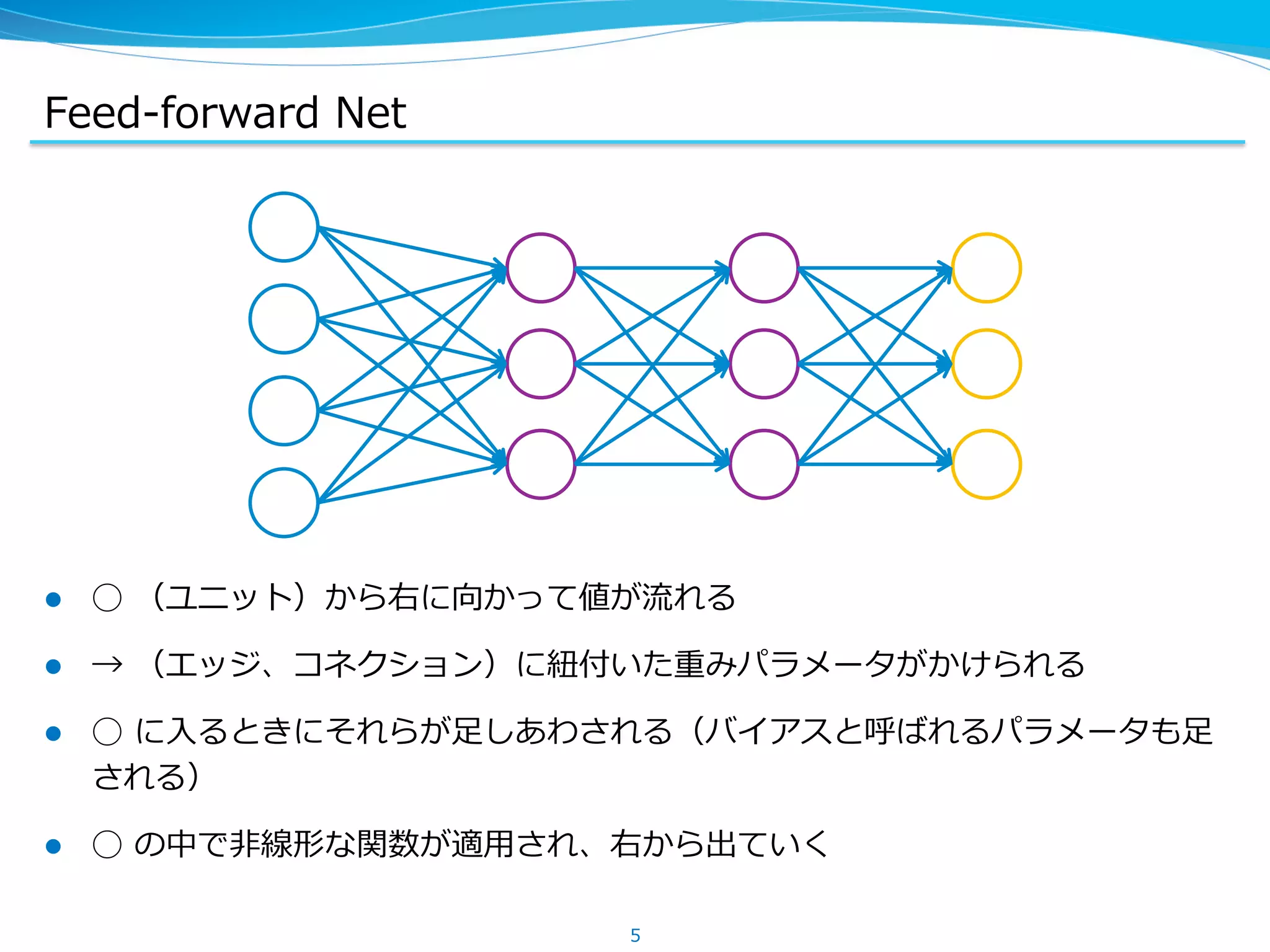
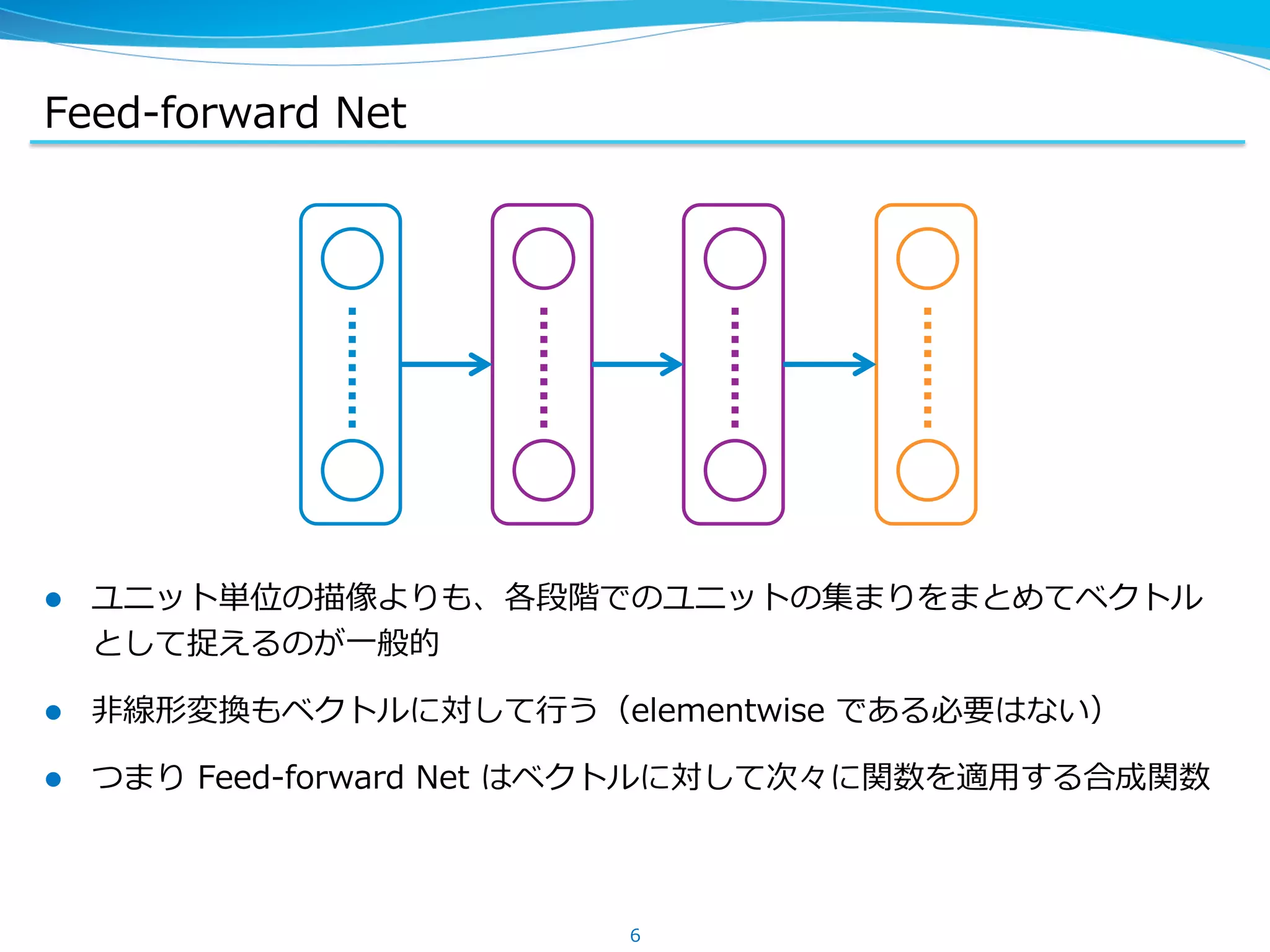
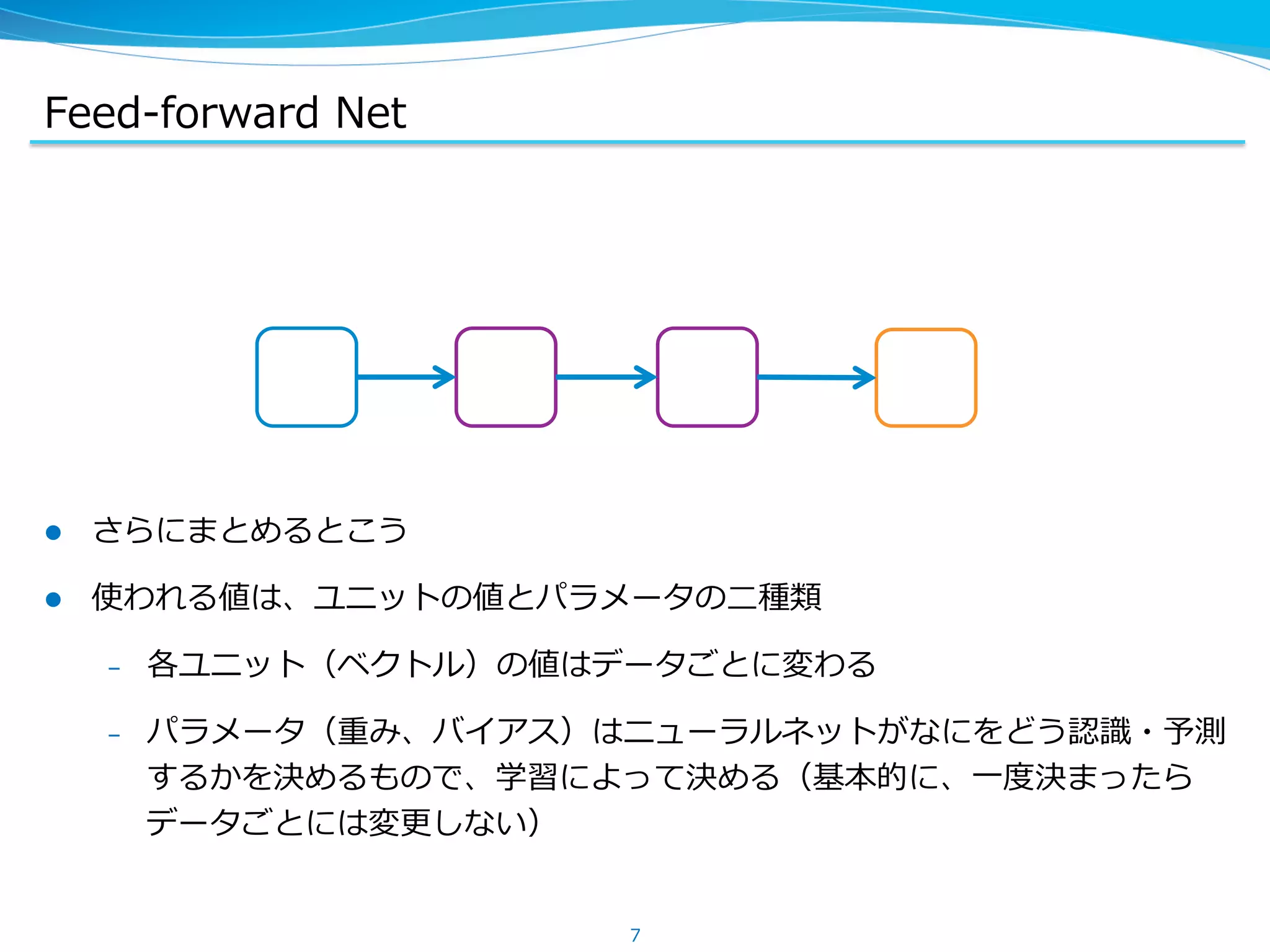
