毕
channelFuture.sync();
Channel channel = channelFuture.channel();
System.out.println(channel); // ã€æ‰“å°ã€‘
// å‘æœåŠ¡å™¨å‘é€æ•°æ®
channel.writeAndFlush("hello world");
**************************************************************************************二选一
// 2.2 使用 addListener 方法ã€å¼‚æ¥ã€‘处ç†ç»“æžœ
channelFuture.addListener(new ChannelFutureListener() {
@Override
// nio 线程连接建立好以åŽï¼Œå›žè°ƒè¯¥æ–¹æ³•
public void operationComplete(ChannelFuture future) throws Exception {
Channel channel = future.channel();
channel.writeAndFlush("hello, world");
}
});
}
}
```
***
#### å…³é—æ“作
å…³é— EventLoopGroup çš„è¿è¡Œï¼Œåˆ†ä¸ºåŒæ¥å…³é—和异æ¥å…³é—
```java
public class CloseFutureClient {
public static void main(String[] args) throws InterruptedException {
NioEventLoopGroup group = new NioEventLoopGroup();
ChannelFuture channelFuture = new Bootstrap()
.group(group)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
ch.pipeline().addLast(new StringEncoder());
}
})
.connect(new InetSocketAddress("127.0.0.1", 8080));
Channel channel = channelFuture.sync().channel();
// å‘é€æ•°æ®
new Thread(() -> {
Scanner sc = new Scanner(System.in);
while (true) {
String line = sc.nextLine();
if (line.equals("q")) {
channel.close();
break;
}
channel.writeAndFlush(line);
}
}, "input").start();
// èŽ·å– CloseFuture 对象
ChannelFuture closeFuture = channel.closeFuture();
// 1. åŒæ¥å¤„ç†å…³é—
System.out.println("waiting close...");
closeFuture.sync();
System.out.println("处ç†å…³é—åŽçš„æ“作");
****************************************************
// 2. 异æ¥å¤„ç†å…³é—
closeFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
System.out.println("处ç†å…³é—åŽçš„æ“作");
group.shutdownGracefully();
}
});
}
}
```
****
### Future
#### 基本介ç»
Netty ä¸çš„ Future 与 JDK ä¸çš„ Future åŒå,但是功能的实现ä¸åŒ
```java
package io.netty.util.concurrent;
public interface Future extends java.util.concurrent.Future
```
Future 类 API:
* `V get()`:阻塞ç‰å¾…获å–任务执行结果
* `V getNow()`:éžé˜»å¡žèŽ·å–任务结果,还未产生结果时返回 null
* `Throwable cause()`:éžé˜»å¡žèŽ·å–失败信æ¯ï¼Œå¦‚果没有失败,返回 null
* `Future sync()`:ç‰å¾…任务结æŸï¼Œå¦‚果任务失败,抛出异常
* `boolean cancel(boolean mayInterruptIfRunning)`:å–消任务
* `Future addListener(GenericFutureListener listener)`ï¼šæ·»åŠ å›žè°ƒï¼Œå¼‚æ¥æŽ¥æ”¶ç»“æžœ
* `boolean isSuccess()`:判æ–任务是å¦æˆåŠŸ
* `boolean isCancellable()`:判æ–任务是å¦å–消
```java
public class NettyFutureDemo {
public static void main(String[] args) throws Exception {
NioEventLoopGroup group = new NioEventLoopGroup();
EventLoop eventLoop = group.next();
Future future = eventLoop.submit(new Callable() {
@Override
public Integer call() throws Exception {
System.out.println("执行计算");
Thread.sleep(1000);
return 70;
}
});
future.getNow();
System.out.println(new Date() + "ç‰å¾…结果");
