| title | pandas用法总结 | ||
|---|---|---|---|
| date |
|
||
| tags |
|
||
| categories |
|
- 读取csv文件
data_path= "C:\\Users\\lenovo\\Desktop\\ml-100k\\"
header = ['user_id', 'item_id', 'rating', 'timestamp']
df = pd.read_csv(u_data_path+'ml-100k/u.data', sep='\t', names=header)-
series
-
Dataframe
2.1 增
- 按列增加
citys = ['ny','zz','xy'] df.insert(0,'city',citys) #在第0列,加上column名称为city,值为citys的数值。 df['city']=citys
-
按行增加
df.loc[4] = ['zz','mason','m',24,'engineer’]修改index=4的值 df.append(df_insert,ignore_index=True)
2.2 删
-
删除列
df.drop(['name'],axis = 1,inplace = False) *#删除name列。* -
删除行
df.drop([1,3], axis = 0,inplace=False) #删除index值为1,3的两行
2.3 改
- 使用loc
df.loc[1,'name'] = 'aa' #修改index为‘1’,column为‘name’的那一个值为aa。 df.loc[1] = ['bb','ff',11] #修改index为‘1’的那一行的所有值。 df.loc[1,['name','age']] = ['bb',11] #修改index为‘1’,column为‘name’的那一个值为bb,age列的值为11。使用iloc[row_index, column_index]:
- 使用iloc
df.iloc[1,2] = 19#修改某一无素 df.iloc[:,2] = [11,22,33] #修改一整列 df.iloc[0,:] = ['lily','F',15] #修改一整行
2.4、查
- df['column_name'] 和df[row_start_index, row_end_index]
df['name'] df['gender'] df[['name','gender']] #选取多列,多列名字要放在list里 df[0:] #第0行及之后的行,相当于df的全部数据,注意冒号是必须的 df[:2] #第2行之前的数据(不含第2行) df[0:1] #第0行 df[1:3] #第1行到第2行(不含第3行) df[-1:] #最后一行 df[-3:-1] #倒数第3行到倒数第1行(不包含最后1行即倒数第1行,这里有点烦躁,因为从前数时从第0行开始,从后数就是-1行开始,毕竟没有-0)
- df.loc[index,column]
# df.loc[index, column_name],选取指定行和列的数据 df.loc[0,'name'] # 'Snow' df.loc[0:2, ['name','age']] #选取第0行到第2行,name列和age列的数据, 注意这里的行选取是包含下标的。 df.loc[[2,3],['name','age']] #选取指定的第2行和第3行,name和age列的数据 df.loc[df['gender']=='M','name'] #选取gender列是M,name列的数据 df.loc[df['gender']=='M',['name','age']] #选取gender列是M,name和age列的数据
- iloc[row_index, column_index]
df.iloc[0,0] #第0行第0列的数据,'Snow' df.iloc[1,2] #第1行第2列的数据,32 df.iloc[[1,3],0:2] #第1行和第3行,从第0列到第2列(不包含第2列)的数据
- 去重
unique()
num_users = df['userId'].unique() 返回值类型:<class 'numpy.ndarray'>
透视表是一种可以对数据动态排布并且分类汇总的表格格式。在pandas中它被称作pivot_table。
pivot_table(data, values=None, index=None, columns=None,aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
pivot_table有四个最重要的参数*index、values、columns、aggfunc*
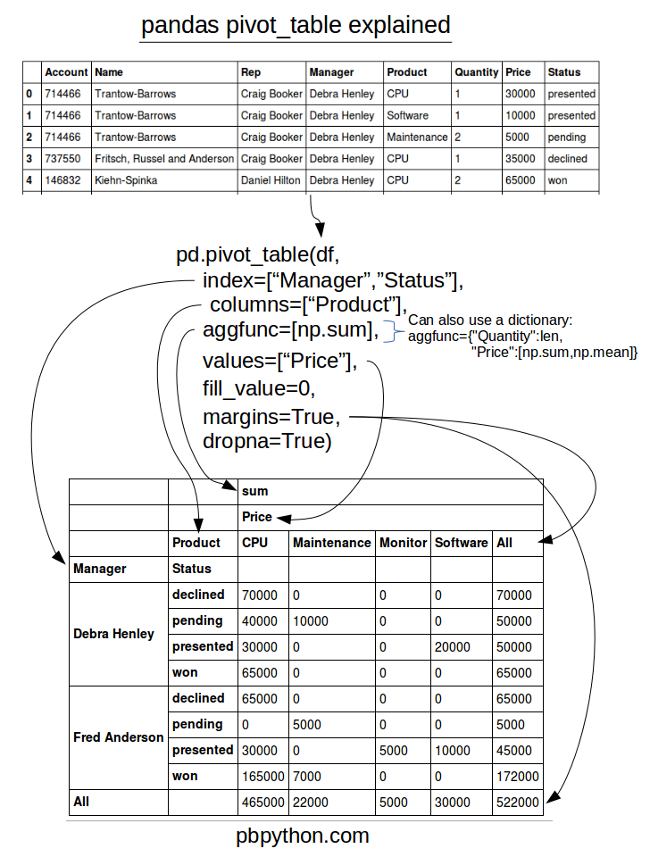
- Index
set_index:将DataFrame的某一列作为index
df.set_index(["Column"], inplace=True)