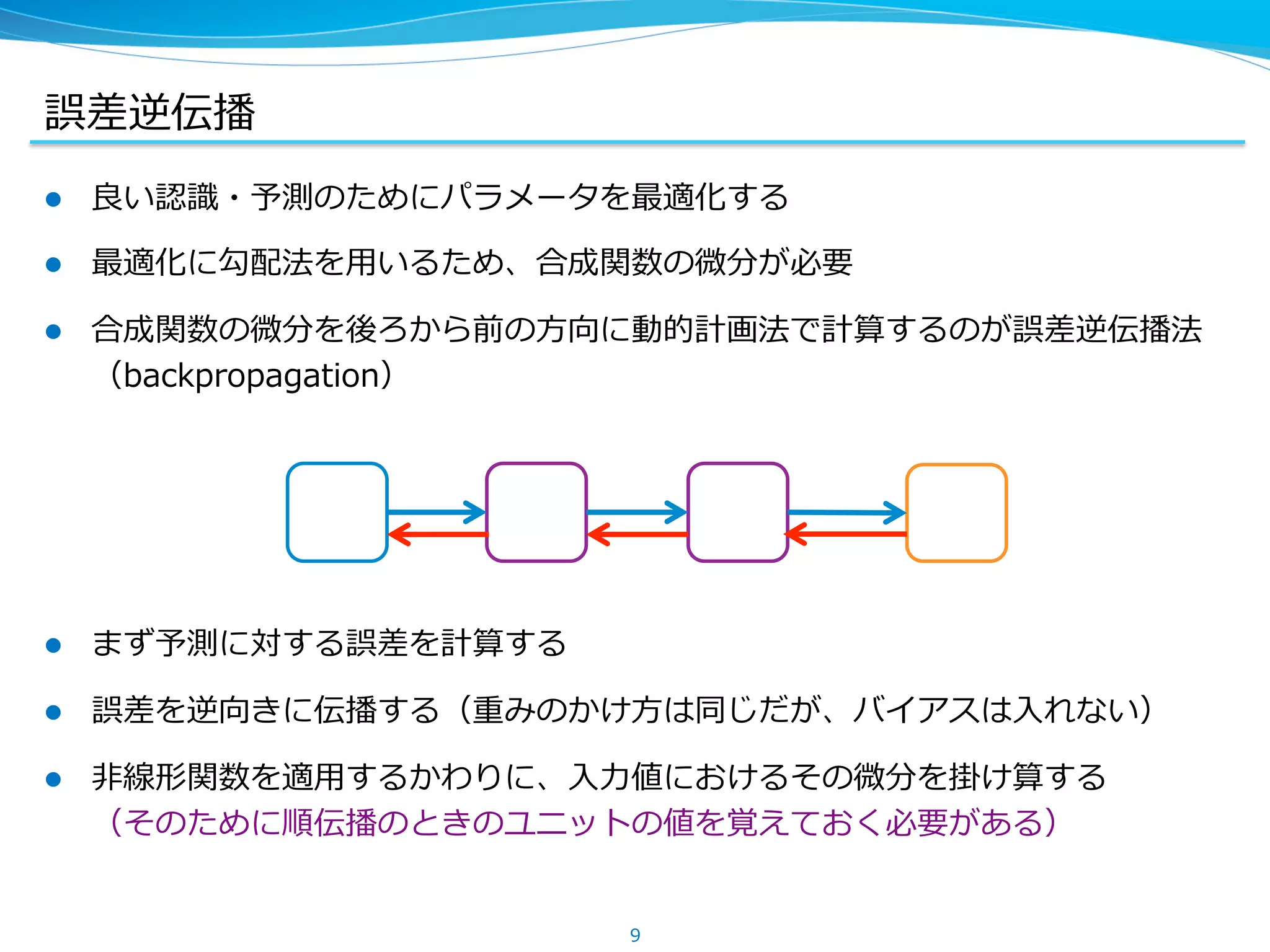
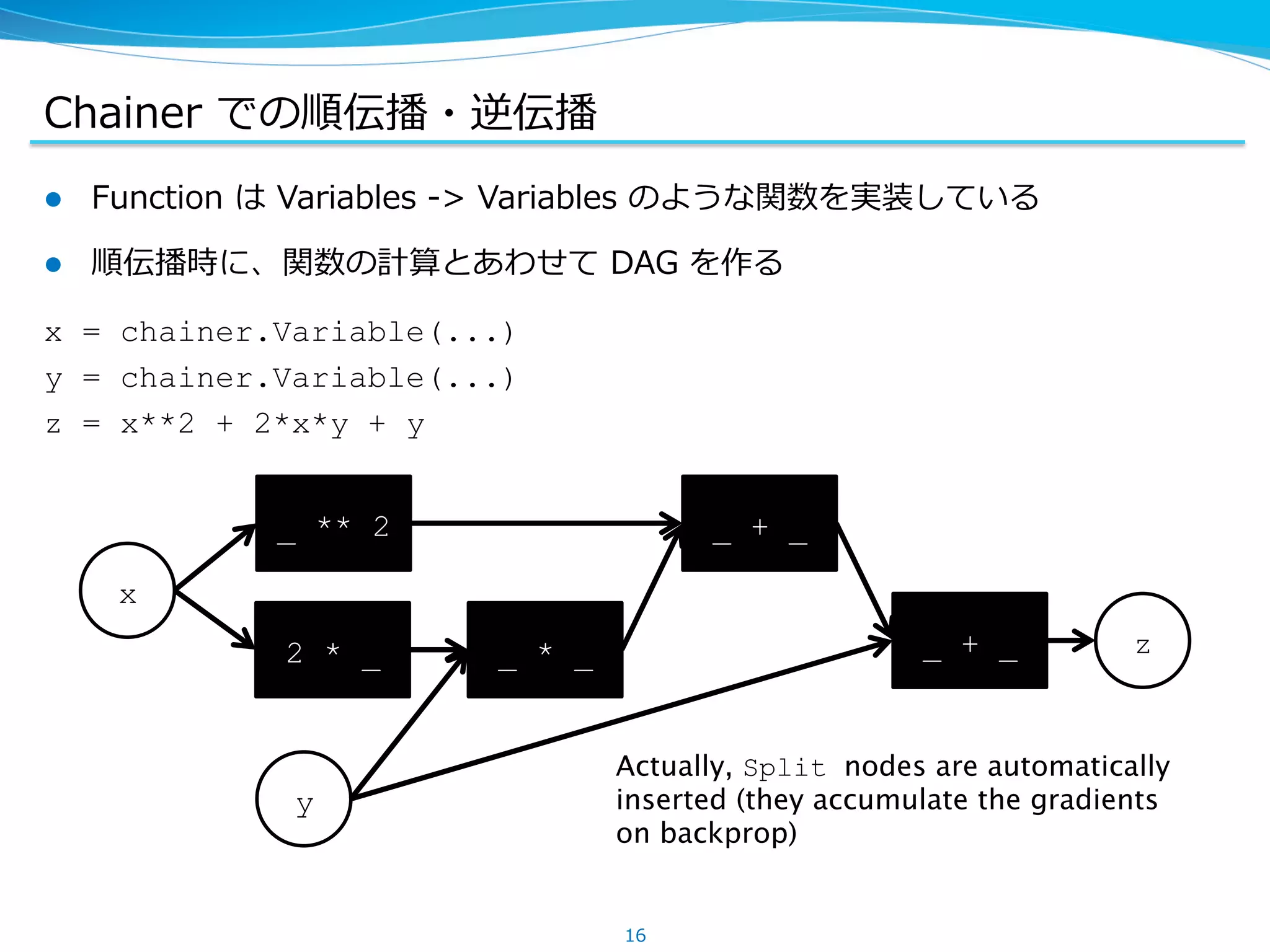
Chainer での順伝播・逆伝播
l Function は Variables -‐‑‒> Variables のような関数を実装している
l 順伝播時に、関数の計算とあわせて DAG を作る
x = chainer.Variable(...)
y = chainer.Variable(...)
z = x**2 + 2*x*y + y
16
x
y
_ ** 2
2 * _ _ * _ _ + _ z
_ + _
Actually, Split nodes are automatically
inserted (they accumulate the gradients
on backprop)
17.