System.out.println(new Date() + "" + future.get());
}
}
```
****
#### 扩展åç±»
Promise 类是 Future çš„å类,å¯ä»¥è„±ç¦»ä»»åŠ¡ç‹¬ç«‹å˜åœ¨ï¼Œä½œä¸ºä¸¤ä¸ªçº¿ç¨‹é—´ä¼ 递结果的容器
```java
public interface Promise extends Future
```
Promise 类 API:
* `Promise setSuccess(V result)`:设置æˆåŠŸç»“æžœ
* `Promise setFailure(Throwable cause)`:设置失败结果
```java
public class NettyPromiseDemo {
public static void main(String[] args) throws Exception {
// 1. 准备 EventLoop 对象
EventLoop eventLoop = new NioEventLoopGroup().next();
// 2. 主动创建 promise
DefaultPromise promise = new DefaultPromise<>(eventLoop);
// 3. ä»»æ„一个线程执行计算,计算完毕åŽå‘ promise 填充结果
new Thread(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
promise.setSuccess(200);
}).start();
// 4. 接å—结果的线程
System.out.println(new Date() + "ç‰å¾…结果");
System.out.println(new Date() + "" + promise.get());
}
}
```
****
### Pipeline
ChannelHandler 用æ¥å¤„ç† Channel 上的å„ç§äº‹ä»¶ï¼Œåˆ†ä¸ºå…¥ç«™å‡ºç«™ä¸¤ç§ï¼Œæ‰€æœ‰ ChannelHandler 连接æˆåŒå‘链表就是 Pipeline
* 入站处ç†å™¨é€šå¸¸æ˜¯ ChannelInboundHandlerAdapter çš„å类,主è¦ç”¨æ¥è¯»å–客户端数æ®ï¼Œå†™å›žç»“æžœ
* 出站处ç†å™¨é€šå¸¸æ˜¯ ChannelOutboundHandlerAdapter çš„å类,主è¦å¯¹å†™å›žç»“æžœè¿›è¡ŒåŠ å·¥ï¼ˆå…¥ç«™å’Œå‡ºç«™æ˜¯å¯¹äºŽæœåŠ¡ç«¯æ¥è¯´çš„)
```java
public static void main(String[] args) {
new ServerBootstrap()
.group(new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
// 1. 通过 channel 拿到 pipeline
ChannelPipeline pipeline = ch.pipeline();
// 2. æ·»åŠ å¤„ç†å™¨ head -> h1 -> h2 -> h3 -> h4 -> h5 -> h6 -> tail
pipeline.addLast("h1", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("1");
ByteBuf buf = (ByteBuf) msg;
String s = buf.toString(Charset.defaultCharset());
// 将数æ®ä¼ 递给下一个ã€å…¥ç«™ã€‘handler,如果ä¸è°ƒç”¨è¯¥æ–¹æ³•åˆ™é“¾ä¼šæ–å¼€
super.channelRead(ctx, s);
}
});
pipeline.addLast("h2", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("2");
// 从ã€å°¾éƒ¨å¼€å§‹å‘å‰è§¦å‘】出站处ç†å™¨
ch.writeAndFlush(ctx.alloc().buffer().writeBytes("server".getBytes()));
// 该方法会让管é“从ã€å½“å‰ handler å‘å‰ã€‘寻找出站处ç†å™¨
// ctx.writeAndFlush();
}
});
pipeline.addLast("h3", new ChannelOutboundHandlerAdapter() {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("3");
super.write(ctx, msg, promise);
}
});
pipeline.addLast("h4", new ChannelOutboundHandlerAdapter() {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("4");
super.write(ctx, msg, promise);
}
});
}
})
.bind(8080);
}
```
æœåŠ¡å™¨ç«¯ä¾æ¬¡æ‰“å°ï¼š1 2 4 3 ,所以**入站是按照 addLast 的顺åºæ‰§è¡Œçš„,出站是按照 addLast 的逆åºæ‰§è¡Œ**
一个 Channel 包å«äº†ä¸€ä¸ª ChannelPipeline,而 ChannelPipeline ä¸åˆç»´æŠ¤äº†ä¸€ä¸ªç”± ChannelHandlerContext 组æˆçš„åŒå‘链表,并且æ¯ä¸ª ChannelHandlerContext ä¸å…³è”ç€ä¸€ä¸ª ChannelHandler
入站事件和出站事件在一个åŒå‘链表ä¸ï¼Œä¸¤ç§ç±»åž‹çš„ handler 互ä¸å¹²æ‰°ï¼š
* 入站事件会从链表 head å¾€åŽä¼ 递到最åŽä¸€ä¸ªå…¥ç«™çš„ handler
* 出站事件会从链表 tail å¾€å‰ä¼ 递到最å‰ä¸€ä¸ªå‡ºç«™çš„ handler

****
### ByteBuf
#### 基本介ç»
ByteBuf 是对å—节数æ®çš„å°è£…,优点:
* æ± åŒ–ï¼Œå¯ä»¥é‡ç”¨æ± ä¸ ByteBuf 实例,更节约内å˜ï¼Œå‡å°‘内å˜æº¢å‡ºçš„å¯èƒ½
* 读写指针分离,ä¸éœ€è¦åƒ ByteBuffer ä¸€æ ·åˆ‡æ¢è¯»å†™æ¨¡å¼
* å¯ä»¥è‡ªåŠ¨æ‰©å®¹
* 支æŒé“¾å¼è°ƒç”¨ï¼Œä½¿ç”¨æ›´æµç•…
* 零拷è´æ€æƒ³ï¼Œä¾‹å¦‚ sliceã€duplicateã€CompositeByteBuf
****
#### 创建方法
创建方å¼
* `ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10)`:创建了一个默认的 ByteBuf,åˆå§‹å®¹é‡æ˜¯ 10
```java
public ByteBuf buffer() {
if (directByDefault) {
return directBuffer();
}
return heapBuffer();
}
```
* `ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(10)`ï¼šåˆ›å»ºæ± åŒ–åŸºäºŽå †çš„ ByteBuf
* `ByteBuf buffer = ByteBufAllocator.DEFAULT.directBuffer(10)`ï¼šåˆ›å»ºæ± åŒ–åŸºäºŽç›´æŽ¥å†…å˜çš„ ByteBuf
* **推è**的创建方å¼ï¼šåœ¨æ·»åŠ 处ç†å™¨çš„方法ä¸
```java
pipeline.addLast(new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buffer = ctx.alloc().buffer();
}
});
```
直接内å˜å¯¹æ¯”å †å†…å˜ï¼š
* 直接内å˜åˆ›å»ºå’Œé”€æ¯çš„代价昂贵,但读写性能高(少一次内å˜å¤åˆ¶ï¼‰ï¼Œé€‚åˆé…åˆæ± 化功能一起用
* 直接内å˜å¯¹ GC 压力å°ï¼Œå› 为这部分内å˜ä¸å— JVM 垃圾回收的管ç†ï¼Œä½†ä¹Ÿè¦æ³¨æ„åŠæ—¶ä¸»åŠ¨é‡Šæ”¾
æ± åŒ–çš„æ„义在于å¯ä»¥**é‡ç”¨ ByteBuf**,高并å‘æ—¶æ± åŒ–åŠŸèƒ½æ›´èŠ‚çº¦å†…å˜ï¼Œå‡å°‘内å˜æº¢å‡ºçš„å¯èƒ½ï¼Œä¸Žéžæ± 化对比:
* éžæ± 化,æ¯æ¬¡éƒ½è¦åˆ›å»ºæ–°çš„ ByteBuf 实例,这个æ“作对直接内å˜ä»£ä»·æ˜‚è´µï¼Œå †å†…å˜ä¼šå¢žåŠ GC 压力
* æ± åŒ–ï¼Œå¯ä»¥é‡ç”¨æ± ä¸ ByteBuf 实例,并且采用了与 jemalloc 类似的内å˜åˆ†é…算法æå‡åˆ†é…效率
æ± åŒ–åŠŸèƒ½çš„å¼€å¯ï¼Œå¯ä»¥é€šè¿‡ä¸‹é¢çš„系统环境å˜é‡æ¥è®¾ç½®ï¼š
```sh
-Dio.netty.allocator.type={unpooled|pooled} # VM å‚æ•°
```
* 4.1 以åŽï¼Œéž Android å¹³å°é»˜è®¤å¯ç”¨æ± 化实现,Android å¹³å°å¯ç”¨éžæ± 化实现
* 4.1 之å‰ï¼Œæ± 化功能还ä¸æˆç†Ÿï¼Œé»˜è®¤æ˜¯éžæ± 化实现
****
#### 读写æ“作
ByteBuf 由四部分组æˆï¼Œæœ€å¼€å§‹è¯»å†™æŒ‡é’ˆï¼ˆ**åŒæŒ‡é’ˆ**)都在 0 ä½ç½®

写入方法:
| 方法å | 说明 | 备注 |
| ------------------------------------------------ | ---------------------- | ------------------------------------------- |
| writeBoolean(boolean value) | 写入 boolean 值 | 用一å—节 01\|00 代表 true\|false |
| writeByte(int value) | 写入 byte 值 | |
| writeInt(int value) | 写入 int 值 | Big Endianï¼Œå³ 0x250ï¼Œå†™å…¥åŽ 00 00 02 50 |
| writeIntLE(int value) | 写入 int 值 | Little Endianï¼Œå³ 0x250ï¼Œå†™å…¥åŽ 50 02 00 00 |
| writeBytes(ByteBuf src) | 写入 ByteBuf | |
| writeBytes(byte[] src) | 写入 byte[] | |
| writeBytes(ByteBuffer src) | 写入 NIO 的 ByteBuffer | |
| int writeCharSequence(CharSequence s, Charset c) | 写入å—符串 | |
* 这些方法的未指明返回值的,其返回值都是 ByteBuf,æ„味ç€å¯ä»¥é“¾å¼è°ƒç”¨
* å†™å…¥å‡ ä½å†™æŒ‡é’ˆåŽç§»å‡ ä½ï¼ŒæŒ‡å‘å¯ä»¥å†™å…¥çš„ä½ç½®
* ç½‘ç»œä¼ è¾“ï¼Œé»˜è®¤ä¹ æƒ¯æ˜¯ Big Endian
扩容:写入数æ®æ—¶ï¼Œå®¹é‡ä¸å¤Ÿäº†ï¼ˆåˆå§‹å®¹é‡æ˜¯ 10),这时会引å‘扩容
* 如果写入åŽæ•°æ®å¤§å°æœªè¶…过 512,则选择下一个 16 çš„æ•´æ•°å€ï¼Œä¾‹å¦‚写入åŽå¤§å°ä¸º 12 ï¼Œåˆ™æ‰©å®¹åŽ capacity 是 16
* 如果写入åŽæ•°æ®å¤§å°è¶…过 512,则选择下一个 2^n,例如写入åŽå¤§å°ä¸º 513ï¼Œåˆ™æ‰©å®¹åŽ capacity 是 2^10 = 1024(2^9=512 ä¸å¤Ÿï¼‰