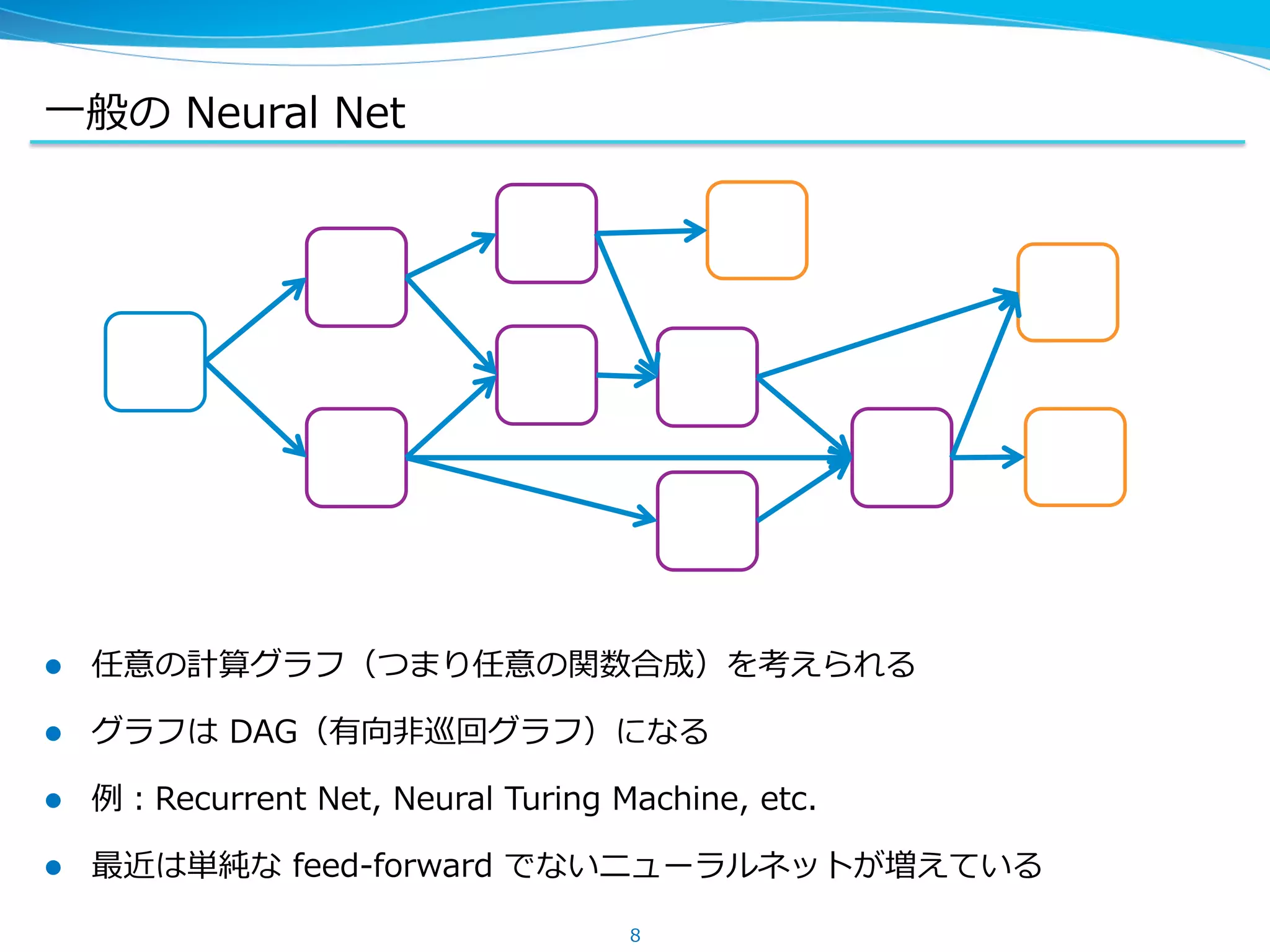
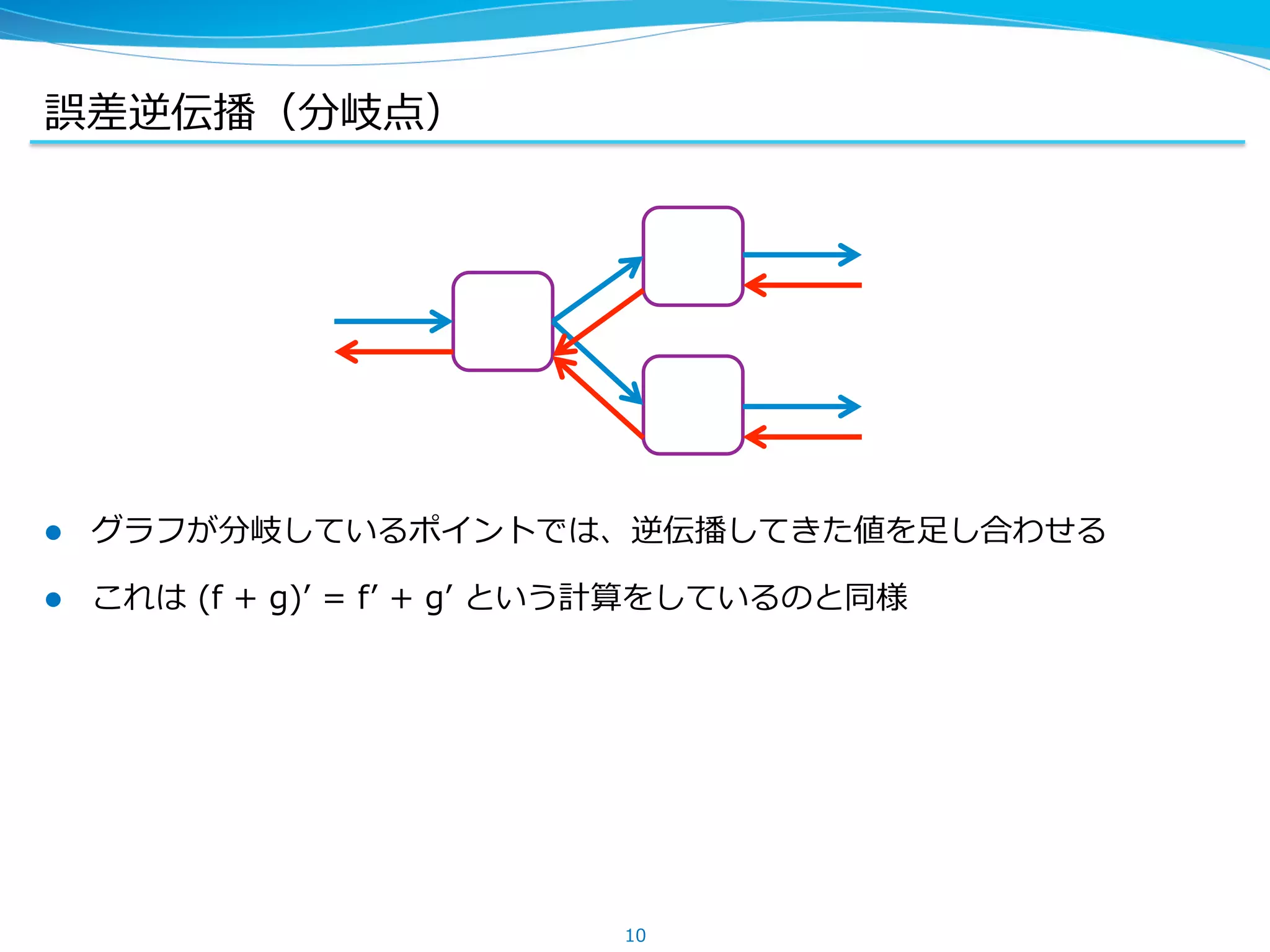
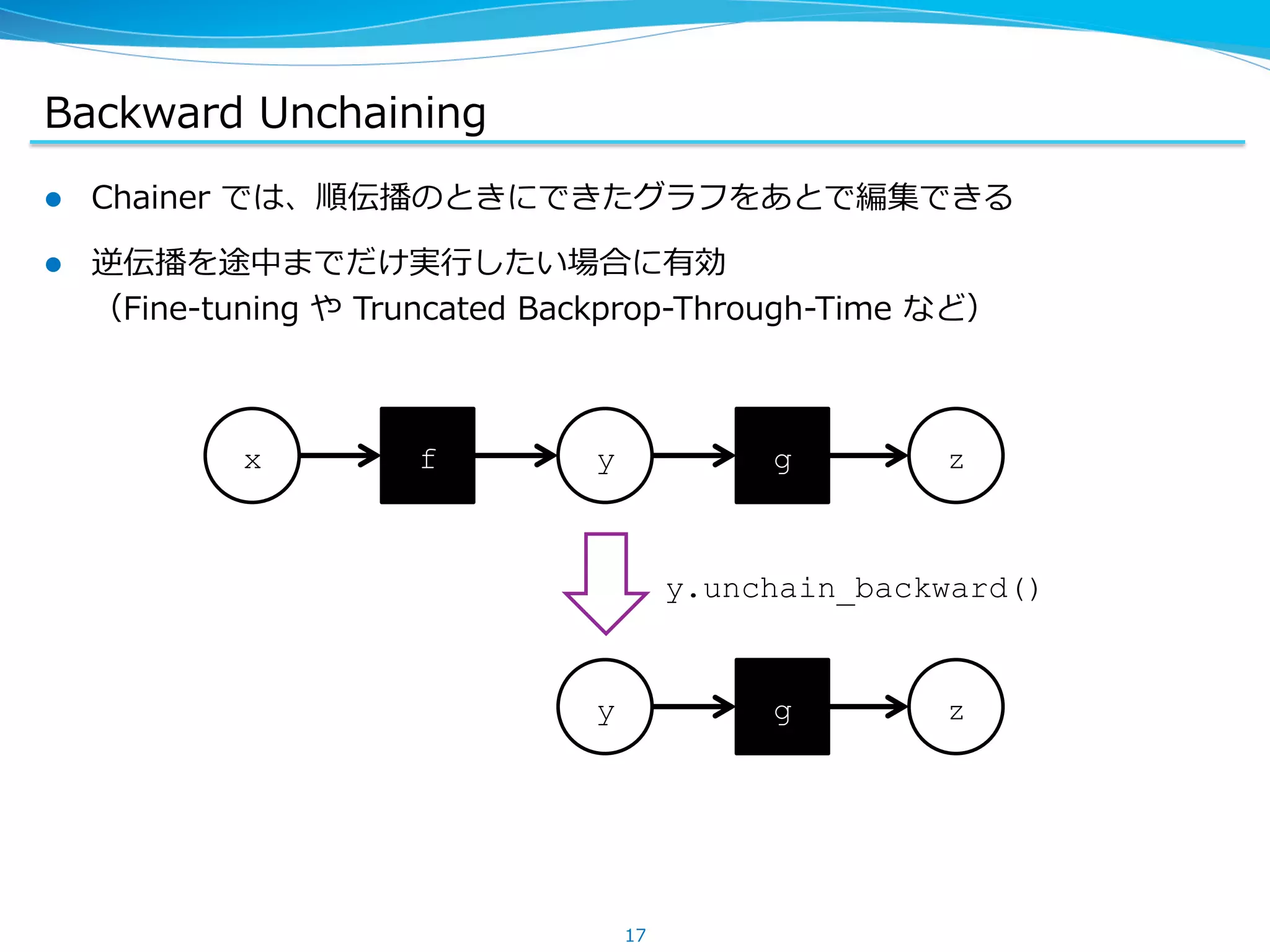
Backward Unchaining
l Chainer では、順伝播のときにできたグラフをあとで編集できる
l 逆伝播を途中までだけ実⾏行行したい場合に有効
(Fine-‐‑‒tuning や Truncated Backprop-‐‑‒Through-‐‑‒Time など)
17
x f y g z
y g z
y.unchain_backward()



















































![[GTCJ2018] Optimizing Deep Learning with Chainer PFN得居誠也](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018optimizingdeeplearningwithpfnseiyatokui-181009073509-thumbnail.jpg?width=640&height=640&fit=bounds)






![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)




