* 扩容ä¸èƒ½è¶…过 max capacity 会报错
读å–方法:
* `byte readByte()`:读å–一个å—节,读指针åŽç§»
* `byte getByte(int index)`:读å–指定索引ä½ç½®çš„å—节,读指针ä¸åŠ¨
* `ByteBuf markReaderIndex()`ï¼šæ ‡è®°è¯»æ•°æ®çš„ä½ç½®
* `ByteBuf resetReaderIndex()`:é‡ç½®åˆ°æ ‡è®°ä½ç½®ï¼Œå¯ä»¥é‡å¤è¯»å–æ ‡è®°ä½ç½®å‘åŽçš„æ•°æ®
****
#### 内å˜é‡Šæ”¾
Netty ä¸ä¸‰ç§å†…å˜çš„回收:
* UnpooledHeapByteBuf 使用的是 JVM 内å˜ï¼Œåªéœ€ç‰ GC 回收内å˜
* UnpooledDirectByteBuf 使用的就是直接内å˜äº†ï¼Œéœ€è¦ç‰¹æ®Šçš„方法æ¥å›žæ”¶å†…å˜
* PooledByteBuf å’Œåç±»ä½¿ç”¨äº†æ± åŒ–æœºåˆ¶ï¼Œéœ€è¦æ›´å¤æ‚的规则æ¥å›žæ”¶å†…å˜
Netty 采用了引用计数法æ¥æŽ§åˆ¶å›žæ”¶å†…å˜ï¼Œæ¯ä¸ª ByteBuf 都实现了 ReferenceCounted 接å£ï¼Œå›žæ”¶çš„规则:
* æ¯ä¸ª ByteBuf 对象的åˆå§‹è®¡æ•°ä¸º 1
* 调用 release æ–¹æ³•è®¡æ•°å‡ 1,如果计数为 0,ByteBuf 内å˜è¢«å›žæ”¶
* 调用 retain æ–¹æ³•è®¡æ•°åŠ 1,表示调用者没用完之å‰ï¼Œå…¶å®ƒ handler å³ä½¿è°ƒç”¨äº† release 也ä¸ä¼šé€ æˆå›žæ”¶
* 当计数为 0 时,底层内å˜ä¼šè¢«å›žæ”¶ï¼Œè¿™æ—¶å³ä½¿ ByteBuf 对象还在,其å„个方法å‡æ— 法æ£å¸¸ä½¿ç”¨
```java
ByteBuf buf = .ByteBufAllocator.DEFAULT.buffer(10)
try {
// 逻辑处ç†
} finally {
buf.release();
}
```
Pipeline çš„å˜åœ¨ï¼Œéœ€è¦å°† ByteBuf ä¼ é€’ç»™ä¸‹ä¸€ä¸ª ChannelHandler,如果在 finally ä¸ release äº†ï¼Œå°±å¤±åŽ»äº†ä¼ é€’æ€§ï¼Œå¤„ç†è§„则:
* 创建 ByteBuf 放入 pipeline
* 入站 ByteBuf 处ç†åŽŸåˆ™
* 对原始 ByteBuf ä¸åšå¤„ç†ï¼Œè°ƒç”¨ ctx.fireChannelRead(msg) å‘åŽä¼ é€’ï¼Œè¿™æ—¶æ— é¡» release
* 将原始 ByteBuf 转æ¢ä¸ºå…¶å®ƒç±»åž‹çš„ Java 对象,这时 ByteBuf 就没用了,æ¤æ—¶å¿…é¡» release
* 如果ä¸è°ƒç”¨ ctx.fireChannelRead(msg) å‘åŽä¼ 递,那么也必须 release
* 如果出现异常,ByteBuf 没有æˆåŠŸä¼ 递到下一个 ChannelHandler,必须 release
* å‡è®¾æ¶ˆæ¯ä¸€ç›´å‘åŽä¼ ,那么 TailContext 会负责释放未处ç†æ¶ˆæ¯ï¼ˆåŽŸå§‹çš„ ByteBuf)
```java
// io.netty.channel.DefaultChannelPipeline#onUnhandledInboundMessage(java.lang.Object)
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug();
} finally {
ReferenceCountUtil.release(msg);
}
}
// io.netty.util.ReferenceCountUtil#release(java.lang.Object)
public static boolean release(Object msg) {
if (msg instanceof ReferenceCounted) {
return ((ReferenceCounted) msg).release();
}
return false;
}
```
* 出站 ByteBuf 处ç†åŽŸåˆ™
* 出站消æ¯æœ€ç»ˆéƒ½ä¼šè½¬ä¸º ByteBuf 输出,一直å‘å‰ä¼ ,由 HeadContext flush åŽ release
* ä¸ç¡®å®š ByteBuf 被引用了多少次,但åˆå¿…须彻底释放,å¯ä»¥å¾ªçŽ¯è°ƒç”¨ release 直到返回 true
****
#### æ‹·è´æ“作
零拷è´æ–¹æ³•ï¼š
* `ByteBuf slice(int index, int length)`:对原始 ByteBuf 进行切片æˆå¤šä¸ª ByteBuf,切片åŽçš„ ByteBuf 并没有å‘生内å˜å¤åˆ¶ï¼Œ**共用原始 ByteBuf 的内å˜**,切片åŽçš„ ByteBuf 维护独立的 read,write 指针
```java
public static void main(String[] args) {
ByteBuf buf = ByteBufAllocator.DEFAULT.buffer(10);
buf.writeBytes(new byte[]{'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j'});
// 在切片过程ä¸å¹¶æ²¡æœ‰å‘生数æ®å¤åˆ¶
ByteBuf f1 = buf.slice(0, 5);
f1.retain();
ByteBuf f2 = buf.slice(5, 5);
f2.retain();
// 对 f1 进行相关的æ“作也会体现在 buf 上
}
```
* `ByteBuf duplicate()`:截å–原始 ByteBuf 所有内容,并且没有 max capacity çš„é™åˆ¶ï¼Œä¹Ÿæ˜¯ä¸ŽåŽŸå§‹ ByteBuf 使用åŒä¸€å—底层内å˜ï¼Œåªæ˜¯è¯»å†™æŒ‡é’ˆæ˜¯ç‹¬ç«‹çš„
* `CompositeByteBuf addComponents(boolean increaseWriterIndex, ByteBuf... buffers)`:åˆå¹¶å¤šä¸ª ByteBuf
```java
public static void main(String[] args) {
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer();
buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer();
buf1.writeBytes(new byte[]{6, 7, 8, 9, 10});
CompositeByteBuf buf = ByteBufAllocator.DEFAULT.compositeBuffer();
// true è¡¨ç¤ºå¢žåŠ æ–°çš„ ByteBuf 自动递增 write index, å¦åˆ™ write index 会始终为 0
buf.addComponents(true, buf1, buf2);
}
```
CompositeByteBuf 是一个组åˆçš„ ByteBuf,内部维护了一个 Component 数组,æ¯ä¸ª Component 管ç†ä¸€ä¸ª ByteBuf,记录了这个 ByteBuf 相对于整体å移é‡ç‰ä¿¡æ¯ï¼Œä»£è¡¨ç€æ•´ä½“ä¸æŸä¸€æ®µçš„æ•°æ®
* 优点:对外是一个虚拟视图,组åˆè¿™äº› ByteBuf ä¸ä¼šäº§ç”Ÿå†…å˜å¤åˆ¶
* 缺点:å¤æ‚了很多,多次æ“作会带æ¥æ€§èƒ½çš„æŸè€—
深拷è´ï¼š
* `ByteBuf copy()`:将底层内å˜æ•°æ®è¿›è¡Œæ·±æ‹·è´ï¼Œå› æ¤æ— 论读写,都与原始 ByteBuf æ— å…³
æ± åŒ–ç›¸å…³ï¼š
* Unpooled 是一个工具类,æ供了éžæ± 化的 ByteBuf 创建ã€ç»„åˆã€å¤åˆ¶ç‰æ“作
```java
ByteBuf buf1 = ByteBufAllocator.DEFAULT.buffer(5);
buf1.writeBytes(new byte[]{1, 2, 3, 4, 5});
ByteBuf buf2 = ByteBufAllocator.DEFAULT.buffer(5);
buf2.writeBytes(new byte[]{6, 7, 8, 9, 10});
// 当包装 ByteBuf 个数超过一个时, 底层使用了 CompositeByteBuf,零拷è´æ€æƒ³
ByteBuf buf = Unpooled.wrappedBuffer(buf1, buf2);
```
****
## 粘包åŠåŒ…
### 现象演示
在 TCP ä¼ è¾“ä¸ï¼Œå®¢æˆ·ç«¯å‘é€æ¶ˆæ¯æ—¶ï¼Œå®žé™…上是将数æ®å†™å…¥ TCP 的缓å˜ï¼Œæ¤æ—¶æ•°æ®çš„大å°å’Œç¼“å˜çš„大å°å°±ä¼šé€ æˆç²˜åŒ…å’ŒåŠåŒ…
* 当数æ®è¶…过 TCP 缓å˜å®¹é‡æ—¶ï¼Œå°±ä¼šè¢«æ‹†åˆ†æˆå¤šä¸ªåŒ…,通过 Socket 多次å‘é€åˆ°æœåŠ¡ç«¯ï¼ŒæœåŠ¡ç«¯æ¯æ¬¡ä»Žç¼“å˜ä¸å–æ•°æ®ï¼Œäº§ç”ŸåŠåŒ…问题
* 当数æ®å°äºŽ TCP 缓å˜å®¹é‡æ—¶ï¼Œç¼“å˜ä¸å¯ä»¥å˜æ”¾å¤šä¸ªåŒ…,客户端和æœåŠ¡ç«¯ä¸€æ¬¡é€šä¿¡å°±å¯èƒ½ä¼ 递多个包,这时候æœåŠ¡ç«¯å°±å¯èƒ½ä¸€æ¬¡è¯»å–多个包,产生粘包的问题
代ç 演示:
* 客户端代ç :
```java
public class HelloWorldClient {
public static void main(String[] args) {
send();
}
private static void send() {
NioEventLoopGroup worker = new NioEventLoopGroup();
try {
Bootstrap bootstrap = new Bootstrap();
bootstrap.channel(NioSocketChannel.class);
bootstrap.group(worker);
bootstrap.handler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new ChannelInboundHandlerAdapter() {
// ã€åœ¨è¿žæŽ¥ channel 建立æˆåŠŸåŽï¼Œä¼šè§¦å‘ active 方法】
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
// å‘é€å†…容éšæœºçš„æ•°æ®åŒ…
Random r = new Random();
char c = '0';
ByteBuf buf = ctx.alloc().buffer();
for (int i = 0; i < 10; i++) {
byte[] bytes = new byte[10];
for (int j = 0; j < r.nextInt(9) + 1; j++) {
bytes[j] = (byte) c;
}
c++;
buf.writeBytes(bytes);
}
ctx.writeAndFlush(buf);
}
});
}
});
ChannelFuture channelFuture = bootstrap.connect("127.0.0.1", 8080).sync();
channelFuture.channel().closeFuture().sync();
} catch (InterruptedException e) {
log.error("client error", e);
} finally {
worker.shutdownGracefully();
}
}
}
```
* æœåŠ¡å™¨ä»£ç :
```java
public class HelloWorldServer {
public static void main(String[] args) {
NioEventLoopGroup boss = new NioEventLoopGroup(1);
NioEventLoopGroup worker = new NioEventLoopGroup();
try {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
// 调整系统的接å—缓冲区ã€æ»‘动窗å£ã€‘
//serverBootstrap.option(ChannelOption.SO_RCVBUF, 10);
// 调整 netty 的接å—缓冲区(ByteBuf)
//serverBootstrap.childOption(ChannelOption.RCVBUF_ALLOCATOR,
// new AdaptiveRecvByteBufAllocator(16, 16, 16));
serverBootstrap.group(boss, worker);
serverBootstrap.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
// ã€è¿™é‡Œå¯ä»¥æ·»åŠ 解ç 器】
// LoggingHandler 用æ¥æ‰“å°æ¶ˆæ¯
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
}
});
ChannelFuture channelFuture = serverBootstrap.bind(8080);
channelFuture.sync();
channelFuture.channel().closeFuture().sync();
} catch (InterruptedException e) {
log.error("server error", e);
} finally {
boss.shutdownGracefully();
worker.shutdownGracefully();
log.debug("stop");
}
}
}
```
* 粘包效果展示:
```java
09:57:27.140 [nioEventLoopGroup-3-1] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0xddbaaef6, L:/127.0.0.1:8080 - R:/127.0.0.1:8701] READ: 100B // 读了 100 å—节,å‘生粘包
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 30 30 30 30 30 00 00 00 00 00 31 00 00 00 00 00 |00000.....1.....|
|00000010| 00 00 00 00 32 32 32 32 00 00 00 00 00 00 33 00 |....2222......3.|
|00000020| 00 00 00 00 00 00 00 00 34 34 00 00 00 00 00 00 |........44......|
|00000030| 00 00 35 35 35 35 00 00 00 00 00 00 36 36 36 00 |..5555......666.|
|00000040| 00 00 00 00 00 00 37 37 37 37 00 00 00 00 00 00 |......7777......|
|00000050| 38 38 38 38 38 00 00 00 00 00 39 39 00 00 00 00 |88888.....99....|
|00000060| 00 00 00 00 |.... |
+--------+-------------------------------------------------+----------------+
```
解决方法:通过调整系统的接å—缓冲区的滑动窗å£å’Œ Netty 的接å—缓冲区ä¿è¯æ¯æ¡åŒ…åªå«æœ‰ä¸€æ¡æ•°æ®ï¼Œæ»‘动窗å£çš„大å°ä»…决定了 Netty 读å–çš„**最å°å•ä½**,实际æ¯æ¬¡è¯»å–的一般是它的整数å€
***
### 解决方案
#### çŸè¿žæŽ¥
å‘ä¸€ä¸ªåŒ…å»ºç«‹ä¸€æ¬¡è¿žæŽ¥ï¼Œè¿™æ ·è¿žæŽ¥å»ºç«‹åˆ°è¿žæŽ¥æ–开之间就是消æ¯çš„边界,缺点就是效率很低
客户端代ç æ”¹é€ ï¼š
```java
public class HelloWorldClient {
public static void main(String[] args) {
// 分 10 次å‘é€
for (int i = 0; i < 10; i++) {
send();
}
}
}
```
****
#### 固定长度
æœåŠ¡å™¨ç«¯åŠ 入定长解ç 器,æ¯ä¸€æ¡æ¶ˆæ¯é‡‡ç”¨å›ºå®šé•¿åº¦ã€‚如果是åŠåŒ…消æ¯ï¼Œä¼šç¼“å˜åŠåŒ…消æ¯å¹¶ç‰å¾…下个包到达之åŽè¿›è¡Œæ‹¼åŒ…åˆå¹¶ï¼Œç›´åˆ°è¯»å–一个完整的消æ¯åŒ…;如果是粘包消æ¯ï¼Œç©ºä½™çš„ä½ç½®ä¼šè¿›è¡Œè¡¥ 0,会浪费空间
```java
serverBootstrap.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new FixedLengthFrameDecoder(10));
// LoggingHandler 用æ¥æ‰“å°æ¶ˆæ¯
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
}
});
```
```java
10:29:06.522 [nioEventLoopGroup-3-1] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0x38a70fbf, L:/127.0.0.1:8080 - R:/127.0.0.1:10144] READ: 10B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 31 31 00 00 00 00 00 00 00 00 |11........ |
+--------+-------------------------------------------------+----------------+
10:29:06.522 [nioEventLoopGroup-3-1] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0x38a70fbf, L:/127.0.0.1:8080 - R:/127.0.0.1:10144] READ: 10B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 32 32 32 32 32 32 00 00 00 00 |222222.... |
+--------+-------------------------------------------------+----------------+
```
****
#### 分隔符
æœåŠ¡ç«¯åŠ 入行解ç 器,默认以 `\n` 或 `\r\n` 作为分隔符,如果超出指定长度ä»æœªå‡ºçŽ°åˆ†éš”符,则抛出异常:
```java
serverBootstrap.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new FixedLengthFrameDecoder(8));
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
}
});
```
客户端在æ¯æ¡æ¶ˆæ¯ä¹‹åŽï¼ŒåŠ å…¥ `\n` 分隔符:
```java
public void channelActive(ChannelHandlerContext ctx) throws Exception {
Random r = new Random();
char c = 'a';
ByteBuf buffer = ctx.alloc().buffer();
for (int i = 0; i < 10; i++) {
for (int j = 1; j <= r.nextInt(16)+1; j++) {
buffer.writeByte((byte) c);
}
// 10 代表 '\n'
buffer.writeByte(10);
c++;
}
ctx.writeAndFlush(buffer);
}
```
****
#### 预设长度
LengthFieldBasedFrameDecoder 解ç 器自定义长度解决 TCP 粘包é»åŒ…问题
```java
int maxFrameLength // æ•°æ®æœ€å¤§é•¿åº¦
int lengthFieldOffset // 长度å—段å移é‡ï¼Œä»Žç¬¬å‡ 个å—节开始是内容的长度å—段
int lengthFieldLength // 长度å—段本身的长度
int lengthAdjustment // 长度å—æ®µä¸ºåŸºå‡†ï¼Œå‡ ä¸ªå—节åŽæ‰æ˜¯å†…容
int initialBytesToStrip // ä»Žå¤´å¼€å§‹å‰¥ç¦»å‡ ä¸ªå—节解ç åŽæ˜¾ç¤º
```
```java
lengthFieldOffset = 1 (= the length of HDR1)
lengthFieldLength = 2
lengthAdjustment = 1 (= the length of HDR2)
initialBytesToStrip = 3 (= the length of HDR1 + LEN)
BEFORE DECODE (16 bytes) AFTER DECODE (13 bytes)//解ç
+------+--------+------+----------------+ +------+----------------+
| HDR1 | Length | HDR2 | Actual Content |----->| HDR2 | Actual Content |
| 0xCA | 0x000C | 0xFE | "HELLO, WORLD" | | 0xFE | "HELLO, WORLD" |
+------+--------+------+----------------+ +------+----------------+
```
代ç 实现:
```java
public class LengthFieldDecoderDemo {
public static void main(String[] args) {
EmbeddedChannel channel = new EmbeddedChannel(
// int å 4 å—节,版本å·ä¸€ä¸ªå—节
new LengthFieldBasedFrameDecoder(1024, 0, 4, 1,5),
new LoggingHandler(LogLevel.DEBUG)
);
// 4 个å—节的内容长度, 实际内容
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();
send(buffer, "Hello, world");
send(buffer, "Hi!");
// 写出缓å˜
channel.writeInbound(buffer);
}
// 写入缓å˜
private static void send(ByteBuf buffer, String content) {
byte[] bytes = content.getBytes(); // 实际内容
int length = bytes.length; // 实际内容长度
buffer.writeInt(length);
buffer.writeByte(1); // 表示版本å·
buffer.writeBytes(bytes);
}
}
```
```java
10:49:59.344 [main] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0xembedded, L:embedded - R:embedded] READ: 12B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 65 6c 6c 6f 2c 20 77 6f 72 6c 64 |Hello, world |
+--------+-------------------------------------------------+----------------+
10:49:59.344 [main] DEBUG io.netty.handler.logging.LoggingHandler - [id: 0xembedded, L:embedded - R:embedded] READ: 3B
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 48 69 21 |Hi! |
+--------+-------------------------------------------------+----------------+
```
****
### å议设计
#### HTTP
访问 URL:http://localhost:8080/
```java
public class HttpDemo {
public static void main(String[] args) {
NioEventLoopGroup boss = new NioEventLoopGroup();
NioEventLoopGroup worker = new NioEventLoopGroup();
try {
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.group(boss, worker);
serverBootstrap.childHandler(new ChannelInitializer() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG));
ch.pipeline().addLast(new HttpServerCodec());
// åªé’ˆå¯¹æŸä¸€ç§ç±»åž‹çš„请求处ç†ï¼Œæ¤å¤„针对 HttpRequest
ch.pipeline().addLast(new SimpleChannelInboundHandler() {
@Override
protected void channelRead0(ChannelHandlerContext ctx, HttpRequest msg) throws Exception {
// 获å–请求
log.debug(msg.uri());
// 返回å“应
DefaultFullHttpResponse response = new DefaultFullHttpResponse(
msg.protocolVersion(), HttpResponseStatus.OK);
byte[] bytes = "Hello, world!
".getBytes();
response.headers().setInt(CONTENT_LENGTH, bytes.length);
response.content().writeBytes(bytes);
// 写回å“应
ctx.writeAndFlush(response);
}
});
}
});
ChannelFuture channelFuture = serverBootstrap.bind(8080).sync();
channelFuture.channel().closeFuture().sync();
} catch (InterruptedException e) {
log.error("n3.server error", e);
} finally {
boss.shutdownGracefully();
worker.shutdownGracefully();
}
}
}
```
***
#### 自定义
处ç†å™¨ä»£ç :
```java
@Slf4j
public class MessageCodec extends ByteToMessageCodec {
// ç¼–ç
@Override
public void encode(ChannelHandlerContext ctx, Message msg, ByteBuf out) throws Exception {
// 4 å—节的é”æ•°
out.writeBytes(new byte[]{1, 2, 3, 4});
// 1 å—节的版本,
out.writeByte(1);
// 1 å—节的åºåˆ—åŒ–æ–¹å¼ jdk 0 , json 1
out.writeByte(0);
// 1 å—节的指令类型
out.writeByte(msg.getMessageType());
// 4 个å—节
out.writeInt(msg.getSequenceId());
// æ— æ„义,对é½å¡«å……, 1 å—节
out.writeByte(0xff);
// 获å–内容的å—节数组,msg 对象åºåˆ—化
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(msg);
byte[] bytes = bos.toByteArray();
// 长度
out.writeInt(bytes.length);
// 写入内容
out.writeBytes(bytes);
}
// 解ç
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List